
这个系列快结束了,后面会有一到两篇文章介绍,如何用AI实实在在的应用在工业生产研发,如何指导化工分子合成,如何做DNA的研究预测,合成。
背景
最近chatpdf在各媒体传的风风火火,从效果上是很震撼的。原因大概分析有三:
1.pdf在大家印象中是一种保存性文档,很不容易做二次数据处理
2.可以对pdf中内容做问答,还可以顺带做翻译,做长文章的摘要观点生成
3.可以找到某个观点出现在哪
但其实如果是做nlp的同学又稍微熟悉办公自动化的同学,应该知道上面几点都不难。
1.pdf其实是可以想word一样的方便操作的。
2.文章摘要有难度,但是chatgpt对知识整理能力是可以的,调api就好
3.把自动化能力+chatgpt做个整合就可以实现
复现
python如何读取pdf
用python读取并处理pdf文件,把文件保存成csv,按文本内容、行、页数。用PyPDF2抽取pdf数据,把每行内容、页数、行数用pandas存成cvs,具体操作如下,结果如右。
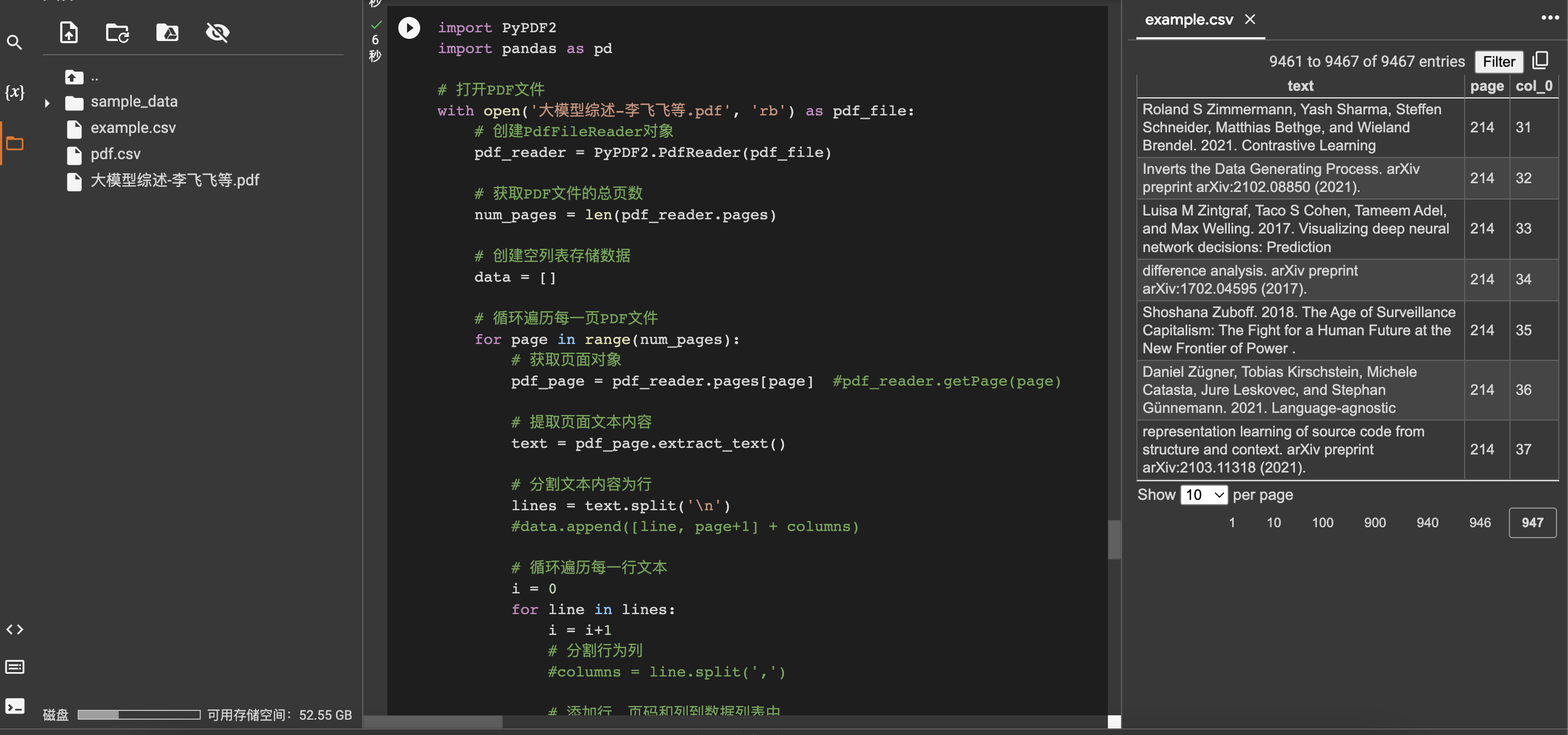
代码如下:
import PyPDF2
import pandas as pd
# 打开PDF文件
with open('大模型综述-李飞飞等.pdf', 'rb') as pdf_file:
# 创建PdfFileReader对象
pdf_reader = PyPDF2.PdfReader(pdf_file)
# 获取PDF文件的总页数
num_pages = len(pdf_reader.pages)
# 创建空列表存储数据
data = []
# 循环遍历每一页PDF文件
for page in range(num_pages):
# 获取页面对象
pdf_page = pdf_reader.pages[page] #pdf_reader.getPage(page)
# 提取页面文本内容
text = pdf_page.extract_text()
# 分割文本内容为行
lines = text.split('\n')
#data.append([line, page+1] + columns)
# 循环遍历每一行文本
i = 0
for line in lines:
i = i+1
# 分割行为列
#columns = line.split(',')
# 添加行、页码和列到数据列表中
data.append([line, page+1, i])
# 将数据列表转换为Pandas DataFrame对象
df = pd.DataFrame(data, columns=['text', 'page'] + [f'col_{i}' for i in range(len(data[0])-2)])
# 将DataFrame对象保存为CSV文件
df.to_csv('example.csv', index=False)
pdf信息如何送给chatgpt
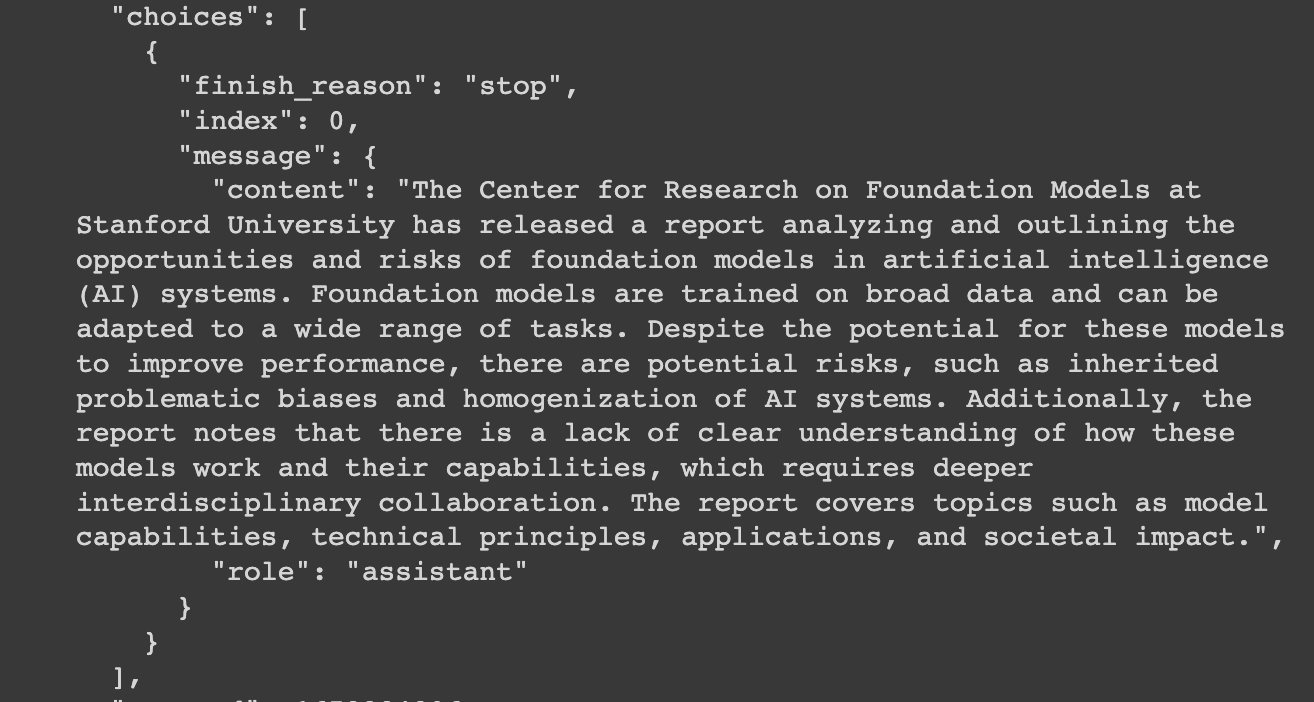
如何抽取摘要
将论文输入到ChatGPT中,让模型生成摘要。可以使用以下代码将论文输入到ChatGPT中,并让模型生成摘要:
#每次prompt有限制,可以分批输入,要抽取的好,有些拼接技巧,各位看官自己动动脑动动手试试
import openai
openai.api_key = "你的apitoken"
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Please generate a summary of the given article: {}\n\n ARTICLE TEXT HERE".format(' '.join(df['text'][0:200]))}
]
)
效果如下:
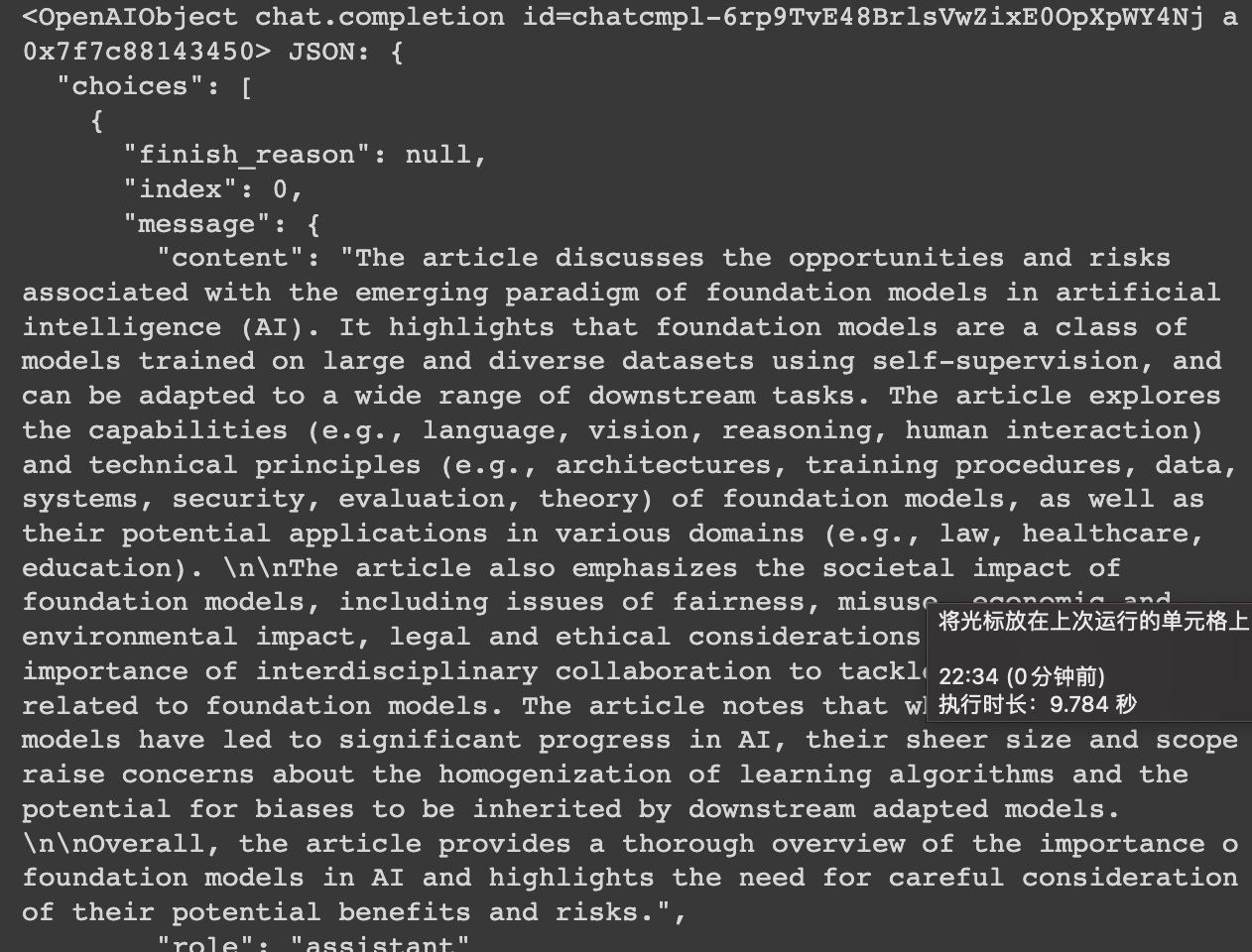
如何提问找到原文
代码如下:
import openai
openai.api_key = "你的api token"
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Please analyze the given article {article} and list the key {key} topics discussed: \n\n ARTICLE TEXT HERE".format(article =' '.join(df['text'][0:200]),key = 'where ia content?')
}
]
)
效果如下:
行号和页数,因为我没把前面处理好存在csv里的数据带上,所以没显示,这个各位看官可以自己动试试效果,不难。
如何翻译
import openai
openai.api_key = "你的api token"
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "把输入的英文{article} 翻译成中文 : \n\n ARTICLE TEXT HERE".format(article =' '.join(df['text'][0:20]))
}
]
)
结果如下:
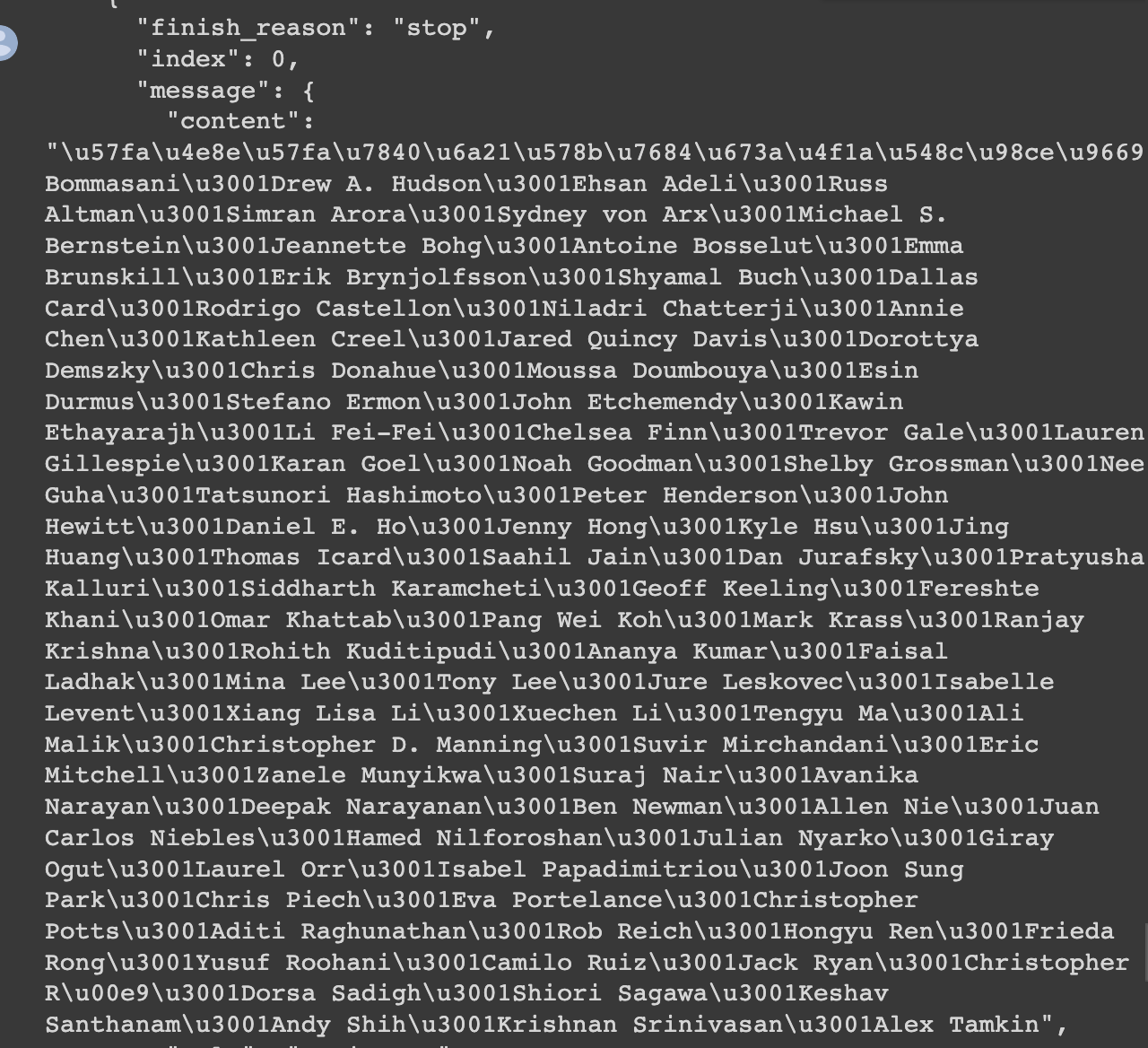
utf-8转成中文
本文转载自: https://blog.csdn.net/liangwqi/article/details/129413721
版权归原作者 远洋之帆 所有, 如有侵权,请联系我们删除。
版权归原作者 远洋之帆 所有, 如有侵权,请联系我们删除。