
温馨提示:文末有 CSDN 平台官方提供的学长 Wechat / QQ 名片 :)
1. 项目简介
大数据技术在体育产业方面也具有重要作用。篮球是众多体育项目中受关注度最高的一项体育运动,NBA更是人们最喜爱的体育联盟之一。对NBA来说,对每位球员的精细分析和数据可视化不仅能帮助球队科学高效地分析球员优劣,为球队排兵布阵提供依据,还能让伟大的运动传奇更具商业价值。
本项目利用网络爬虫抓取 NBA 球员的所有赛季的数据,包括三分、篮板等各项参数,对每位球员的精细分析和数据可视化,不仅能帮助球队科学高效地分析球员优劣,为球队排兵布阵提供依据,还能让伟大的运动传奇更具商业价值。
2. 功能组成
基于大数据的NBA球员数据分析及预测系统的主要功能包括:
3. NBA 球员比赛数据爬虫
本项目利用 Python 的 request + beautifulsoup 等工具包实现原生网络爬虫,抓取 NBA 球员的各项比赛数据:
all_players = []
for season in range(2000, 2022):
print('抓取 {} 赛季的球员数据...'.format(season))
url = base_url.format(season)
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'cookie': 'Your cookies',
'referer': 'https://china.xxxxx.cn/statistics/',
'sec-ch-ua': '"Chromium";v="88", "Google Chrome";v="88", ";Not A Brand";v="99"',
'accept': '*/*'
}
resp = requests.get(url, headers=headers).json()
players = resp['payload']['players']
for player in players:
player['season'] = season
all_players.extend(players)
if len(all_players) % 10 == 0:
fout.writelines([json.dumps(player, ensure_ascii=False) + '\n' for player in all_players])
fout.flush()
all_players.clear()
time.sleep(1 + random.random())
4. 基于大数据的NBA球员数据分析及预测系统
4.1 系统首页和注册登录

4.2 球员赛季各项指标精细化分析
4.2.1 每个赛季参加场数与平均得分分布情况

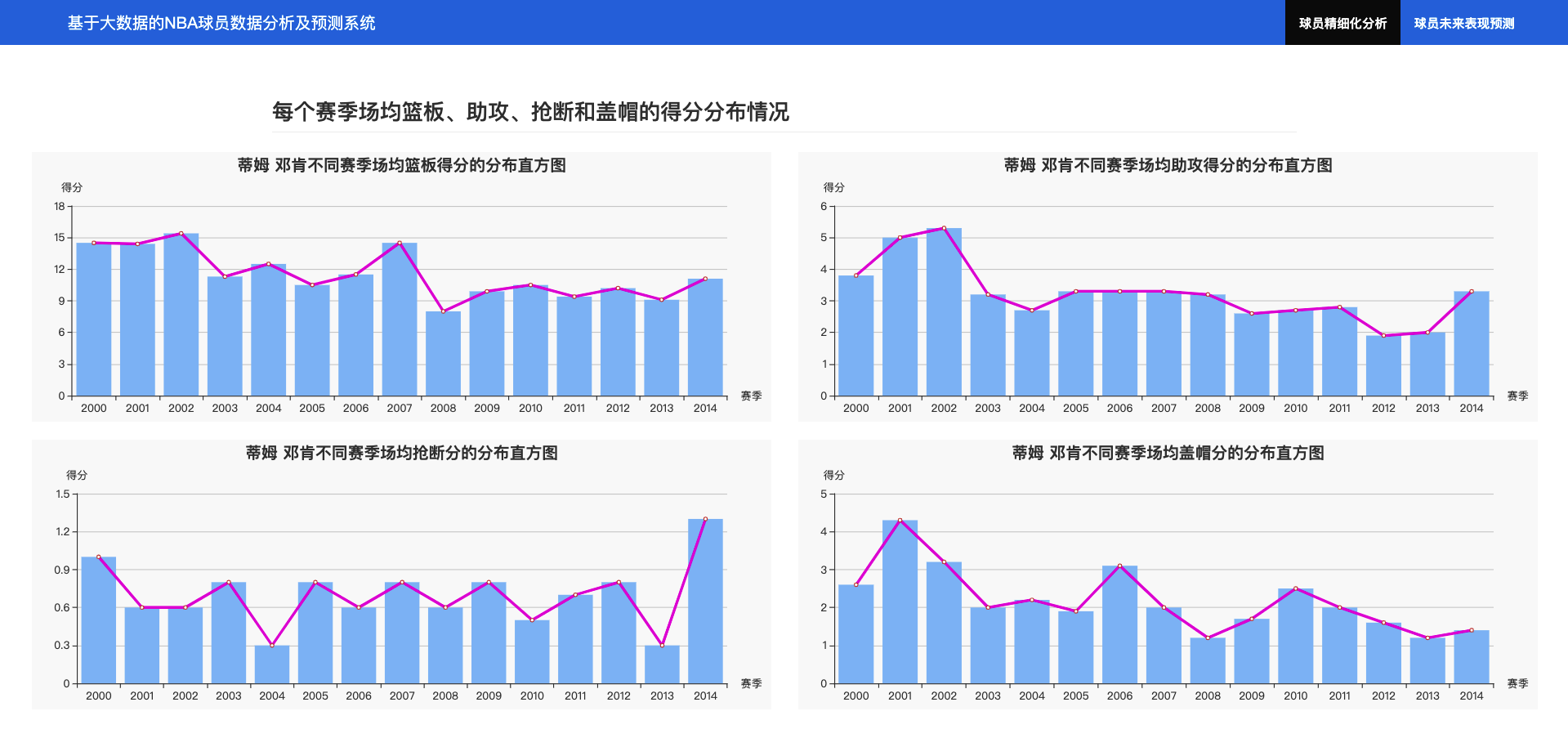
4.2.2 每个赛季场均篮板、助攻、抢断和盖帽的得分分布情况
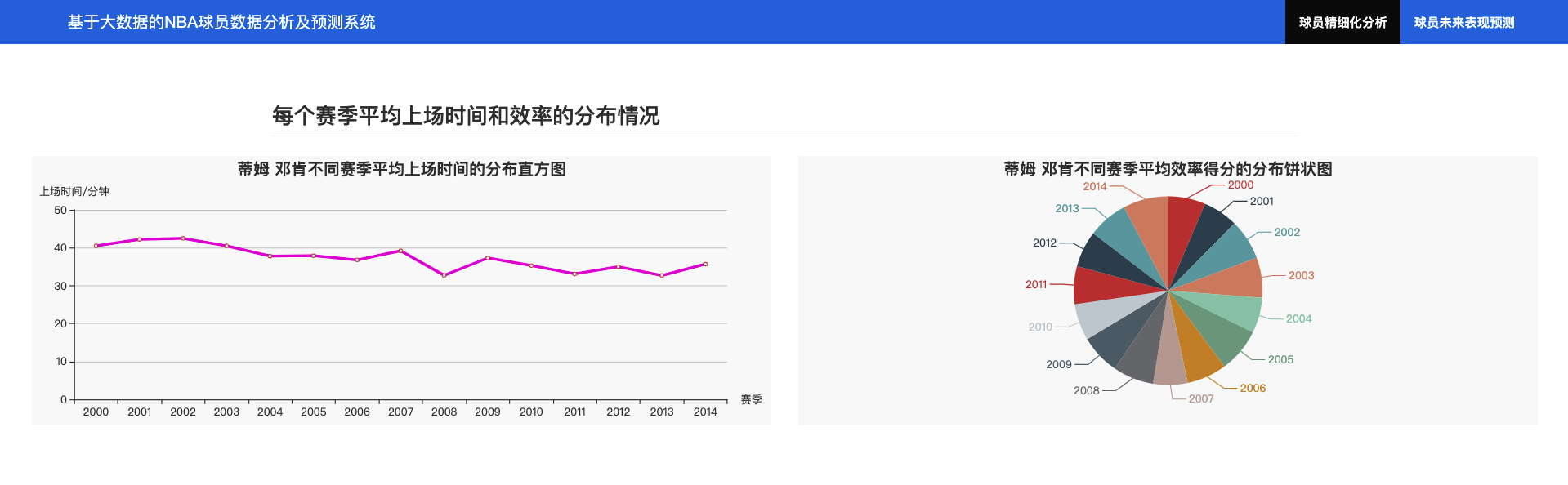
4.2.3 每个赛季平均上场时间和效率的分布情况
4.2.4 每个赛季三分、罚球、进攻、防守的分布情况
 4.3 场均得分、篮板、助攻和抢断得分趋势预测分析
4.3 场均得分、篮板、助攻和抢断得分趋势预测分析
本项目利用 ARIMA 算法实现球员场均得分、篮板、助攻和抢断得分的趋势预测分析:
def arima_model_train_eval(history):
# 构造 ARIMA 模型
model = ARIMA(history, order=(1, 1, 0))
# 基于历史数据训练
model_fit = model.fit(disp=0)
# 预测下一个时间步的值
output = model_fit.forecast()
yhat = output[0][0]
return yhat
def future_predict(player):
df = all_players[all_players['姓名'] == player]
# 赛季
saijis = df['赛季'].values.tolist()
saijis.append('2022')
# 场均得分
scores = df['场均得分'].values.tolist()
predict_score = arima_model_train_eval(scores)
scores.append(predict_score)
# 场均篮板
lanbans = df['场均篮板'].values.tolist()
predict_lanban = arima_model_train_eval(lanbans)
lanbans.append(predict_lanban)
# 场均助攻
zhugongs = df['场均助攻'].values.tolist()
predict_zhugong = arima_model_train_eval(zhugongs)
zhugongs.append(predict_zhugong)
# 场均抢断
jiangduans = df['场均抢断'].values.tolist()
predict_jiangduan = arima_model_train_eval(jiangduans)
jiangduans.append(predict_jiangduan)
......

5. 总结
本项目利用网络爬虫抓取 NBA 球员的所有赛季的数据,包括三分、篮板等各项参数,对每位球员的精细分析和数据可视化,不仅能帮助球队科学高效地分析球员优劣,为球队排兵布阵提供依据,还能让伟大的运动传奇更具商业价值。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
技术交流认准下方 CSDN 官方提供的学长 Wechat / QQ 名片 :)
精彩专栏推荐订阅:
1. Python 毕设精品实战案例
2. 自然语言处理 NLP 精品实战案例
3. 计算机视觉 CV 精品实战案例

本文转载自: https://blog.csdn.net/andrew_extra/article/details/125733574
版权归原作者 Python极客之家 所有, 如有侵权,请联系我们删除。
版权归原作者 Python极客之家 所有, 如有侵权,请联系我们删除。