
OpenCV是一个基于(开源)发行的跨平台计算机视觉库,能实现图像处理和计算机视觉方面的很多通用算法。车位识别的图像处理过程如图所示。
在python中设置完所有内容后, 最重要的依赖关系将是OpenCV库。通过pip将其添加到虚拟环境中,可以运行
pip install opencv-python。
要检查所有设置是否正确,我们可以使用以下cv2.__version__命令打印环境中可用的当前OpenCV版本。


首先处理旋转矩形
从图中可以看到,由于视频拍摄角度的问题,车位不是横平竖直的,并且车位在屏幕上的大小和角度也是不相同的。需要用到旋转矩形的操作,并调整单个矩形框使其能够用于所有车位。
假设对图片上任意点(
x
,
y
x,y
x,y),绕一个坐标点(
r
x
0
,
r
y
0
r_{x0},r_{y0}
rx0,ry0)顺时针旋转a角度后的新的坐标设为
(
x
0
,
y
0
)
(x_0, y_0)
(x0,y0),则有公式:
x
0
=
(
x
−
r
x
0
)
c
o
s
a
−
(
y
−
r
y
0
)
s
i
n
a
+
r
x
0
x_0=(x-r_{x_0})cosa-(y-r_{y_0})sina+r_{x_0}
x0=(x−rx0)cosa−(y−ry0)sina+rx0
y
0
=
(
x
−
r
x
0
)
s
i
n
a
+
(
y
−
r
y
0
)
c
o
s
a
+
r
y
0
,
y_0=(x-r_{x_0})sina+(y-r_{y_0})cosa+r_{y_0},
y0=(x−rx0)sina+(y−ry0)cosa+ry0,
根据此公式,创建函数完成矩阵旋转操作。
下面是实现的代码:
# 矩形框顺时针旋转
import cv2
import math
# 传入旋转的参考点坐标,矩形框左上角坐标(x,y),框的宽w和高h,旋转角度a
def angleRota(center_x, center_y, x, y, w, h, a):
# 角度转弧度
a = (math.pi / 180) * a
# 旋转前左上角坐标
x1, y1 = x, y
# 右上角坐标
x2, y2 = x + w, y
# 右下角坐标
x3, y3 = x + w, y + h
# 左下角坐标
x4, y4 = x, y + h
# 旋转后的左上角坐标,像素坐标是整数
px1 = int((x1 - center_x) * math.cos(a) - (y1 - center_y) * math.sin(a) + center_x)
py1 = int((x1 - center_x) * math.sin(a) + (y1 - center_y) * math.cos(a) + center_y)
# 右上角坐标
px2 = int((x2 - center_x) * math.cos(a) - (y2 - center_y) * math.sin(a) + center_x)
py2 = int((x2 - center_x) * math.sin(a) + (y2 - center_y) * math.cos(a) + center_y)
# 右下角坐标
px3 = int((x3 - center_x) * math.cos(a) - (y3 - center_y) * math.sin(a) + center_x)
py3 = int((x3 - center_x) * math.sin(a) + (y3 - center_y) * math.cos(a) + center_y)
# 左下角坐标
px4 = int((x4 - center_x) * math.cos(a) - (y4 - center_y) * math.sin(a) + center_x)
py4 = int((x4 - center_x) * math.sin(a) + (y4 - center_y) * math.cos(a) + center_y)
# 保存每一个角的坐标
pt1 = (px1, py1)
pt2 = (px2, py2)
pt3 = (px3, py3)
pt4 = (px4, py4)
# 存储每个角的坐标
angle = [pt1, pt2, pt3, pt4]
# 返回调整后的坐标
return angle
# 绘制旋转后的矩形框
def drawLine(img, angle, color, thickness):
# 分别绘制四条边
cv2.line(img, angle[0], angle[1], color, thickness)
cv2.line(img, angle[1], angle[2], color, thickness)
cv2.line(img, angle[2], angle[3], color, thickness)
cv2.line(img, angle[3], angle[0], color, thickness)
# 返回绘制好旋转矩形的图像
return img
# 矩形旋转
def recRota(img, center_x, center_y, x1, y1, w, h, rota, draw=True):
'''
img: 原图像
(center_X, center_y): 旋转参考点的坐标
(x1, y1): 矩形框左上角坐标
w: 矩形框的宽
h: 矩形框的高
rota: 顺时针的旋转角度,如:30°
'''
color = (255, 255, 0) # 绘制停车线的线条颜色
thickness = 2 # 停车线线条宽度
# (1)计算旋转一定角度后的四个角的坐标
angle = angleRota(x1, y1, x1, y1, w, h, rota)
# (2)绘制旋转后的矩形
if draw == True:
img = drawLine(img, angle, color, thickness)
# 返回绘制后的图像,以及矩形框的四个角的坐标
return img, angle
else:
return angle
处理单帧图像,划分车位
绘制后的单帧图像如图所示

import cv2
video = cv2.VideoCapture('./input.mp4')
ret, cap = video.read()
cv2.imwrite('./first.jpg', cap)
处理视频,分割出所有车位
在对单帧图像处理时,已将所有车位分割出来,并记录下左上角坐标。由于每个车位框是倾斜的,如果要分割出每个车位,必须使用切片方法,但切片出来的图像是横平竖直的。因此针对每一个车位框,都以该框的左上角为旋转参考,旋转整张帧图像,将车位框摆正之后再进行切片。
下面是实现的代码:
# w, h = 90, 160 # 矩形框的宽和高
# w, h = 70, 130
w, h = 90, 160
# 遍历所有的矩形框坐标
for pos in posList:
# 得到旋转后的矩形的四个角坐标,传入原图,旋转参考点坐标,矩形框左上角坐标,框的宽w和高h,逆时针转4°
angle = recRota(imgDilate, pos[0], pos[1], pos[0], pos[1], w, h, -5, draw=False) # 裁剪的车位不绘制车位图
# (5)裁剪所有的车位框,由于我们的矩形是倾斜的,先要把矩形转正之后再裁剪
# 变换矩阵,以每个矩形框的左上坐标为参考点,顺时针寻转4°,旋转后的图像大小不变
rota_params = cv2.getRotationMatrix2D(angle[0], angle=-4, scale=1)
# 旋转整张帧图片,输入img图像,变换矩阵,指定输出图像大小
rota_img = cv2.warpAffine(imgDilate, rota_params, (img_w, img_h))
# 裁剪摆正了的矩形框,先指定高h,再指定宽w
imgCrop = rota_img[pos[1]:pos[1] + h, pos[0]:pos[0] + w]
# 显示裁剪出的图像
cv2.imshow('imgCrop', imgCrop)
处理像素点
处理像素点是车位识别的难点,对于采集到的24位真彩色位图图像文件所需存储量大,图像需要占用大量系统资源,不利于图像的快速处理。
灰度图只包含亮度信息,不含彩色信息,有利于图像的处理,故在对图像进行处理前应先将其转化为灰度图。
由于在拍摄过程中,受各种主客观因素的影响,我们获得的车辆图像和实际的需要存在某种程度的差异,如果差异过大,会造成图像分割和识别的困难,严重时甚至会使分割和识别根本无法进行。为此,本文采取一些图像增强方法来综合处理。
(1)二值化方法
图像的二值化是最简单的图像处理技术,一般都跟具体算法联系,本技术中对滤波后的灰度图转换为二值图,采用自适应阈值方法。
(2)中值滤波
中值滤波是一种局部平均平滑技术,在一定条件下,中值滤波可以克服线性滤波器所带来的图像细节模糊,而且对滤除脉冲干扰及颗粒噪声最为有效。
(3)膨胀
膨胀操作就是将图像(或图像的一部分区域,称之为A)与核(称之为B)进行卷积。核可以是任何形状和大小,它拥有一个单独定义出来的参考点,我们称其为锚点。
代码实现如下:
while True:
# 记录有几个空车位
spacePark = 0
# 返回图像是否读取成功,以及读取的帧图像img
success, img = cap.read()
if img is None:
break
# 为了使裁剪后的单个车位里面没有绘制的边框,需要在画车位框之前,把原图像复制一份
imgCopy = img.copy()
# 获得整每帧图片的宽和高
img_w, img_h = img.shape[:2] # shape是(w,h,c)
# ==1== 转换灰度图,通过形态学处理来检测车位内有没有车
imgGray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# ==2== 高斯滤波,卷积核3*3,沿x和y方向的卷积核的标准差为1
imgGray = cv2.GaussianBlur(imgGray, (3, 3), 1)
# ==3== 二值图,自适应阈值方法
imgThresh = cv2.adaptiveThreshold(imgGray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY_INV, 101, 20)
# ==4== 删除零散的白点,
# 如果车位上有车,那么车位上的像素数量(白点)很多,如果没有车,车位框内基本没什么白点
imgMedian = cv2.medianBlur(imgThresh, 5)
# ==5== 扩张白色部分,膨胀
kernel = np.ones((3, 3), np.uint8) # 设置卷积核
imgDilate = cv2.dilate(imgMedian, kernel, iterations=1) # 迭代次数为1
# 由于这个视频比较短,就循环播放这个视频
if cap.get(cv2.CAP_PROP_POS_FRAMES) == cap.get(cv2.CAP_PROP_FRAME_COUNT):
# 如果当前帧==总帧数,那就重置当前帧为0
cap.set(cv2.CAP_PROP_POS_FRAMES, 0)
三种方法处理后的图像分别如图所示。


车位检测
我们的检测思路是:通过计算每个车位框内的像素个数来判断该车位内是否有车。经过上述处理后,我们计算每个分割出来的车位框中的白点个数,返回灰度值不为0的像素数量。经过分析,如果白点数量大于1800,那么就表明车位上有车。
代码实现如下:
count = cv2.countNonZero(imgCrop)
# 将计数显示在矩形框上
cv2.putText(imgCopy, str(count), (pos[0] + 5, pos[1] + 20), cv2.FONT_HERSHEY_COMPLEX, 0.8, (0, 255, 255), 2)
# (7)确定车位上是否有车
if count < 3000: # 像素数量小于3000辆就是没有车
color = (0, 255, 0) # 没有车的话车位线就是绿色
spacePark += 1 # 每检测到一个空车位,数量就加一
else:
color = (0, 0, 255) # 有车时车位线就是红色
最后我们的检测结果如图所示。
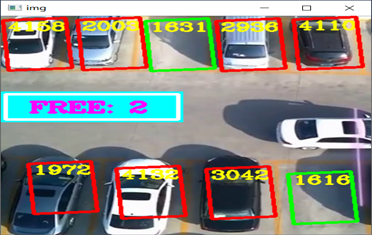
现在,我们就构建好了一个停车场车位识别的系统!
版权归原作者 AI阿远学长 所有, 如有侵权,请联系我们删除。