
YOLOv5-7.0可以用来做实例分割的任务了!!!用完感觉实在是666啊
项目介绍
本文章主要目的有两个:
- 用yolov5分割网络训练自己的数据
- 处理yolov5的分割结果,将分割的图像裁剪出来
我的项目是需要识别图一里面这些小块,将每个小块裁剪出来,旋转成水平角度后再进行下一步的操作。因项目保密原因,就用模糊的图片代替,见谅见谅。下面展示了效果图,如果你的项目需要实现的功能跟我类似,可参考参考

图一

图二

图三
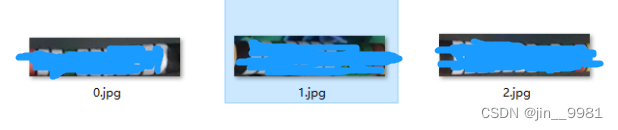
图四
图片说明:
- 图一是原图
- 图二是yolov5检测后的图片,它用其他颜色将目标的mask给标出来,并画出目标的最外矩形框
- 图三(后处理)是计算目标四个点坐标,并在原图上画出来
- 图四(后处理)是将目标旋转摆正并切分成小图
数据标注及处理
- 标注工具:labelme
- 标注文件:json格式
- 训练数据要求:坐标归一化的txt文件
从作者提供的样例数据coco128-seg(下载链接:https://ultralytics.com/assets/coco128-seg.zip),可以看到txt文件的内容,分别是类别下标,归一化的坐标,中间用空格分割,不同目标物体用换行符

json转换txt
如何将我们用labelme标注的json文件转化为对应的格式呢?
import json
import os
import argparse
from tqdm import tqdm
def convert_label_json(json_dir, save_dir, classes):
json_paths = os.listdir(json_dir)
classes = classes.split(',')
for json_path in tqdm(json_paths):
# for json_path in json_paths:
path = os.path.join(json_dir,json_path)
with open(path,'r') as load_f:
json_dict = json.load(load_f)
h, w = json_dict['imageHeight'], json_dict['imageWidth']
# save txt path
txt_path = os.path.join(save_dir, json_path.replace('json', 'txt'))
txt_file = open(txt_path, 'w')
for shape_dict in json_dict['shapes']:
label = shape_dict['label']
label_index = classes.index(label)
points = shape_dict['points']
points_nor_list = []
for point in points:
points_nor_list.append(point[0]/w)
points_nor_list.append(point[1]/h)
points_nor_list = list(map(lambda x:str(x),points_nor_list))
points_nor_str = ' '.join(points_nor_list)
label_str = str(label_index) + ' ' +points_nor_str + '\n'
txt_file.writelines(label_str)
if __name__ == "__main__":
"""
python json2txt_nomalize.py --json-dir my_datasets/color_rings/jsons --save-dir my_datasets/color_rings/txts --classes "cat,dogs"
"""
parser = argparse.ArgumentParser(description='json convert to txt params')
parser.add_argument('--json-dir', type=str, help='json path dir')
parser.add_argument('--save-dir', type=str, help='txt save dir')
parser.add_argument('--classes', type=str, help='classes')
args = parser.parse_args()
json_dir = args.json_dir
save_dir = args.save_dir
classes = args.classes
convert_label_json(json_dir, save_dir, classes)
脚本说明:
--json-dir:标注的纯json目录;
--save-dir:要保存的txt文件目录;
--classes:类别名称,它的类别顺序跟后面的配置文件顺序相同,如类别cat,dog,执行命令可以这么写
python json2txt_nomalize.py --json-dir my_datasets/color_rings/jsons --save-dir my_datasets/color_rings/txts --classes "cat,dog"
切分训练集、测试集、验证集
# 将图片和标注数据按比例切分为 训练集和测试集
import shutil
import random
import os
import argparse
# 检查文件夹是否存在
def mkdir(path):
if not os.path.exists(path):
os.makedirs(path)
def main(image_dir, txt_dir, save_dir):
# 创建文件夹
mkdir(save_dir)
images_dir = os.path.join(save_dir, 'images')
labels_dir = os.path.join(save_dir, 'labels')
img_train_path = os.path.join(images_dir, 'train')
img_test_path = os.path.join(images_dir, 'test')
img_val_path = os.path.join(images_dir, 'val')
label_train_path = os.path.join(labels_dir, 'train')
label_test_path = os.path.join(labels_dir, 'test')
label_val_path = os.path.join(labels_dir, 'val')
mkdir(images_dir);mkdir(labels_dir);mkdir(img_train_path);mkdir(img_test_path);mkdir(img_val_path);mkdir(label_train_path);mkdir(label_test_path);mkdir(label_val_path);
# 数据集划分比例,训练集75%,验证集15%,测试集15%,按需修改
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
total_txt = os.listdir(txt_dir)
num_txt = len(total_txt)
list_all_txt = range(num_txt) # 范围 range(0, num)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# 在全部数据集中取出train
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{},测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = os.path.join(image_dir, name+'.jpg')
srcLabel = os.path.join(txt_dir, name + '.txt')
if i in train:
dst_train_Image = os.path.join(img_train_path, name + '.jpg')
dst_train_Label = os.path.join(label_train_path, name + '.txt')
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
elif i in val:
dst_val_Image = os.path.join(img_val_path, name + '.jpg')
dst_val_Label = os.path.join(label_val_path, name + '.txt')
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
else:
dst_test_Image = os.path.join(img_test_path, name + '.jpg')
dst_test_Label = os.path.join(label_test_path, name + '.txt')
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
if __name__ == '__main__':
"""
python split_datasets.py --image-dir my_datasets/color_rings/imgs --txt-dir my_datasets/color_rings/txts --save-dir my_datasets/color_rings/train_data
"""
parser = argparse.ArgumentParser(description='split datasets to train,val,test params')
parser.add_argument('--image-dir', type=str, help='image path dir')
parser.add_argument('--txt-dir', type=str, help='txt path dir')
parser.add_argument('--save-dir', type=str, help='save dir')
args = parser.parse_args()
image_dir = args.image_dir
txt_dir = args.txt_dir
save_dir = args.save_dir
main(image_dir, txt_dir, save_dir)
脚本说明:
--image-dir:训练图片目录;
--txt-dir:上一步生成txt的目录;
--save-dir:切分数据集存放路径,执行命令样例:
python split_datasets.py --image-dir my_datasets/color_rings/imgs --txt-dir my_datasets/color_rings/txts --save-dir my_datasets/color_rings/train_data
执行后在存放路径可以看到,自动生成images和labels两个文件夹,两个文件夹里面有三个文件夹:train\test\val
修改配置文件
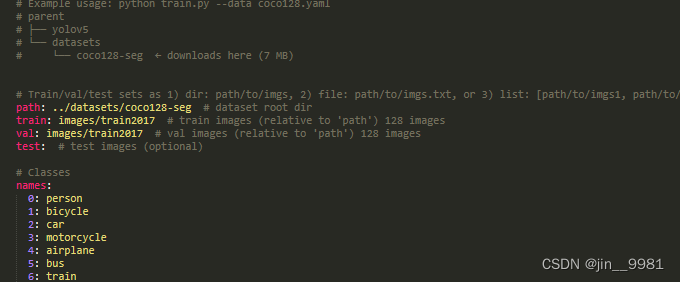
1、data文件夹里面有yaml文件,下面图片是data/coco128-seg.yaml的内容。
path:是上面--save-dir切分图片存放的路径;
train、val、test分别对于images里面的文件夹,按实际填入;
names:是类别名称和赋予的下标,跟上面转txt顺序相同
2、models/segment文件夹也有yaml文件,如果你使用yolov5m模型,就修改yolov5m-seg.yaml文件的nc,如果有两个类别,nc就修改成2
模型训练和推理
1、训练执行命令
python segment/train.py --epochs 300 --data coco128-seg.yaml --weights yolov5m-seg.pt --img 640 --cfg models/segment/yolov5m-seg.yaml --batch-size 16 --device 2
执行命令说明:指明配置文件、预训练权重路径等,具体参数查看train.py文件
结果:在runs目录生成train-seg文件,每一次训练都会生成对应的权重文件
2、模型推理
python segment/predict.py --weight ./runs/train-seg/exp2/weights/best.pt --source ./my_datasets/color_rings/train_data/images/test/000030.jpg
执行命令说明:指明权重路径和预测的图片或者文件夹,具体参数查看predict.py文件
结果:在runs目录生成predict-seg目录,保存了上面图二的结果图
后处理
重要的后处理来了!!!
segment/predict.py,约169行附近,将预测坐标保存在txt文件。打印segments的维度,他是一个list,如果预测的图片中有6个目标,那么list包含了6个子元素,每个元素都是多个坐标点构成,坐标点是目标预测出来的轮廓坐标值

后处理需要做的步骤有:
- 坐标反归一化:segments的坐标和txt的格式相同,都是归一化的坐标值,需要转换为图片真实的坐标值
- 获取四个点:多个坐标点计算出左上、右上、左下、右下的点,并将他们按顺时针的顺序输出
- 旋转摆正:已知四个点,可计算得出角度,将目标摆正后保存成小图
代码献出
# segments是分割的坐标点
segments = [
scale_segments(im0.shape if retina_masks else im.shape[2:], x, im0.shape, normalize=True)
for x in reversed(masks2segments(masks))]
new_segments = [] # 用来装反归一化后的坐标
image_list = [] # 切割的小图
im0_h, im0_w, im0_c = im0.shape
for k, seg_list in enumerate(segments):
# 将归一化的点转换为坐标点
new_seg_list = []
for s_point in seg_list:
pt1, pt2 = s_point
new_pt1 = int(pt1 * im0_w)
new_pt2 = int(pt2 * im0_h)
new_seg_list.append([new_pt1, new_pt2])
rect = cv2.minAreaRect(np.array(new_seg_list)) # 得到最小外接矩形的(中心(x,y), (宽,高), 旋转角度)
seg_bbox = cv2.boxPoints(rect) # 获取最小外接矩形的4个顶点坐标(ps: cv2.boxPoints(rect) for OpenCV 3.x)
seg_bbox = np.int0(seg_bbox)
if np.linalg.norm(seg_bbox[0] - seg_bbox[1]) < 5 or np.linalg.norm(seg_bbox[3] - seg_bbox[0]) < 5:
continue
# 坐标点排序
box1 = sorted(seg_bbox, key=lambda x: (x[1], x[0]))
# 将坐标点按照顺时针方向来排序,box的从左往右从上到下排序
if box1[0][0] > box1[1][0]:
box1[0], box1[1] = box1[1], box1[0]
if box1[2][0] < box1[3][0]:
box1[2], box1[3] = box1[3], box1[2]
if box1[0][1] > box1[1][1]:
box1[0], box1[1], box1[2], box1[3] = box1[1], box1[2], box1[3], box1[0]
box1_list = [b.tolist() for b in box1] # 坐标转换为list格式
new_segments.append(box1_list)
tmp_box = copy.deepcopy(np.array(box1)).astype(np.float32)
partImg_array = image_crop_tools.get_rotate_crop_image(im0, tmp_box)
image_list.append(partImg_array)
# cv2.imwrite(str(k)+'.jpg', partImg_array) # 保存小图
# 在原图上画出分割图像
# src_image = im0.copy()
# for ns_box in new_segments:
# cv2.drawContours(src_image, [np.array(ns_box)], -1, (0, 255, 0), 2)
# cv2.imwrite('1.jpg', src_image)
代码说明:该部分脚本复制在segment/predict.py文件,可以放在if save_txt的同一级别下面。其中注释#保存小图,是保存文章开头图四的图片。注释#在原图上画出分割图像,是文章开头图三的图像。
旋转部分用到了image_crop_tools.get_rotate_crop_image函数,主要用来做角度计算和图片摆正,代码如下:
import cv2
import numpy as np
def get_rotate_crop_image(img, points):
"""
根据坐标点截取图像
:param img:
:param points:
:return:
"""
h, w, _ = img.shape
left = int(np.min(points[:, 0]))
right = int(np.max(points[:, 0]))
top = int(np.min(points[:, 1]))
bottom = int(np.max(points[:, 1]))
img_crop = img[top:bottom, left:right, :].copy()
points[:, 0] = points[:, 0] - left
points[:, 1] = points[:, 1] - top
img_crop_width = int(np.linalg.norm(points[0] - points[1]))
img_crop_height = int(np.linalg.norm(points[0] - points[3]))
pts_std = np.float32([[0, 0], [img_crop_width, 0], [img_crop_width, img_crop_height], [0, img_crop_height]])
M = cv2.getPerspectiveTransform(points, pts_std)
dst_img = cv2.warpPerspective(
img_crop,
M, (img_crop_width, img_crop_height),
borderMode=cv2.BORDER_REPLICATE)
dst_img_height, dst_img_width = dst_img.shape[0:2]
if dst_img_height * 1.0 / dst_img_width >= 1:
# pass
# print(dst_img_height * 1.0 / dst_img_width,dst_img_height,dst_img_width,'*-'*10)
dst_img = np.rot90(dst_img,-1) #-1为逆时针,1为顺时针。
return dst_img
def sorted_boxes(dt_boxes):
"""
坐标点排序
"""
num_boxes = dt_boxes.shape[0]
sorted_boxes = sorted(dt_boxes, key=lambda x: (x[0][1], x[0][0]))
_boxes = list(sorted_boxes)
for i in range(num_boxes - 1):
if abs(_boxes[i+1][0][1] - _boxes[i][0][1]) < 10 and \
(_boxes[i + 1][0][0] < _boxes[i][0][0]):
tmp = _boxes[i]
_boxes[i] = _boxes[i + 1]
_boxes[i + 1] = tmp
return _boxes
撒花完结!!!
版权归原作者 jin__9981 所有, 如有侵权,请联系我们删除。