
汉字检测、字母检测、手写数字检测、藏文检测、甲骨文检测在我之前的文章中都有做过了,今天主要是因为实际项目的需要,之前的汉字检测模型较为古老了还使用的yolov3时期的模型,检测精度和推理速度都有不小的滞后了,这里要基于yolov5轻量级的模型来开发构建新版的目标检测模型,首先看下效果图:

接下来简单看下数据集情况:

YOLO格式标注文件截图如下:
实例标注内容如下所示:
17 0.245192 0.617788 0.038462 0.038462
6 0.102163 0.830529 0.045673 0.045673
16 0.894231 0.096154 0.134615 0.134615
4 0.456731 0.524038 0.134615 0.134615
15 0.367788 0.317308 0.269231 0.269231
VOC格式数据标注文件截图如下:
实例标注内容如下所示:
<annotation>
<folder>DATASET</folder>
<filename>0ace8eaf-8e86-488b-9229-95255c69158c.jpg</filename>
<source>
<database>The DATASET Database</database>
<annotation>DATASET</annotation>
<image>DATASET</image>
</source>
<owner>
<name>YMGZS</name>
</owner>
<size>
<width>416</width>
<height>416</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>17</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>214</xmin>
<ymin>302</ymin>
<xmax>230</xmax>
<ymax>318</ymax>
</bndbox>
</object>
<object>
<name>16</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>210</xmin>
<ymin>67</ymin>
<xmax>229</xmax>
<ymax>86</ymax>
</bndbox>
</object>
<object>
<name>18</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>260</xmin>
<ymin>7</ymin>
<xmax>274</xmax>
<ymax>21</ymax>
</bndbox>
</object>
<object>
<name>10</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>121</xmin>
<ymin>103</ymin>
<xmax>143</xmax>
<ymax>125</ymax>
</bndbox>
</object>
<object>
<name>11</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>296</xmin>
<ymin>289</ymin>
<xmax>352</xmax>
<ymax>345</ymax>
</bndbox>
</object>
<object>
<name>0</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>56</xmin>
<ymin>132</ymin>
<xmax>196</xmax>
<ymax>272</ymax>
</bndbox>
</object>
<object>
<name>0</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>213</xmin>
<ymin>142</ymin>
<xmax>353</xmax>
<ymax>282</ymax>
</bndbox>
</object>
</annotation>
因为是主打轻量级网络,这里选择了也是最为轻量级的n系列的模型,最终训练得到的模型文件不足4MB大小,网络结构图如下所示:

默认100次epoch的计算,结果目录如下所示:
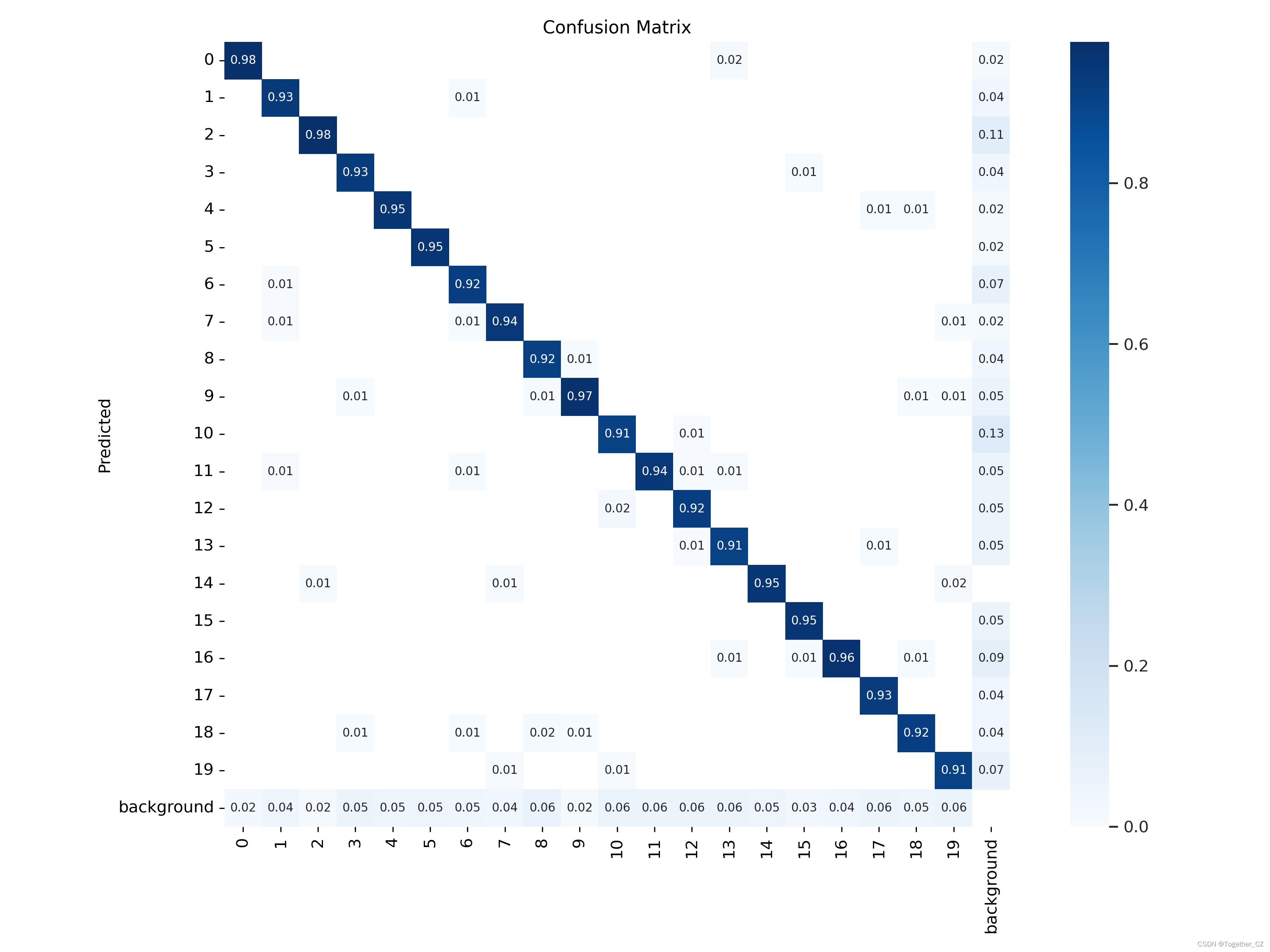
【混淆矩阵】
【F1值曲线】

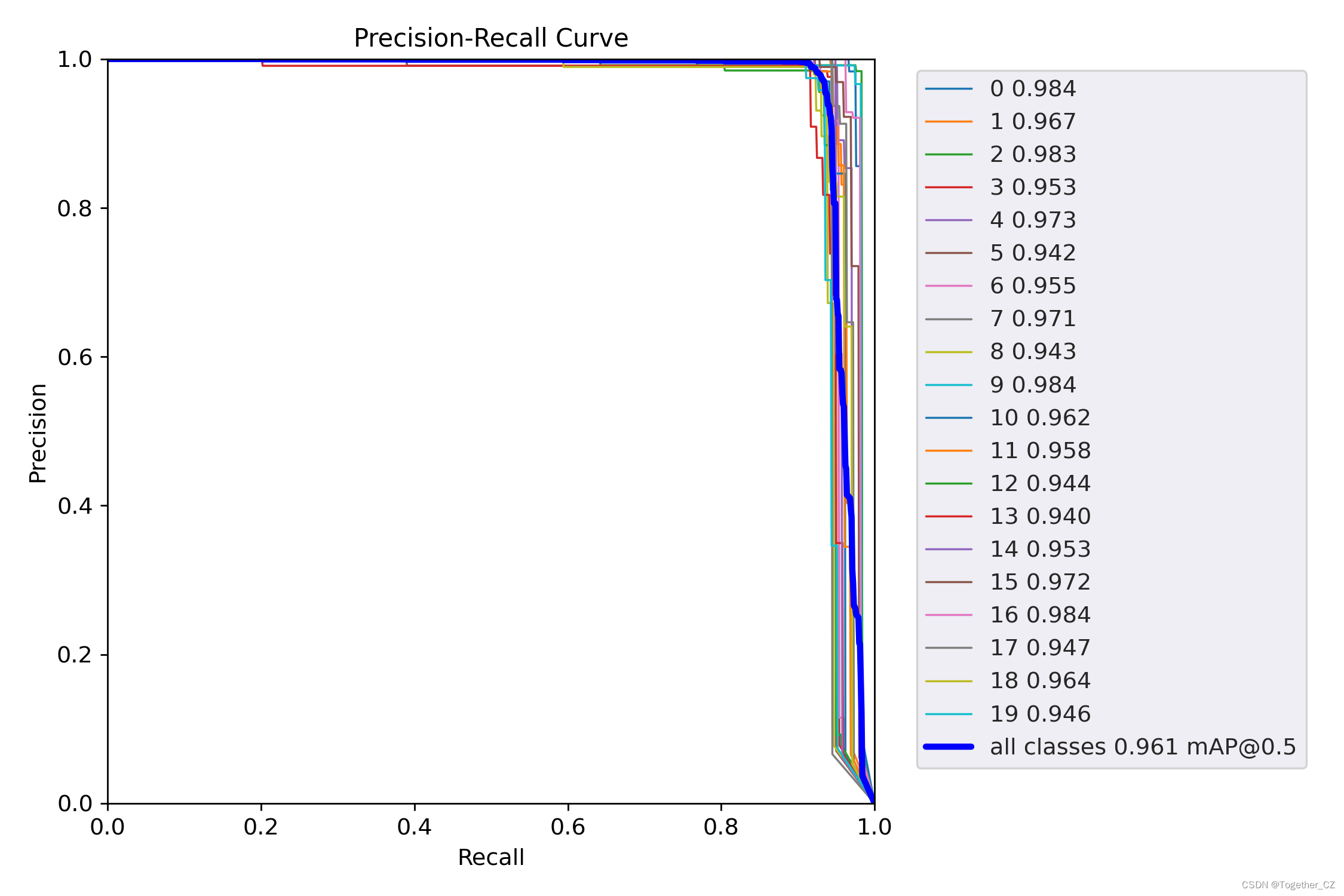
【PR曲线】
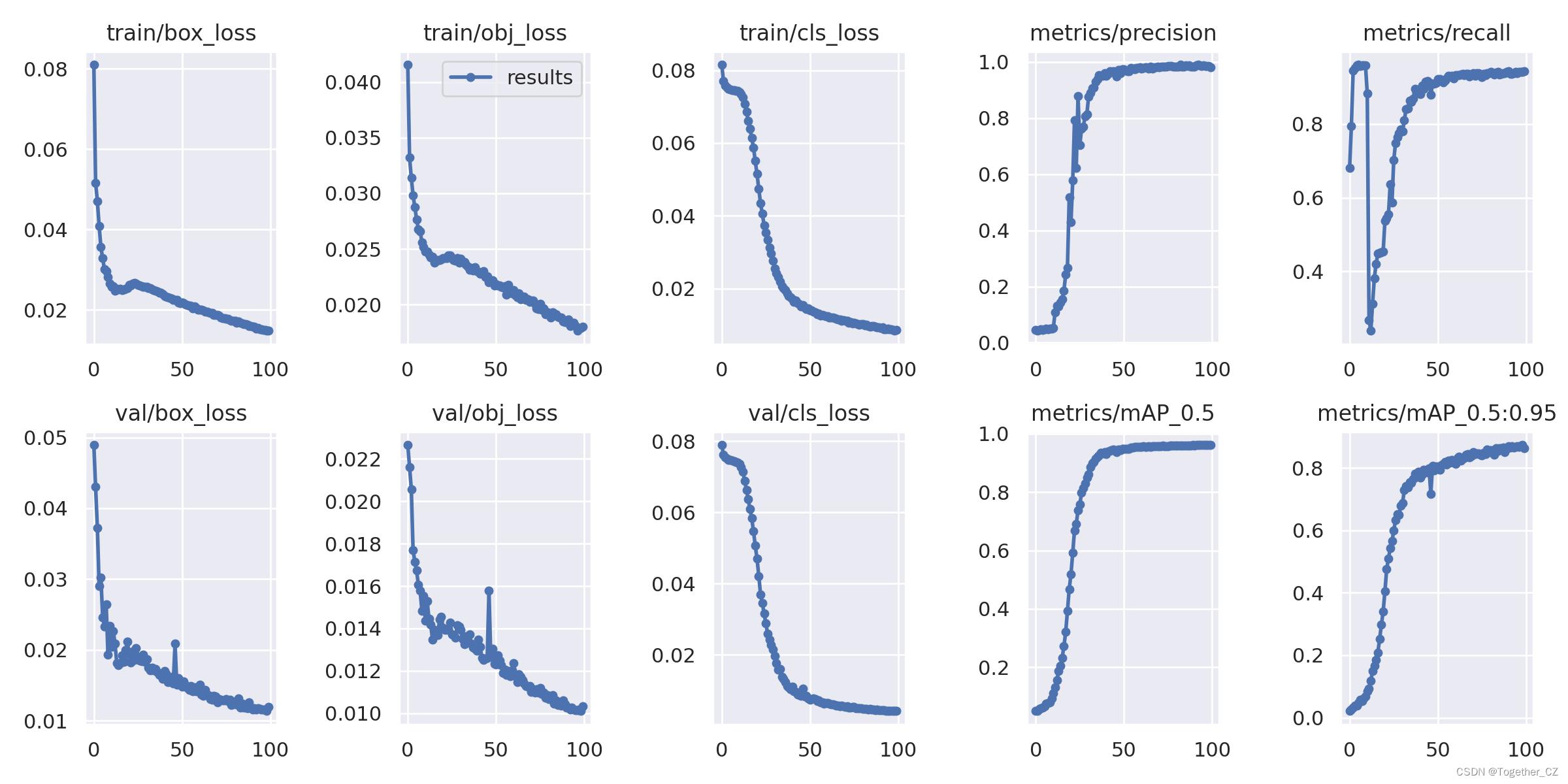
【训练日志可视化】
【batch计算实例】

可视化界面推理样例如下:



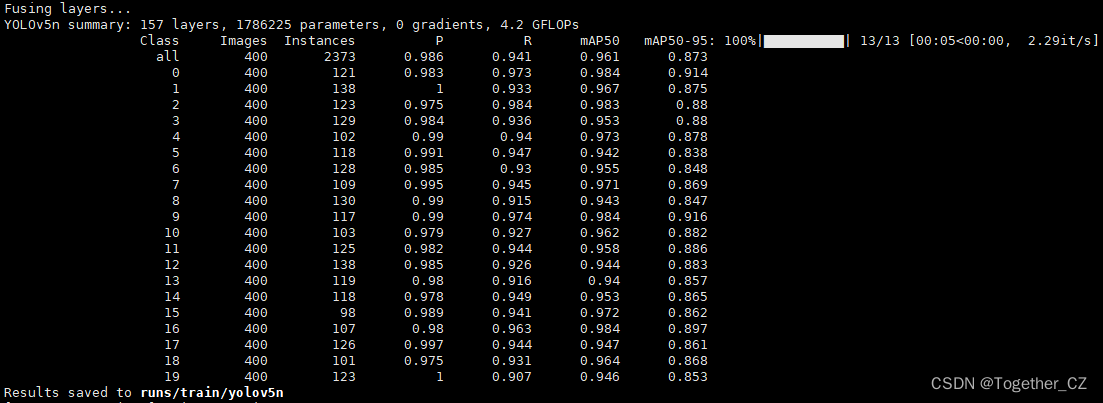
从评估指标结果上面来看检测效果还是很不错的。
本文转载自: https://blog.csdn.net/Together_CZ/article/details/129401399
版权归原作者 Together_CZ 所有, 如有侵权,请联系我们删除。
版权归原作者 Together_CZ 所有, 如有侵权,请联系我们删除。