
文章目录
前言
在初学深度学习的时候,很多数据集直接使用dataset里的API接口直接调用的。虽然接口用起来十分方便,但是我却始终没有明白这些图像数据调用的具体步骤。尤其是直接给你几万张照片,你如何将其汇总成合格的数据集?这就是我今天要研究的内容
一、datasets.ImageFolder
1.1.路径书写
datasets.ImageFolder函数算是用的最多的一个函数了:
首先我们看看它的介绍: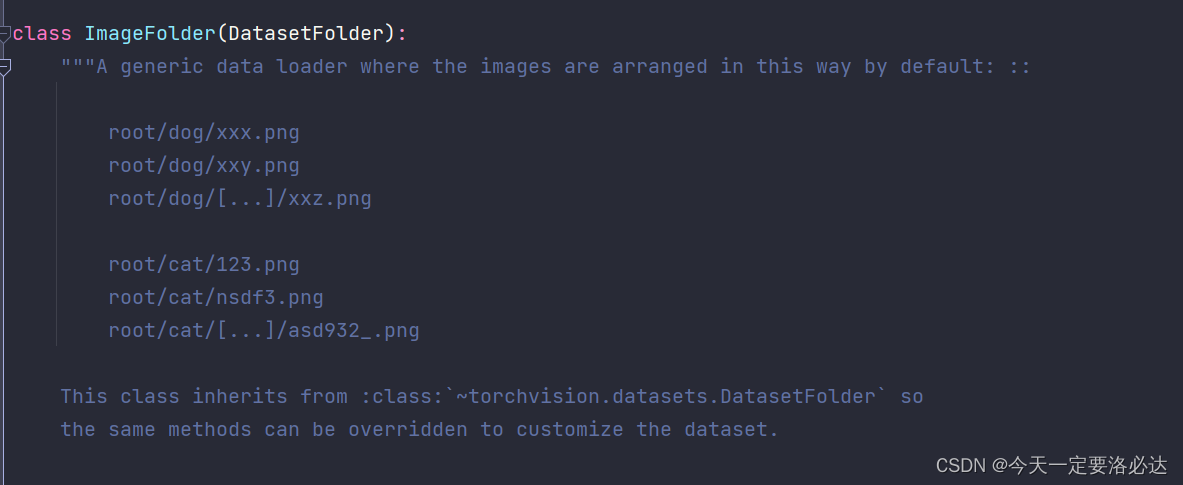
从上面可以得到的信息:
1)每个类别需要单独成立一个文件夹
2)每个类别里面的图片需要按顺序排列(无论使用英语还是数字)
举个例子,以我前几天看的猫狗分类为例,我的文件夹构造如下: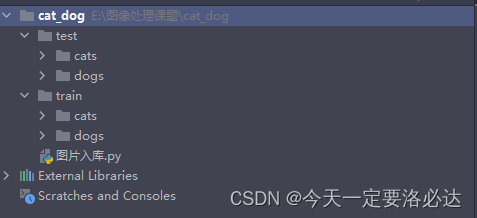
若此时要调用datasets.ImageFolder这个函数读取训练集的数据,就需要写成下面形式:
import torchvision.datasets as datasets
train = datasets.ImageFolder('train')
当然上面是最简单的形式,ImageFolder有好几个参数呢(上面只写了一个)。参数共有四个,介绍如下(前两个用的最多,不多做介绍了):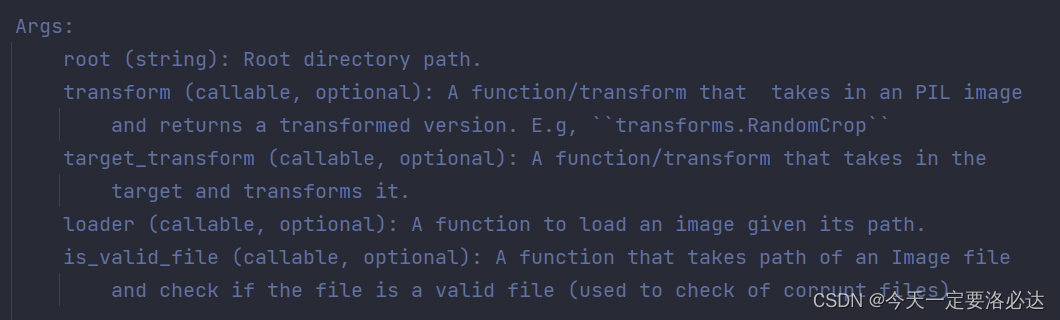
1.2.ImageFolder生成的对象
刚刚操作里train = datasets.ImageFolder(‘train’),它生成了一个对象
它共有3个特性: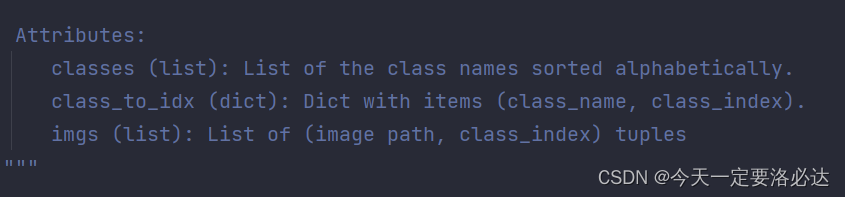
我们分别调用展示一下:
print(train.classes)print(train.class_to_idx)print(train.imgs)

分别是
1)类别 列表形式
2)种类对应数字标签 字典形式
3)每一个图像及其对应的标签 列表形式
为了检查图像是否都读取到了,我们用len()检查一下
print("训练集共有图像{}张".format(len(train.imgs)))
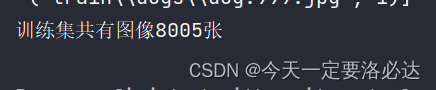
和文件夹里的数量一致(每个类别里有一个非jpg文件 不算):
1.3.其他探索:
print(train)print(train[0])print(train[0][0])print(type(train[0][0]))print(train[0][1])
我们看看train本身返回的是些什么东西: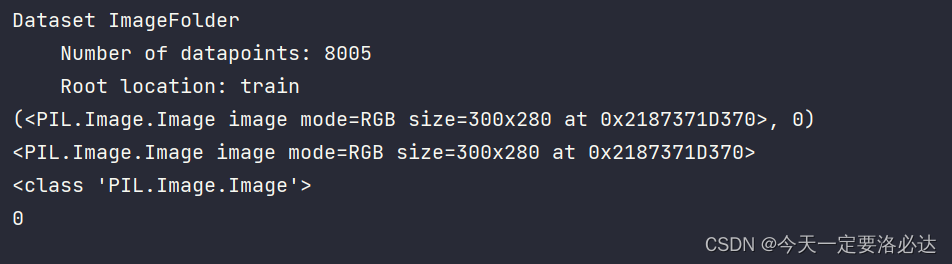
就不解释了,这个已经很明白了
train[0] [0]很明显是照片。我们可以用plt查看它:
plt.imshow(train[0][0])
plt.show()
二、glob使用方法
1.引入库
代码如下(示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
2.读入数据
代码如下(示例):
data = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')print(data.head())
该处使用的url网络请求的数据。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
本文转载自: https://blog.csdn.net/weixin_46274756/article/details/127712967
版权归原作者 今天一定要洛必达 所有, 如有侵权,请联系我们删除。
版权归原作者 今天一定要洛必达 所有, 如有侵权,请联系我们删除。