
参考视频:
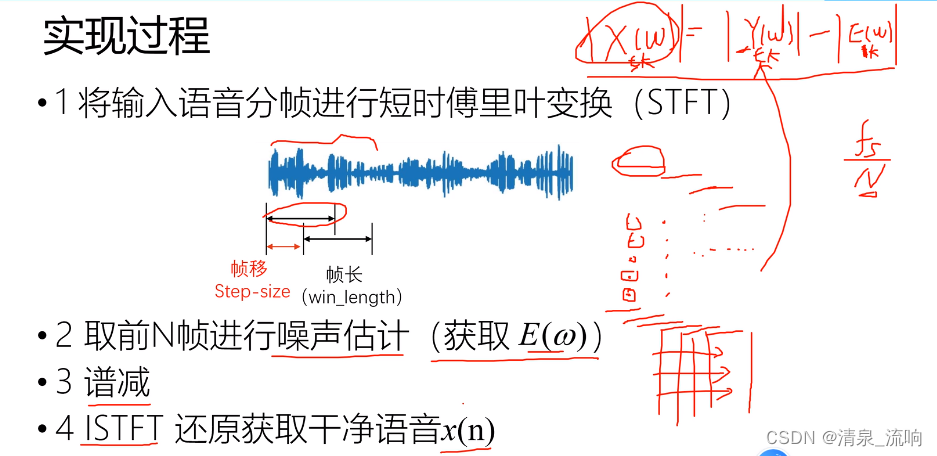
语音增强(去噪):消除语音中的噪声,增加语音听感与可懂度。
顾名思义,谱减法,就是用带噪信号的频谱减去噪声信号的频谱。谱减法基于一个简单的假设:假设语音中的噪声只有加性噪声,只要将带噪语音谱减去噪声谱,就可以得到纯净语音,这么做的前提是噪声信号是平稳的或者缓慢变化的。提出这个假设就是基于短时谱(25ms),就是频谱在短时间内是平稳不变的。

那噪音是怎么估计出来的呢?文献中一般都假设输入的一段语音中前n帧作为silence时间,也就是说这段时间没有语音输入,只有噪音,可以称之为底噪,将这前n帧中的噪音强度取平均值,作为估计出来的噪音。
实际上,我们不知道噪声是什么,我们要想办法对噪声进行估计,一般我们认为噪声是加性噪声,从语音开始的那一小段对噪声进行估计。一般去带噪语音前20-40帧进行噪声估计
但是这样做的方法有一个缺点就是由于我们估计噪音的时候取得平均值,那么有的地方噪音强度大于平均值的时候,相减后会有残留的噪音存在。在噪音波形谱上表现为一个一个的小尖峰,我们将这种残存的噪声称之为音乐噪声(music noise)。
运行程序后出现问题如下:

解决方法:
你可以偷偷看一下你是不是在新建python文件时文件命名是这样的情况:
‘test_’开头或者‘_test’结尾
因为这个,所以在运行这个python文件的时候报错Empty suite
比如你是test_A,把下划线去掉就可以了testA,然后就可以正常运行了。
下面来说一下为什么‘test_’开头或者‘_test’结尾用会导致出现Empty suite:
因为test_ 或者 _test 会使得程序认为你这个是做自动化测试的测试用例文件,
程序如下:
import librosa
from librosa.core.spectrum import amplitude_to_db
import numpy as np
import soundfile as sf
import matplotlib.pyplot as plt
if __name__ == "__main__":
clean_wav_file = "sf1_cln.wav"
clean,fs = librosa.load(clean_wav_file,sr=None) # sr=None表示读取原始信号的采样率
print(fs)
noisy_wav_file = "sf1_n0L.wav"
noisy,fs = librosa.load(noisy_wav_file,sr=None)
# 计算 nosiy 信号的频谱,帧长win_length,帧移hop_length,傅里叶变换的点数是n_fft=256个点
S_noisy = librosa.stft(noisy,n_fft=256, hop_length=128, win_length=256) # D x T
D,T = np.shape(S_noisy)
Mag_noisy= np.abs(S_noisy)
Phase_nosiy= np.angle(S_noisy)
Power_nosiy = Mag_noisy**2 # 得到信号的能量谱
print(fs)
# 估计噪声信号的能量
# 由于噪声信号未知 这里假设 含噪(noisy)信号的前30帧为噪声
Mag_nosie = np.mean(np.abs(S_noisy[:,:30]),axis=1,keepdims=True) # 沿T的维度取均值,输出维度是129*1
Power_nosie = Mag_nosie**2
Power_nosie = np.tile(Power_nosie,[1,T]) # 对前30帧进行不断复制到与带噪语音等长
# 能量减
Power_enhenc = Power_nosiy-Power_nosie
# 保证能量大于0
Power_enhenc[Power_enhenc<0]=0
Mag_enhenc = np.sqrt(Power_enhenc)
# 幅度减
# Mag_enhenc = np.sqrt(Power_nosiy) - np.sqrt(Power_nosie)
# Mag_enhenc[Mag_enhenc<0]=0
# 对信号进行恢复
S_enhec = Mag_enhenc*np.exp(1j*Phase_nosiy)
enhenc = librosa.istft(S_enhec, hop_length=128, win_length=256)
sf.write("enhce.wav",enhenc,fs)
print(fs)
# 绘制谱图
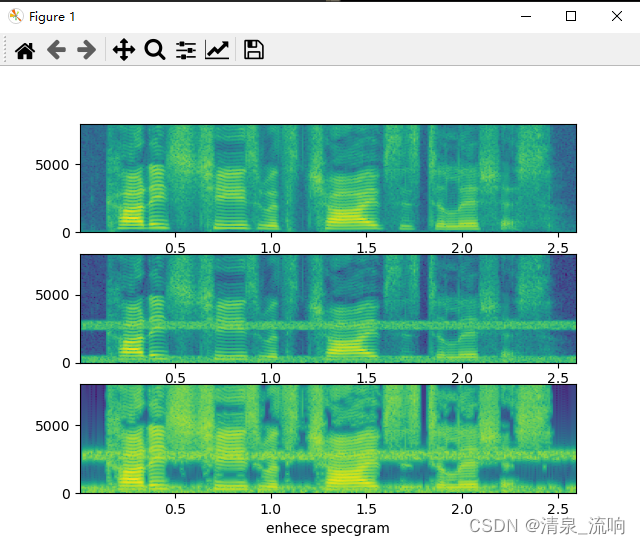
plt.subplot(3,1,1)
plt.specgram(clean,NFFT=256,Fs=fs)
plt.xlabel("clean specgram")
plt.subplot(3,1,2)
plt.specgram(noisy,NFFT=256,Fs=fs)
plt.xlabel("noisy specgram")
plt.subplot(3,1,3)
plt.specgram(enhenc,NFFT=256,Fs=fs)
plt.xlabel("enhece specgram")
plt.show()
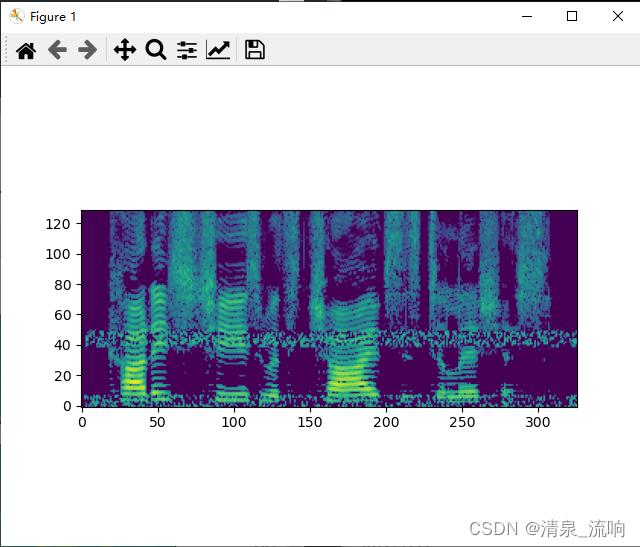
plt.imshow(librosa.amplitude_to_db(Mag_enhenc,ref=np.max),origin='lower')
plt.show()
# plt.show()
# plt.savefig("suntest_1.bmp")
运行结果如下:
本文转载自: https://blog.csdn.net/qq_42233059/article/details/126847123
版权归原作者 清泉_流响 所有, 如有侵权,请联系我们删除。
版权归原作者 清泉_流响 所有, 如有侵权,请联系我们删除。