
文章目录
前言
主要介绍MAE及其升级版CAE原理与代码
代码连接:MAE: https://github.com/facebookresearch/mae
CAE :https://github.com/lxtGH/CAE
一、MAE原理
论文「Masked Autoencoders Are Scalable Vision Learners」
证明了 masked autoencoders(MAE) 是一种可扩展的计算机视觉自监督学习方法。
遮住95%的像素后,仍能还原出物体的轮廓,效果如图:
 本文提出了一种掩膜自编码器 (MAE)架构,可以作为计算机视觉的可扩展自监督学习器使用。
本文提出了一种掩膜自编码器 (MAE)架构,可以作为计算机视觉的可扩展自监督学习器使用。
实现方法很简单:先将输入图像的随机部分予以屏蔽(Mask),再重建丢失的像素。
本文提出的MAE架构如下: 1. 大比例的随机的图像块子集(如 75%)被屏蔽掉。编码器用于可见patch的小子集。在编码器之后引入掩码token,构建出完整的token序列,由一个小型解码器处理,该解码器以像素为单位重建原始图像。
1. 大比例的随机的图像块子集(如 75%)被屏蔽掉。编码器用于可见patch的小子集。在编码器之后引入掩码token,构建出完整的token序列,由一个小型解码器处理,该解码器以像素为单位重建原始图像。
预训练后,解码器被丢弃,编码器应用于未损坏的图像以生成识别任务的表示。
- MAE 是一种简单的自编码方法,可以在给定部分观察的情况下重建原始信号。由编码器将观察到的信号映射到潜在表示,再由解码器从潜在表示重建原始信号。
与经典的自动编码器不同,MAE采用非对称设计,允许编码器仅对部分观察信号(未被掩盖的token)进行操作,并采用轻量级解码器从潜在表示和掩码标记中重建完整信号。
- 掩膜:
将图像划分为规则的非重叠patch。对patch的子集进行采样并屏蔽剩余patch。我们的采样策略很简单:均匀分布,简单称为“随机抽样”。
- MAE 编码器
编码器仅适用于可见的、未屏蔽的patch。编码器通过添加位置嵌入的线性投影嵌入patch,然后通过一系列 Transformer 块处理结果集。编码器只对整个集合的一小部分(如 25%)进行操作。
被屏蔽的patch会被移除;不使用掩码令牌。这样可以节约计算资源,使用一小部分计算和内存来训练非常大的编码器。
- MAE解码器
解码器的输入是完整的令牌集。每个掩码标记代表一个共享的、学习过的向量,表示存在要预测的缺失patch。
解码器仅在预训练期间用于执行图像重建任务。因此,它的设计可以独立于编码器。实验中使用的解码器更加轻量级。通过这种非对称设计,显著减少了预训练时间。
- 图像目标的重建
MAE 通过预测每个掩码块的像素值来重建输入图像。
解码器输出中的每个元素都是一个表示补丁的像素值向量。解码器的最后一层是线性投影,其输出通道的数量等于补丁中像素值的数量。解码器的输出被重新整形以形成重建的图像。
MAE 预训练实施效率高,实现方式简单,而且不需要任何专门的稀疏操作。
二、MAE测试代码
无具体测试文件。根据mae项目中demo/mae_visualize.ipynb.文件,自己写了一个demo.py,放在项目主目录里。如下:
主要函数为line44 :
loss, y, mask = model(x.float(), mask_ratio=0.75)
import sys
import os
import requests
import torch
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
matplotlib.use('TKAgg')
import models_mae
#definetheutils
imagenet_mean = np.array([0.485,0.456,0.406])
imagenet_std = np.array([0.229,0.224,0.225])
def show_image(image, title=''):#imageis [H, W,3]
assert image.shape[2]==3
plt.imshow(torch.clip((image * imagenet_std + imagenet_mean)*255,0,255).int())
plt.title(title, fontsize=16)
plt.axis('off')return
def prepare_model(chkpt_dir, arch='mae_vit_large_patch16'):#buildmodel
model =getattr(models_mae, arch)()#loadmodel
checkpoint = torch.load(chkpt_dir, map_location='cpu')
msg = model.load_state_dict(checkpoint['model'], strict=False)print(msg)return model
def run_one_image(img, model):
x = torch.tensor(img)#makeit a batch-like
x = x.unsqueeze(dim=0)
x = torch.einsum('nhwc->nchw', x)#runMAE
loss, y, mask =model(x.float(), mask_ratio=0.75) # y是重构出的tokens
y = model.unpatchify(y)
y = torch.einsum('nchw->nhwc', y).detach().cpu()#visualizethe mask
mask = mask.detach()
mask = mask.unsqueeze(-1).repeat(1,1, model.patch_embed.patch_size[0]**2*3) # (N, H*W, p*p*3)
mask = model.unpatchify(mask) # 1 is removing,0 is keeping
mask = torch.einsum('nchw->nhwc', mask).detach().cpu()
x = torch.einsum('nchw->nhwc', x)#maskedimage
im_masked = x *(1- mask) # 掩盖75%后的原图
#MAE reconstruction pasted with visible patches
im_paste = x *(1- mask)+ y * mask # 25%原图+75%生成图
#makethe plt figure larger
plt.rcParams['figure.figsize']=[24,24]
plt.subplot(1,4,1)show_image(x[0],"original")
plt.subplot(1,4,2)show_image(im_masked[0],"masked")
plt.subplot(1,4,3)show_image(y[0],"reconstruction")
plt.subplot(1,4,4)show_image(im_paste[0],"reconstruction + visible")
plt.show()#loadan image
img_path = '/home/ubuntu/mae/demo/1803262023-00000012.jpg'
#img= Image.open(requests.get(img_url, stream=True).raw)
img = Image.open(img_url)
img = img.resize((224,224))
img = np.array(img)/255.
assert img.shape ==(224,224,3)#normalizeby ImageNet mean and std
img = img - imagenet_mean
img = img / imagenet_std
plt.rcParams['figure.figsize']=[5,5]show_image(torch.tensor(img))
# --------------------------mae_model-----------------------------
chkpt_dir = 'model/mae_visualize_vit_large.pth'
model_mae =prepare_model(chkpt_dir,'mae_vit_large_patch16')print('Model loaded.')
torch.manual_seed(2)print('MAE with pixel reconstruction:')run_one_image(img, model_mae)
# --------------------------mae_ganloss---------------------------
chkpt_dir = 'model/mae_visualize_vit_large_ganloss.pth'
model_mae_gan =prepare_model(chkpt_dir,'mae_vit_large_patch16')print('Model loaded.')
torch.manual_seed(2)print('MAE with extra GAN loss:')run_one_image(img, model_mae_gan)
从model(line44)进入主函数models_mae.py
1.models_mae.py
def forward(self, imgs, mask_ratio=0.75):
latent, mask, ids_restore = self.forward_encoder(imgs, mask_ratio) #(1,3,224,224)0.75
pred = self.forward_decoder(latent, ids_restore) # [N, L, p*p*3]
loss = self.forward_loss(imgs, pred, mask)return loss, pred, mask
1.1 self.forward_encoder
编码阶段有22层(large模型)
def forward_encoder(self, x, mask_ratio):#embedpatches
x = self.patch_embed(x) # (1,3,224,224)---con2d(16,16)--->(1,196,1024)#addpos embed w/o cls token
x = x + self.pos_embed[:,1:,:] # ([1,196,1024])#masking: length -> length * mask_ratio
x, mask, ids_restore = self.random_masking(x, mask_ratio)#mask:(1,196):25%*True ids_restore:(1,196):random index[0~195]#appendcls token
cls_token = self.cls_token + self.pos_embed[:,:1,:] # ([1,1,1024])
cls_tokens = cls_token.expand(x.shape[0],-1,-1)
x = torch.cat((cls_tokens, x), dim=1) # (1,50,1024)#applyTransformer blocksfor blk in self.blocks:
x =blk(x) # 最普通注意力层,输出前后不变(large:22层)
x = self.norm(x)return x, mask, ids_restore
其中,位置编码pos_embed是一个可学习参数。cls_token类别查询项,同理:
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim), requires_grad=False) # fixed sin-cos embedding
import numpy as np
1.2 self.forward_decoder
decode阶段(只有7层),编码维度为512。mask_tokens为可学习变量,后面有解释
def forward_decoder(self, x, ids_restore):#embedtokens
x = self.decoder_embed(x) # (1,50,1024)--->(1,50,512)#appendmask tokens to sequence
mask_tokens = self.mask_token.repeat(x.shape[0], ids_restore.shape[1]+1- x.shape[1],1) # (1,1,512)-->(1,147,512)
x_ = torch.cat([x[:,1:,:], mask_tokens], dim=1) # no cls token x_:(1,196,512)
x_ = torch.gather(x_, dim=1, index=ids_restore.unsqueeze(-1).repeat(1,1, x.shape[2])) # unshuffle x_:(1,196,512)
x = torch.cat([x[:,:1,:], x_], dim=1) # appd cls token(1,197,512)#addpos embed
x = x + self.decoder_pos_embed
#applyTransformer blocksfor blk in self.decoder_blocks:
x =blk(x)
x = self.decoder_norm(x) # (1,197,512)#predictorprojection
x = self.decoder_pred(x) # (1,197,768)#removecls token
x = x[:,1:,:]return x
self.mask_token = nn.Parameter(torch.zeros(1, 1, decoder_embed_dim))
1.3 loss = self.forward_loss(imgs, pred, mask)
这里只做一个简单的像素级损失
def forward_loss(self, imgs, pred, mask):"""
imgs:[N,3, H, W]
pred:[N, L, p*p*3]
mask:[N, L],0 is keep,1 is remove,"""
target = self.patchify(imgs) # (1,196,768) 只是一个维度变换
if self.norm_pix_loss:
mean = target.mean(dim=-1, keepdim=True)
var = target.var(dim=-1, keepdim=True)
target =(target - mean)/(var +1.e-6)**.5
loss =(pred - target)**2 # (1,196,768)
loss = loss.mean(dim=-1) # [N, L], mean loss per patch(1,196)
loss =(loss * mask).sum()/ mask.sum() # mean loss on removed patches
return loss
2.run_one_image
loss, y, mask =model(x.float(), mask_ratio=0.75) # (1,196,768)
y = model.unpatchify(y) # (1,3,224,224) 维度变换
y = torch.einsum('nchw->nhwc', y).detach().cpu() # (1,224,224,3)#visualizethe mask
mask = mask.detach()
mask = mask.unsqueeze(-1).repeat(1,1, model.patch_embed.patch_size[0]**2*3) # (N, H*W, p*p*3)(1,196,768)
mask = model.unpatchify(mask) # 1 is removing,0 is keeping # (1,3,224,224)
mask = torch.einsum('nchw->nhwc', mask).detach().cpu() # (1,224,224,3)
x = torch.einsum('nchw->nhwc', x) # (1,224,224,3)#maskedimage
im_masked = x *(1- mask)#MAE reconstruction pasted with visible patches
im_paste = x *(1- mask)+ y * mask
#makethe plt figure larger
plt.rcParams['figure.figsize']=[24,24]
plt.subplot(1,4,1)show_image(x[0],"original")
plt.subplot(1,4,2)show_image(im_masked[0],"masked")
plt.subplot(1,4,3)show_image(y[0],"reconstruction")
plt.subplot(1,4,4)show_image(im_paste[0],"reconstruction + visible")
plt.show()
结果如图:
三、MAE升级版CAE(2022)
论文:https://arxiv.org/abs/2202.03026
题目:Context Autoencoder for Self-Supervised Representation Learning
Mask Image Modeling (MIM) 方法,在 NLP 领域 (例如BERT) 得到了广泛的应用。随着 ViT 的提出和发展,人们也尝试将 MIM 应用到视觉领域并取得了一定进展。在此之前,视觉自监督算法主要沿着 contrastive learning 的思路去设计,而 MIM 无疑打开了新的大门。我们最近的工作 “Context Autoencoder for Self-Supervised Representation Learning”,提出一种新的 MIM 方法 CAE,通过对 “表征学习” 和 “解决 pretext task” 这两个功能做尽可能的分离,使得 encoder 学习到更好的表征,从而在下游任务实现了更好的泛化性能。我们尝试回答如下几个问题:
1.MIM 方法中,网络结构的哪个部分是学习表征的,哪个部分是解决 pretext task?
2.为什么之前典型的 contrastive learning 方法,在下游任务 (例如检测、分割) 上只能取得跟 supervised pretraining 类似的性能?
3.MIM 方法为什么优于目前的 contrastive learning 方法?
1.背景
MIM 是一种自监督表征学习算法。它的主要思路是,对输入图像进行分块和随机掩码操作,然后对掩码区域做一些预测。预测的目标可以是 Token ID (BEiT),也可以是 RGB 的值 (MAE)。通过 MIM,我们希望 encoder 能学习到一个好的表征,从而在下游任务取得良好的泛化的性能。
近期 MIM 有两个代表性工作:BEiT 和 MAE。
BEiT 使用一个 encoder 做两件事:**(1) 学习一个好的图像表征; (2) 解决 pretext task**:预测 masked patch 的 Token ID。encoder 的潜力并没有完全被挖掘,只有部分被用来学习表征。
MAE 使用了 encoder-decoder 架构,encoder 负责对 visible patch 进行表征学习,decoder 将 visible 和 masked patch 的表征 (masked patch 使用一个可学习的向量) 作为输入,预测 masked patch 的 RGB 值。但是,MAE 在 decoder 中也会对 visible patch 的表征进行改变。与此同时,MAE decoder 利用改变后的可见区域的表征去预测遮挡区域的表征,实际上 decoder 也负责了一部分表征学习的功能。然而,在下游任务中,只有 encoder 中学到的信息能被拿来用,那么即使在 decoder 中进一步学到了更好的表征,也无法利用到下游任务中。
以上两种方法,都没有充分挖掘 encoder 的潜力,限制了预训练学习到的表征质量。
2. Context Autoencoder (CAE)
CAE 设计的核心思想是对 “表征学习” 和 “解决 pretext task” 这两个功能做分离。我们希望在预训练时,表征学习的任务只交给 encoder,而 decoder 只负责解决 pretext task。这样我们希望从 encoder 出来的表征就是非常好的,而不需要额外的模块对表征进一步 refine (例如 MAE 中的 decoder),可以尽可能大地挖掘 encoder 的潜力。
CAE 包括4个部分:**(1) encoder; (2) latent contextual regressor; (3) decoder; (4) alignment module。**
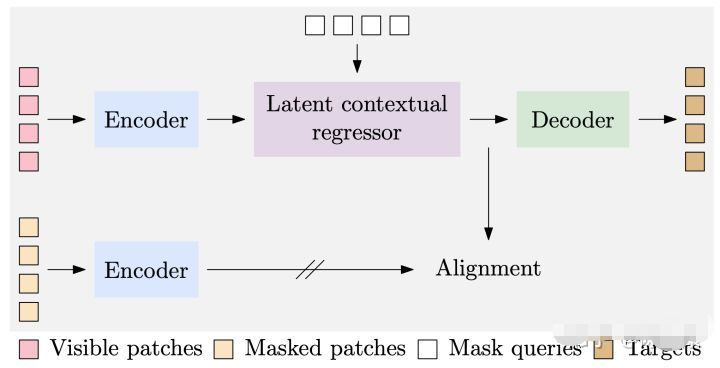
输入图像通过随机掩码被划分成 visible patch 和 masked patch 两个部分。具体来说:
- Encoder 是一个 ViT 模型,负责学习 visible patch 的表征 Z_v
- Latent contextual regressor 通过 Z_v预测 masked patch 的表征 Z_m 。
- Latent contextual regressor 由一系列 cross-attention module 组成,query 是 masked patch 的表征,key 和 value 是全部 patch 的表征。在计算 query-key 相似度时,我们会引入每个 patch 对应的位置编码。在这个阶段, Z_m 不断更新、变得更加准确,而 Z_v不会更新,对图像特征的提取这个任务完全交给 encoder。
- Decoder 只拿 Z_m和 对应的位置编码作为输入,其目的是通过 Z_m预测 masked patch 的某些性质,比如由训练好的 tokenizer 产生的 Token ID,或者 RGB 的值。本文的实验 follow BEiT,使用 DALL-E tokenizer 对输入图像 token 化,得到 decoder 的目标。
- Latent representation alignment 是非常关键的一部分。虽然 visible patch 的表征在 encoder 之后就不会改变,但 latent contextual regressor 可能会”偷偷地“学习 masked patch 的表征,然后基于这样一个比 encoder 的输出更好的表征在 decoder 中进行预测。如果是这样,那么 latent contextual regressor 也承担了一部分表征学习的功能,这与我们想要的”分离“是相悖的。于是我们通过对 Z_m添加约束,希望 latent contextual regressor 的输出和 encoder 的输出在同一编码空间中,这样表征学习的任务还是落到了 encoder 的身上。我们将图像的 masked patch 也输入到 encoder,获得这部分的表征 Z’_m 。 将Z’_m 作为Z_m 学习的目标。计算Z’_m 的过程不会计算梯度。
- 损失函数。损失函数由两部分组成:(1) 对 decoder 预测的监督,使用 cross-entropy loss; (2) 对 和 的 align 的监督,使用 MSE loss.
3. 分析
3.1 CAE 关心每个 patch 的表征
CAE 基于 visible patch 的表征,从随机采样的 masked patch 做一些预测,这要求 CAE 关心每个 patch 的语义。这不同于典型的对比学习方法 (例如 MoCo v3, SimCLR),这类方法只关心图像的全局语义,忽略了图像的细节和非主体区域 (比如背景)。
3.2 Latent contextual regressor 的输出和 encoder 的输出在同一编码空间中
我们对 latent contextual regressor 的输出做了约束,希望它能和 encoder 的输出尽可能处于同一编码空间中。这样,decoder 会基于 encoder 学到的编码空间做预测,将对图像的特征提取的重任完全交到了 encoder 身上,驱使 encoder 学习到好的表征。
为了验证表征空间确实对齐了,我们用 RGB 值作为 decoder 目标 (考虑到 Token ID 难以可视化,这边使用 RGB),训练 CAE。在测试的时候,我们将全部 patch 输入到 encoder,然后跳过 latent contextual regressor,直接将 encoder 的输出送进 decoder,预测全部 patch 的 RGB 的值。下图展示了预测结果,第一行是原图,第二行是预测,我们发现仅使用 encoder 和 decoder 就可以将图片重建出来,说明 encoder 的输出和 latent contextual regressor 的输出属于同一编码空间。
如果训练时不做 alignment 约束,那么无法重建,如下图所示,输出都是乱码,说明 encoder 输出和 latent contextual regressor 的输出不在一个编码空间中。这使得 regressor 也承担了一部分表征学习的角色,使得 encoder 学到的表征质量有所欠缺,在消融实验部分也有验证。
3.3 CAE 学到的表征可以区分不同类别的 object/stuff
CAE 基于 visible patch 的表征,在 masked patch 区域做预测,这要求 CAE 对 visible patch 的内容有比较好的理解。举例来说,我们看到一只狗的头部,我们可以预测出它的身体部分;我们看到一小片天空,我们也能预测出它的周围大概率也是一片天空。因此,我们认为 CAE 学到的表征可以区分不同类别的 object/stuff。为了验证这一点,我们从 ADE20K 数据集随机采样一些图片输入到 encoder。因为 ADE20K 提供了每个像素的类别标签 (150类),我们可以使用 t-SNE 对 encoder 输出的表征进行可视化。如下图所示,每个颜色代表一个类别,左图是 CAE,右图是随机初始化的 encoder。我们可以发现 CAE 可以有效区分不同类别的 object/stuff (因为是在 ImageNet-1K 进行预训练,所以区分地不够完美),而随机初始化的 encoder 无法做到这一点。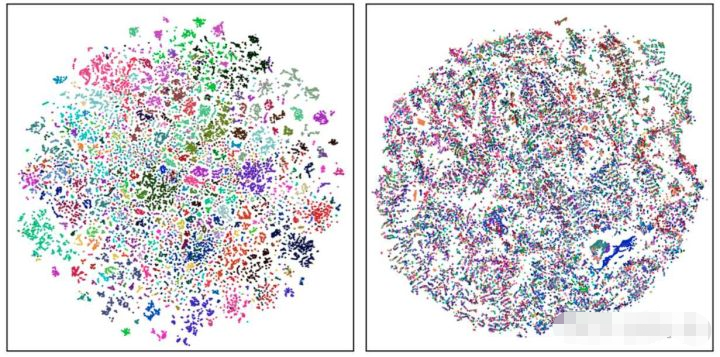
3.4 典型的 contrastive learning 为什么在下游任务只能取得跟 supervised pre-training 差不多的结果
在 contrastive learning 中,random crop 是一个非常重要的数据增强策略。典型的 contrastive learning (比如 MoCo v3) 希望最大化来自同一图像的 2 个不同 crop 之间的全局语义相似度,而最小化来自不同图像的 crop 之间的相似度。这样为什么能奏效呢?我们首先分析 random crop 的性质。在 SimCLR 论文中提到,random crop 是 contrastive learning 方法中非常重要的数据增强策略。在 ImageNet-1K 数据集中,图像的主体物体大多处于图像的中心区域,而对图像进行 random crop,中心区域有很大的概率被囊括进去,例如下图展示的几个例子,几次 crop 基本都包括了图像的主体物体。
对同一图像的不同 crop 提取全局语义,实际上学到的是原始图像中主体物体的特征,正因如此,同一图像的不同 crop 之间才可能相似。在 supervised pre-training 中,受到图像分类标签的约束,网络学习到的也是图像主体区域的特征,这和 contrastive learning 学到的知识有很大的相似之处,因此在下游任务表现类似。
3.5 MIM 和 contrastive learning 的区别
MIM 方法 (例如 CAE) 基于 visible patch 的表征,对 masked patch 区域做预测。在做随机掩码时,图像的每个 patch (例如背景区域的 object/stuff) 都有可能被考虑到,而不仅仅是图像的主体区域。为了做好 masked patch 的预测,CAE 会学好每个 patch 的表征。
我们对 CAE 以及 MoCo v3 的 attention map 做了可视化。如下图所示,第一行是原图,第二行是 MoCo v3,第三行是 CAE。红色表示 attention value 更高,蓝色表示attention value 低。处于蓝色边界内部的区域,通过这样的原则筛选:将 attention value 从大到小排序后,保留累计和达到所有位置 attention value 总和的 50% 的部分。我们可以看到,MoCo v3 的attention map 主要在图像的主体区域有高响应,而 CAE 能考虑到几乎所有 patch。
4. 实验
我们使用 ViT-small 和 ViT-base 在 ImageNet-1K 上进行实验。输入图像的分辨率是224224,patch 大小是1616 ,一张图会被划分成14*14个 patch。
Pretraining Evaluation
自监督学习广泛使用 linear probing 去评测预训练表征的好坏:将 encoder 的参数固定住,在之后加一个 linear classifier 进行图像分类。我们认为 linear probing 不适合 MIM 方法,因为 MIM 方法通常会学到每个 patch 的表征,不仅包含主体物体的信息,还学到了背景等若干知识,这是多而杂的,不适合直接进行线性分类。我们额外提出一种新的测试指标:attentive probing。我们在固定参数的 encoder 后加上一个简单的 cross-attention module (没有 FFN)和一个 linear classifier,通过注意力机制动态地选择适合做图像分类的信息。
我们对 attentive probing 阶段使用的 cross-attention module 做 attention map 可视化,发现可以关注到主体物体。
5 总结
本文提出了 CAE,设计的核心有两点:(1) 对 “表征学习” 和 “解决 pretext task” 这两个功能做尽可能的分离; (2) 在 visible patch 学习到的表征空间中对 masked patch 做预测。以上两点都是为了驱使 encoder 学习更好的表征,从而在下游任务取得良好的泛化能力。除此之外,我们对 supervised pre-training、contrastive learning 和 MIM 方法进行分析,认为 contrastive learning 和 supervised pre-training 主要关注图像的主体区域 (例如 ImageNet-1K 标签集中的物体),而 MIM 会关注图像的全部 patch,更有利于下游任务。
import numpy as np
import numpy as np
import numpy as np
import numpy as np
1.引入库
代码如下(示例):
2.读入数据
代码如下(示例):
版权归原作者 杀生丸学AI 所有, 如有侵权,请联系我们删除。