
继BiSeNetV1之后(语义分割系列16-BiSeNetV1),BiSeNetV2在2021年IJCV上发布。
论文链接:BiSeNetV2
相比于V1版本,V2版本在下采样策略、卷积类型、特征融合等方面做了诸多改进。
本文将介绍:
- BiSeNetV2如何设计Semantic Branch和Detail Branch。
- BiSeNetV2如何设计Aggregation Layer完成特征融合。
- BiSeNetV2如何设计Auxiliary Loss来帮助模型训练。
- BiSeNetV2的代码实现与应用。
论文部分
引文
BiSeNetV1版本的双路分割结构在实时分割的任务中取得了不错的效果,这种网络结构能够保留低级细节和高级语义,同时又不会损害推理速度,很好的权衡了实现准确的语义分割任务和快速的推理速度之间的平衡。
因此,提出了基于双路的分段网络-BiSeNetV2来实现实时的语义分割。
相比于初版BiSeNetV1:
- V2简化了原始结构,使网络更加高效
- 使用更加紧凑的网络结构以及精心设计的组件,加深了Semantic Branch的网络,使用更加轻巧的深度可分离卷积来加速模型。
- 设计了更为有效的Aggregation Layer,以增强Semantic Branch和Detail Branch之间的链接。
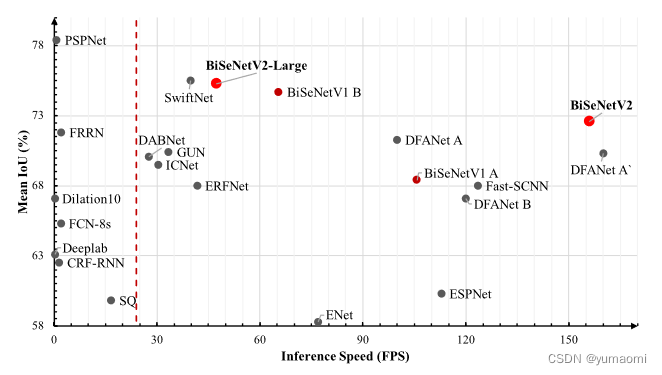
模型
首先看模型的整体结构:
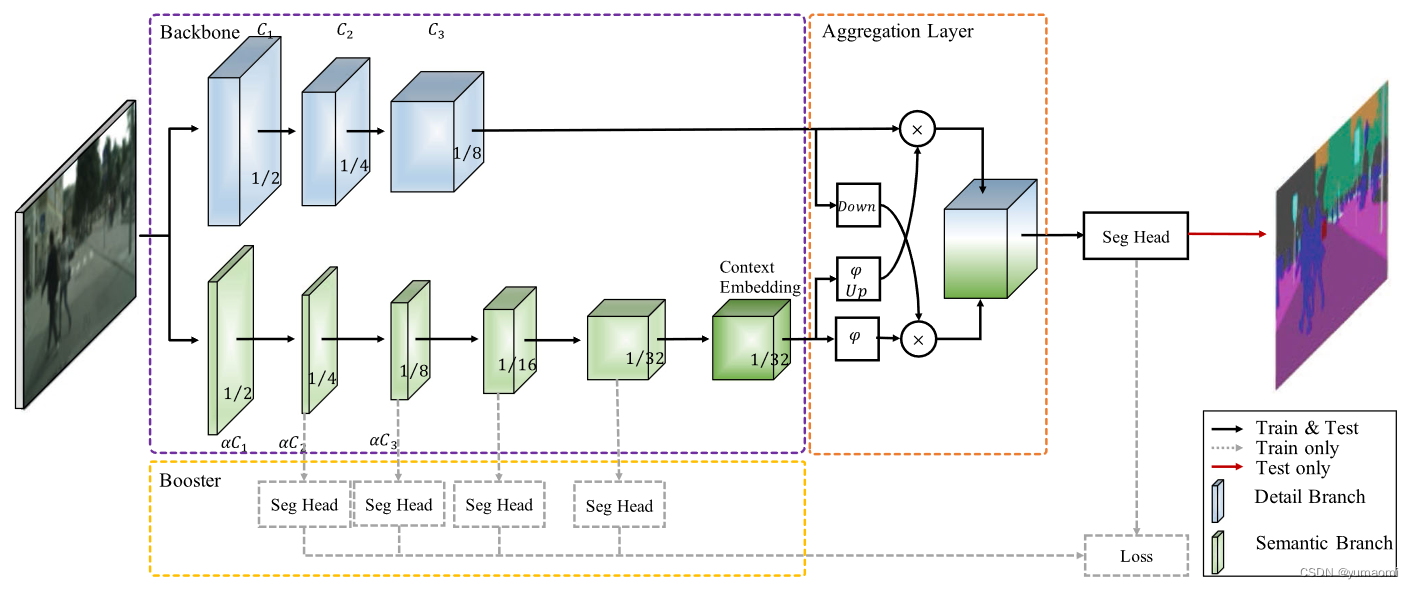
图1 BiSeNetV2模型结构
BiSeNetV2主要包含几个结构:
- 紫色框(backbone)内的双路分支,上为Detail Branch分支,下为Semantic Branch分支。
- 橙色框(Aggregation Layer)内的Aggregation Layer聚合层。
- 黄色框(Booster)内的Auxiliary Loss分支。
首先,我们先介绍紫色框backbone部分。
Backbone-Detail Branch
对于Detail Branch,依旧使用类VGG的网络结构,这一部分结构较为简单,用于快速下采样并得到细分的feature map。
代码部分如下:
import torch
import torch.nn as nn
class DetailBranch(nn.Module):
def __init__(self, detail_channels=(64, 64, 128), in_channels=3):
super(DetailBranch, self).__init__()
self.detail_branch = nn.ModuleList()
for i in range(len(detail_channels)):
if i == 0:
self.detail_branch.append(
nn.Sequential(
nn.Conv2d(in_channels, detail_channels[i], 3, stride=2, padding=1),
nn.BatchNorm2d(detail_channels[i]),
nn.ReLU(),
nn.Conv2d(detail_channels[i], detail_channels[i], 3, stride=1, padding=1),
nn.BatchNorm2d(detail_channels[i]),
nn.ReLU(),
)
)
else:
self.detail_branch.append(
nn.Sequential(
nn.Conv2d(detail_channels[i-1], detail_channels[i], 3, stride=2, padding=1),
nn.BatchNorm2d(detail_channels[i]),
nn.ReLU(),
nn.Conv2d(detail_channels[i], detail_channels[i], 3, stride=1, padding=1),
nn.BatchNorm2d(detail_channels[i]),
nn.ReLU(),
nn.Conv2d(detail_channels[i], detail_channels[i], 3, stride=1, padding=1),
nn.BatchNorm2d(detail_channels[i]),
nn.ReLU()
)
)
def forward(self, x):
for stage in self.detail_branch:
x = stage(x)
return x
if __name__ == "__main__":
x = torch.randn(3, 3, 224, 224)
net = DetailBranch(detail_channels=(64, 64, 128), in_channels=3)
out = net(x)
print(out.shape)
Backbone-Semantic Branch
Semantic Branch与Detail Branch平行,主要用于捕获高级语义信息。在这一个分支中,通道数比较少,因为更多信息可以由Detail Branch提供。由于获取高级语义信息需要上下文的依赖和较大的感受野,所以,在这一个分支中,使用快速采样的策略来迅速扩大感受野;使用全局平均池化来嵌入上下文信息。
作者在这部分做了较为精心的设计,主要包括三部分:
- Stem Block用于快速下采样;
- Gather-and-Expansion Layer(GE Layer)用于卷积获取细节信息。
- Context Embedding Block(CE Layer)用于嵌入上下文信息。
Stem Block 和CE Block结构
Stem Block和CE Block的结构较为简单。
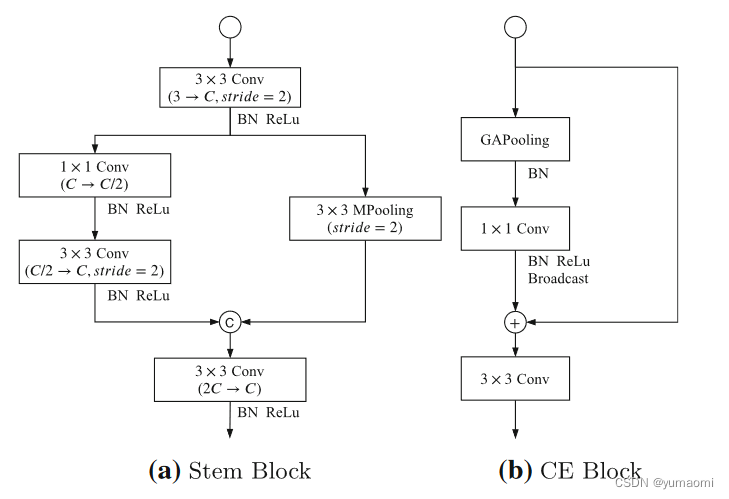
图2 Stem Block 和CE Block结构
代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class StemBlock(nn.Module):
def __init__(self, in_channels=3, out_channels=16):
super(StemBlock, self).__init__()
self.conv_in = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
self.conv_branch = nn.Sequential(
nn.Conv2d(out_channels, out_channels//2, 1),
nn.BatchNorm2d(out_channels//2),
nn.ReLU(),
nn.Conv2d(out_channels//2, out_channels, 3, stride=2, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
self.pool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False)
self.fusion = nn.Sequential(
nn.Conv2d(2*out_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
def forward(self, x):
x = self.conv_in(x)
x_branch = self.conv_branch(x)
x_downsample = self.pool(x)
out = torch.cat([x_branch, x_downsample], dim=1)
out = self.fusion(out)
return out
if __name__ == "__main__":
x = torch.randn(3, 3, 224, 224)
net = StemBlock()
out = net(x)
print(out.shape)
class CEBlock(nn.Module):
def __init__(self,in_channels=16, out_channels=16):
super(CEBlock, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.gap = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
# AdaptiveAvgPool2d 把形状变为(Batch size, N, 1, 1)后,batch size=1不能正常通过BatchNorm2d, 但是batch size>1是可以正常通过的
# nn.BatchNorm2d(self.in_channels)
)
self.conv_gap = nn.Sequential(
nn.Conv2d(self.in_channels, self.out_channels, 1, stride=1, padding=0),
# nn.BatchNorm2d(self.out_channels), 同上
nn.ReLU()
)
# Note: in paper here is naive conv2d, no bn-relu
self.conv_last = nn.Conv2d(
in_channels=self.out_channels,
out_channels=self.out_channels,
kernel_size=3,
stride=1,
padding=1)
def forward(self, x):
identity = x
x = self.gap(x)
x = self.conv_gap(x)
x = identity + x
x = self.conv_last(x)
return x
if __name__ == "__main__":
x = torch.randn(1, 16, 224, 224)
net = CEBlock()
out = net(x)
print(out.shape)
GE Block结构
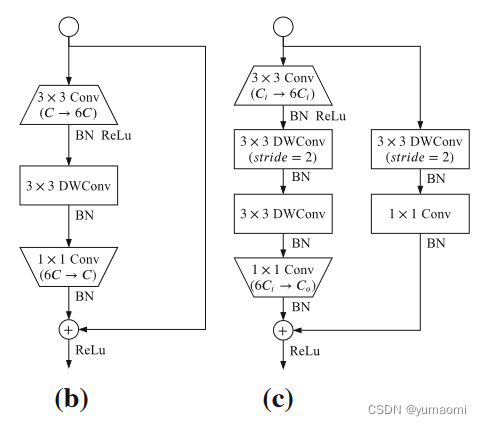
图3 GE Block结构(b,c)
对于GE Block,分为是否进行下采样两个模块,不进行下采样的GE Block(b)和进行下采样的GE Block。作者在这里借鉴了MobileNetv2中的倒瓶颈结构设计,为了减少计算量,中间使用一个深度可分离卷积。
下面给出GE Block的代码:
import torch
import torch.nn as nn
class depthwise_separable_conv(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super(depthwise_separable_conv, self).__init__()
self.depthwise = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=stride, padding=1, groups=in_channels)
self.pointwise = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
out = self.depthwise(x)
out = self.pointwise(out)
return out
class GELayer(nn.Module):
def __init__(self, in_channels, out_channels, exp_ratio=6, stride=1):
super(GELayer, self).__init__()
mid_channel = in_channels * exp_ratio
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1,padding=1),
nn.BatchNorm2d(in_channels),
nn.ReLU()
)
if stride == 1:
self.dwconv = nn.Sequential(
# ReLU in ConvModule not shown in paper
nn.Conv2d(in_channels, mid_channel, 3, stride=stride, padding=1, groups=in_channels),
nn.BatchNorm2d(mid_channel),
nn.ReLU(),
depthwise_separable_conv(mid_channel, mid_channel, stride=1),
nn.BatchNorm2d(mid_channel),
)
self.shortcut = None
else:
self.dwconv = nn.Sequential(
nn.Conv2d(in_channels, mid_channel, 3, stride=1, padding=1, groups=in_channels,bias=False),
nn.BatchNorm2d(mid_channel),
nn.ReLU(),
# ReLU in ConvModule not shown in paper
depthwise_separable_conv(mid_channel, mid_channel, stride=stride),
nn.BatchNorm2d(mid_channel),
depthwise_separable_conv(mid_channel, mid_channel, stride=1),
nn.BatchNorm2d(mid_channel),
)
self.shortcut = nn.Sequential(
depthwise_separable_conv(in_channels, out_channels, stride=stride),
nn.BatchNorm2d(out_channels),
nn.Conv2d(out_channels, out_channels, 1),
nn.BatchNorm2d(out_channels),
)
self.conv2 = nn.Sequential(
nn.Conv2d(mid_channel, out_channels, kernel_size=1, stride=1, padding=0,bias=False),
nn.BatchNorm2d(out_channels)
)
self.act = nn.ReLU()
def forward(self, x):
identity = x
x = self.conv1(x)
x = self.dwconv(x)
x = self.conv2(x)
if self.shortcut is not None:
shortcut = self.shortcut(identity)
x = x + shortcut
else:
x = x + identity
x = self.act(x)
return x
if __name__ == "__main__":
x = torch.randn(3, 16, 224, 224)
net = GELayer(in_channels=16, out_channels=16, stride=2)
out = net(x)
print(out.shape)
Semantic Branch的代码:
class SemanticBranch(nn.Module):
def __init__(self, semantic_channels=(16, 32, 64, 128), in_channels=3, exp_ratio=6):
super(SemanticBranch, self).__init__()
self.in_channels = in_channels
self.semantic_channels = semantic_channels
self.semantic_stages = nn.ModuleList()
for i in range(len(semantic_channels)):
if i == 0:
self.semantic_stages.append(StemBlock(self.in_channels, semantic_channels[i]))
elif i == (len(semantic_channels) - 1):
self.semantic_stages.append(
nn.Sequential(
GELayer(semantic_channels[i - 1], semantic_channels[i], exp_ratio, 2),
GELayer(semantic_channels[i], semantic_channels[i], exp_ratio, 1),
GELayer(semantic_channels[i], semantic_channels[i], exp_ratio, 1),
GELayer(semantic_channels[i], semantic_channels[i], exp_ratio, 1)
)
)
else:
self.semantic_stages.append(
nn.Sequential(
GELayer(semantic_channels[i - 1], semantic_channels[i],
exp_ratio, 2),
GELayer(semantic_channels[i], semantic_channels[i],
exp_ratio, 1)
)
)
self.semantic_stages.append(CEBlock(semantic_channels[-1], semantic_channels[-1]))
def forward(self, x):
semantic_outs = []
for semantic_stage in self.semantic_stages:
x = semantic_stage(x)
semantic_outs.append(x)
return semantic_outs
if __name__ == "__main__":
x = torch.randn(3, 3, 224, 224)
net = SemanticBranch()
out = net(x)
print(out[0].shape)
print(out[1].shape)
print(out[2].shape)
print(out[3].shape)
print(out[4].shape)
# from torchsummary import summary
# summary(net.cuda(), (3, 224, 224))
Aggregation Layer
Aggregation Layer接受了Detail Branch和Semantic Branch的结果,通过图4中的一系列操作进行特征融合。
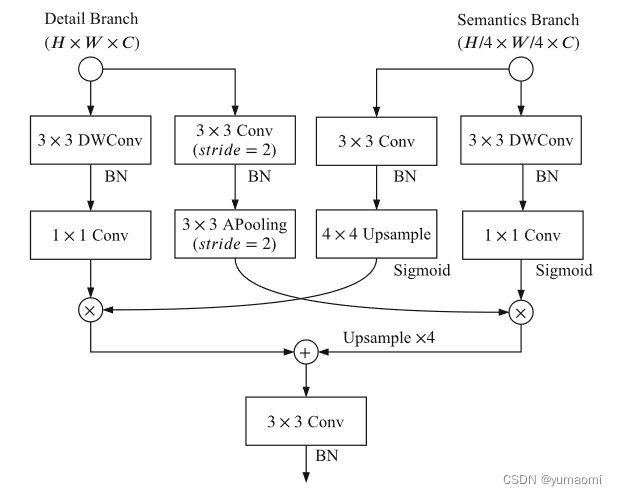
图4 Aggregation Layer结构
代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class AggregationLayer(nn.Module):
def __init__(self, in_channels, out_channels):
super(AggregationLayer, self).__init__()
self.Conv_DetailBranch_1 = nn.Sequential(
depthwise_separable_conv(in_channels, out_channels, stride=1),
nn.BatchNorm2d(out_channels),
nn.Conv2d(out_channels, out_channels, 1)
)
self.Conv_DetailBranch_2 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(out_channels),
nn.AvgPool2d(kernel_size=3, stride=2, padding=1),
)
self.Conv_SemanticBranch_1 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.Upsample(scale_factor=4, mode="bilinear", align_corners=True),
nn.Sigmoid()
)
self.Conv_SemanticBranch_2 = nn.Sequential(
depthwise_separable_conv(in_channels, out_channels, stride=1),
nn.BatchNorm2d(out_channels),
nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.Sigmoid()
)
self.conv_out = nn.Sequential(
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
)
def forward(self, Detail_x, Semantic_x):
DetailBranch_1 = self.Conv_DetailBranch_1(Detail_x)
DetailBranch_2 = self.Conv_DetailBranch_2(Detail_x)
SemanticBranch_1 = self.Conv_SemanticBranch_1(Semantic_x)
SemanticBranch_2 = self.Conv_SemanticBranch_2(Semantic_x)
out_1 = torch.matmul(DetailBranch_1, SemanticBranch_1)
out_2 = torch.matmul(DetailBranch_2, SemanticBranch_2)
out_2 = F.interpolate(out_2, scale_factor=4, mode="bilinear", align_corners=True)
out = torch.matmul(out_1, out_2)
out = self.conv_out(out)
return out
if __name__ == "__main__":
Detail_x = torch.randn(3, 56, 224, 224)
Semantic_x = torch.randn(3, 56, 224//4, 224//4)
net = AggregationLayer(in_channels=56, out_channels=122)
out = net(Detail_x, Semantic_x)
print(out.shape)
分割头SegHead
检测头的实现比较简单。
class SegHead(nn.Module):
def __init__(self, channels, num_classes):
super().__init__()
self.cls_seg = nn.Sequential(
nn.Conv2d(channels, channels, 3, padding=1),
nn.BatchNorm2d(channels),
nn.ReLU(),
nn.Conv2d(channels, num_classes, 1),
)
def forward(self, x):
return self.cls_seg(x)
Booster(auxiliary Loss)
作者在Semantic Branch中引出了几个Auxiliary Loss分支,对比了集中Auxiliary Loss组合的性能,得出如下结果。
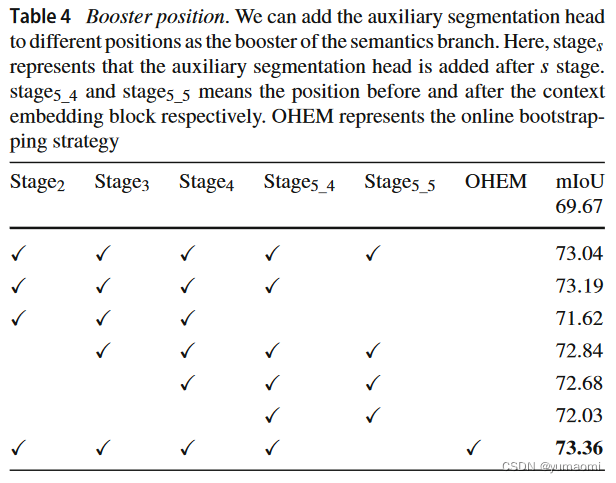
BiSeNetV2实现以及在Camvid上应用
BiSeNetV2实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class StemBlock(nn.Module):
def __init__(self, in_channels=3, out_channels=16):
super(StemBlock, self).__init__()
self.conv_in = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
self.conv_branch = nn.Sequential(
nn.Conv2d(out_channels, out_channels//2, 1),
nn.BatchNorm2d(out_channels//2),
nn.ReLU(),
nn.Conv2d(out_channels//2, out_channels, 3, stride=2, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
self.pool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False)
self.fusion = nn.Sequential(
nn.Conv2d(2*out_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
def forward(self, x):
x = self.conv_in(x)
x_branch = self.conv_branch(x)
x_downsample = self.pool(x)
out = torch.cat([x_branch, x_downsample], dim=1)
out = self.fusion(out)
return out
class depthwise_separable_conv(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super(depthwise_separable_conv, self).__init__()
self.depthwise = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=stride, padding=1, groups=in_channels)
self.pointwise = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
out = self.depthwise(x)
out = self.pointwise(out)
return out
class GELayer(nn.Module):
def __init__(self, in_channels, out_channels, exp_ratio=6, stride=1):
super(GELayer, self).__init__()
mid_channel = in_channels * exp_ratio
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1,padding=1),
nn.BatchNorm2d(in_channels),
nn.ReLU()
)
if stride == 1:
self.dwconv = nn.Sequential(
# ReLU in ConvModule not shown in paper
nn.Conv2d(in_channels, mid_channel, 3, stride=stride, padding=1, groups=in_channels),
nn.BatchNorm2d(mid_channel),
nn.ReLU(),
depthwise_separable_conv(mid_channel, mid_channel, stride=1),
nn.BatchNorm2d(mid_channel),
)
self.shortcut = None
else:
self.dwconv = nn.Sequential(
nn.Conv2d(in_channels, mid_channel, 3, stride=1, padding=1, groups=in_channels,bias=False),
nn.BatchNorm2d(mid_channel),
nn.ReLU(),
# ReLU in ConvModule not shown in paper
depthwise_separable_conv(mid_channel, mid_channel, stride=stride),
nn.BatchNorm2d(mid_channel),
depthwise_separable_conv(mid_channel, mid_channel, stride=1),
nn.BatchNorm2d(mid_channel),
)
self.shortcut = nn.Sequential(
depthwise_separable_conv(in_channels, out_channels, stride=stride),
nn.BatchNorm2d(out_channels),
nn.Conv2d(out_channels, out_channels, 1),
nn.BatchNorm2d(out_channels),
)
self.conv2 = nn.Sequential(
nn.Conv2d(mid_channel, out_channels, kernel_size=1, stride=1, padding=0,bias=False),
nn.BatchNorm2d(out_channels)
)
self.act = nn.ReLU()
def forward(self, x):
identity = x
x = self.conv1(x)
x = self.dwconv(x)
x = self.conv2(x)
if self.shortcut is not None:
shortcut = self.shortcut(identity)
x = x + shortcut
else:
x = x + identity
x = self.act(x)
return x
class CEBlock(nn.Module):
def __init__(self,in_channels=16, out_channels=16):
super(CEBlock, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.gap = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
# AdaptiveAvgPool2d 把形状变为(Batch size, N, 1, 1)后,batch size=1不能正常通过BatchNorm2d, 但是batch size>1是可以正常通过的。如果想开启BatchNorm,训练时batch size>1即可,测试时使用model.eval()即不会报错。
# nn.BatchNorm2d(self.in_channels)
)
self.conv_gap = nn.Sequential(
nn.Conv2d(self.in_channels, self.out_channels, 1, stride=1, padding=0),
# nn.BatchNorm2d(self.out_channels), 同上
nn.ReLU()
)
# Note: in paper here is naive conv2d, no bn-relu
self.conv_last = nn.Conv2d(
in_channels=self.out_channels,
out_channels=self.out_channels,
kernel_size=3,
stride=1,
padding=1)
def forward(self, x):
identity = x
x = self.gap(x)
x = self.conv_gap(x)
x = identity + x
x = self.conv_last(x)
return x
class DetailBranch(nn.Module):
def __init__(self, detail_channels=(64, 64, 128), in_channels=3):
super(DetailBranch, self).__init__()
self.detail_branch = nn.ModuleList()
for i in range(len(detail_channels)):
if i == 0:
self.detail_branch.append(
nn.Sequential(
nn.Conv2d(in_channels, detail_channels[i], 3, stride=2, padding=1),
nn.BatchNorm2d(detail_channels[i]),
nn.ReLU(),
nn.Conv2d(detail_channels[i], detail_channels[i], 3, stride=1, padding=1),
nn.BatchNorm2d(detail_channels[i]),
nn.ReLU(),
)
)
else:
self.detail_branch.append(
nn.Sequential(
nn.Conv2d(detail_channels[i-1], detail_channels[i], 3, stride=2, padding=1),
nn.BatchNorm2d(detail_channels[i]),
nn.ReLU(),
nn.Conv2d(detail_channels[i], detail_channels[i], 3, stride=1, padding=1),
nn.BatchNorm2d(detail_channels[i]),
nn.ReLU(),
nn.Conv2d(detail_channels[i], detail_channels[i], 3, stride=1, padding=1),
nn.BatchNorm2d(detail_channels[i]),
nn.ReLU()
)
)
def forward(self, x):
for stage in self.detail_branch:
x = stage(x)
return x
class SemanticBranch(nn.Module):
def __init__(self, semantic_channels=(16, 32, 64, 128), in_channels=3, exp_ratio=6):
super(SemanticBranch, self).__init__()
self.in_channels = in_channels
self.semantic_channels = semantic_channels
self.semantic_stages = nn.ModuleList()
for i in range(len(semantic_channels)):
if i == 0:
self.semantic_stages.append(StemBlock(self.in_channels, semantic_channels[i]))
elif i == (len(semantic_channels) - 1):
self.semantic_stages.append(
nn.Sequential(
GELayer(semantic_channels[i - 1], semantic_channels[i], exp_ratio, 2),
GELayer(semantic_channels[i], semantic_channels[i], exp_ratio, 1),
GELayer(semantic_channels[i], semantic_channels[i], exp_ratio, 1),
GELayer(semantic_channels[i], semantic_channels[i], exp_ratio, 1)
)
)
else:
self.semantic_stages.append(
nn.Sequential(
GELayer(semantic_channels[i - 1], semantic_channels[i],
exp_ratio, 2),
GELayer(semantic_channels[i], semantic_channels[i],
exp_ratio, 1)
)
)
self.semantic_stages.append(CEBlock(semantic_channels[-1], semantic_channels[-1]))
def forward(self, x):
semantic_outs = []
for semantic_stage in self.semantic_stages:
x = semantic_stage(x)
semantic_outs.append(x)
return semantic_outs
class AggregationLayer(nn.Module):
def __init__(self, in_channels, out_channels):
super(AggregationLayer, self).__init__()
self.Conv_DetailBranch_1 = nn.Sequential(
depthwise_separable_conv(in_channels, out_channels, stride=1),
nn.BatchNorm2d(out_channels),
nn.Conv2d(out_channels, out_channels, 1)
)
self.Conv_DetailBranch_2 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(out_channels),
nn.AvgPool2d(kernel_size=3, stride=2, padding=1),
)
self.Conv_SemanticBranch_1 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.Upsample(scale_factor=4, mode="bilinear", align_corners=True),
nn.Sigmoid()
)
self.Conv_SemanticBranch_2 = nn.Sequential(
depthwise_separable_conv(in_channels, out_channels, stride=1),
nn.BatchNorm2d(out_channels),
nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.Sigmoid()
)
self.conv_out = nn.Sequential(
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
)
def forward(self, Detail_x, Semantic_x):
DetailBranch_1 = self.Conv_DetailBranch_1(Detail_x)
DetailBranch_2 = self.Conv_DetailBranch_2(Detail_x)
SemanticBranch_1 = self.Conv_SemanticBranch_1(Semantic_x)
SemanticBranch_2 = self.Conv_SemanticBranch_2(Semantic_x)
out_1 = torch.matmul(DetailBranch_1, SemanticBranch_1)
out_2 = torch.matmul(DetailBranch_2, SemanticBranch_2)
out_2 = F.interpolate(out_2, scale_factor=4, mode="bilinear", align_corners=True)
out = torch.matmul(out_1, out_2)
out = self.conv_out(out)
return out
class SegHead(nn.Module):
def __init__(self, channels, num_classes):
super().__init__()
self.cls_seg = nn.Sequential(
nn.Conv2d(channels, channels, 3, padding=1),
nn.BatchNorm2d(channels),
nn.ReLU(),
nn.Conv2d(channels, num_classes, 1),
)
def forward(self, x):
return self.cls_seg(x)
class BiSeNetV2(nn.Module):
def __init__(self,in_channels=3,
detail_channels=(64, 64, 128),
semantic_channels=(16, 32, 64, 128),
semantic_expansion_ratio=6,
aggregation_channels=128,
out_indices=(0, 1, 2, 3, 4),
num_classes = 3):
super(BiSeNetV2, self).__init__()
self.in_channels = in_channels
self.detail_channels = detail_channels
self.semantic_expansion_ratio = semantic_expansion_ratio
self.semantic_channels = semantic_channels
self.aggregation_channels = aggregation_channels
self.out_indices = out_indices
self.num_classes = num_classes
self.detail = DetailBranch(detail_channels=self.detail_channels, in_channels=self.in_channels)
self.semantic = SemanticBranch(semantic_channels=self.semantic_channels, in_channels=self.in_channels,exp_ratio=self.semantic_expansion_ratio)
self.AggregationLayer = AggregationLayer(in_channels=self.aggregation_channels, out_channels=self.aggregation_channels)
self.seg_head_aggre = SegHead(semantic_channels[-1], self.num_classes)
self.seg_heads = nn.ModuleList()
self.seg_heads.append(self.seg_head_aggre)
for channel in semantic_channels:
self.seg_heads.append(SegHead(channel, self.num_classes))
def forward(self, x):
_, _, h, w = x.size()
x_detail = self.detail(x)
x_semantic_lst = self.semantic(x)
x_head = self.AggregationLayer(x_detail, x_semantic_lst[-1])
outs = [x_head] + x_semantic_lst[:-1]
outs = [outs[i] for i in self.out_indices]
out = tuple(outs)
seg_out = []
for index, stage in enumerate(self.seg_heads):
seg_out.append(F.interpolate(stage(out[index]),size=(h,w), mode="bilinear", align_corners=True))
return seg_out
Camvid dataset
# 导入库
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
import warnings
warnings.filterwarnings("ignore")
from PIL import Image
import numpy as np
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
torch.manual_seed(17)
# 自定义数据集CamVidDataset
class CamVidDataset(torch.utils.data.Dataset):
"""CamVid Dataset. Read images, apply augmentation and preprocessing transformations.
Args:
images_dir (str): path to images folder
masks_dir (str): path to segmentation masks folder
class_values (list): values of classes to extract from segmentation mask
augmentation (albumentations.Compose): data transfromation pipeline
(e.g. flip, scale, etc.)
preprocessing (albumentations.Compose): data preprocessing
(e.g. noralization, shape manipulation, etc.)
"""
def __init__(self, images_dir, masks_dir):
self.transform = A.Compose([
A.Resize(448, 448),
A.HorizontalFlip(),
A.VerticalFlip(),
A.Normalize(),
ToTensorV2(),
])
self.ids = os.listdir(images_dir)
self.images_fps = [os.path.join(images_dir, image_id) for image_id in self.ids]
self.masks_fps = [os.path.join(masks_dir, image_id) for image_id in self.ids]
def __getitem__(self, i):
# read data
image = np.array(Image.open(self.images_fps[i]).convert('RGB'))
mask = np.array( Image.open(self.masks_fps[i]).convert('RGB'))
image = self.transform(image=image,mask=mask)
return image['image'], image['mask'][:,:,0]
def __len__(self):
return len(self.ids)
# 设置数据集路径
DATA_DIR = r'database/camvid/camvid/' # 根据自己的路径来设置
x_train_dir = os.path.join(DATA_DIR, 'train_images')
y_train_dir = os.path.join(DATA_DIR, 'train_labels')
x_valid_dir = os.path.join(DATA_DIR, 'valid_images')
y_valid_dir = os.path.join(DATA_DIR, 'valid_labels')
train_dataset = CamVidDataset(
x_train_dir,
y_train_dir,
)
val_dataset = CamVidDataset(
x_valid_dir,
y_valid_dir,
)
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True,drop_last=True)
val_loader = DataLoader(val_dataset, batch_size=16, shuffle=True,drop_last=True)
Train
model = BiSeNetV2(num_classes=33)
from d2l import torch as d2l
from tqdm import tqdm
import pandas as pd
import monai
# training loop 100 epochs
epochs_num = 100
# 选用SGD优化器来训练
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
schedule = monai.optimizers.LinearLR(optimizer, end_lr=0.05, num_iter=int(epochs_num*0.75))
# 损失函数选用多分类交叉熵损失函数
lossf = nn.CrossEntropyLoss(ignore_index=255)
def evaluate_accuracy_gpu(net, data_iter, device=None):
if isinstance(net, nn.Module):
net.eval() # Set the model to evaluation mode
if not device:
device = next(iter(net.parameters())).device
# No. of correct predictions, no. of predictions
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# Required for BERT Fine-tuning (to be covered later)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
output = net(X)
pred = output[0]
metric.add(d2l.accuracy(pred, y), d2l.size(y))
return metric[0] / metric[1]
# 训练函数
def train_ch13(net, train_iter, test_iter, loss, optimizer, num_epochs, schedule, swa_start=swa_start, devices=d2l.try_all_gpus()):
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1], legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
# 用来保存一些训练参数
loss_list = []
train_acc_list = []
test_acc_list = []
epochs_list = []
time_list = []
lr_list = []
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples,
# no. of predictions
metric = d2l.Accumulator(4)
for i, (X, labels) in enumerate(train_iter):
timer.start()
if isinstance(X, list):
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
gt = labels.long().to(devices[0])
net.train()
optimizer.zero_grad()
result = net(X)
pred = result[0]
seg_loss = loss(result[0], gt)
aux_loss_1 = loss(result[1], gt)
aux_loss_2 = loss(result[2], gt)
aux_loss_3 = loss(result[3], gt)
aux_loss_4 = loss(result[4], gt)
loss_sum = seg_loss + 0.2*aux_loss_1 + 0.2*aux_loss_2 + 0.2*aux_loss_3 + 0.2*aux_loss_4
l = loss_sum
loss_sum.sum().backward()
optimizer.step()
acc = d2l.accuracy(pred, gt)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,(metric[0] / metric[2], metric[1] / metric[3], None))
if optimizer.state_dict()['param_groups'][0]['lr']>0.05:
schedule.step()
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f"epoch {epoch+1}/{epochs_num} --- loss {metric[0] / metric[2]:.3f} --- train acc {metric[1] / metric[3]:.3f} --- test acc {test_acc:.3f} --- lr {optimizer.state_dict()['param_groups'][0]['lr']} --- cost time {timer.sum()}")
#---------保存训练数据---------------
df = pd.DataFrame()
loss_list.append(metric[0] / metric[2])
train_acc_list.append(metric[1] / metric[3])
test_acc_list.append(test_acc)
epochs_list.append(epoch+1)
time_list.append(timer.sum())
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
df['epoch'] = epochs_list
df['loss'] = loss_list
df['train_acc'] = train_acc_list
df['test_acc'] = test_acc_list
df["lr"] = lr_list
df['time'] = time_list
df.to_excel("savefile/BiseNetv2_camvid.xlsx")
#----------------保存模型-------------------
if np.mod(epoch+1, 5) == 0:
torch.save(net.state_dict(), f'checkpoints/BiseNetv2_{epoch+1}.pth')
# 保存下最后的model
torch.save(net.state_dict(), f'checkpoints/BiseNetv2_last.pth')
train_ch13(model, train_loader, val_loader, lossf, optimizer, epochs_num, schedule=schedule)
Result
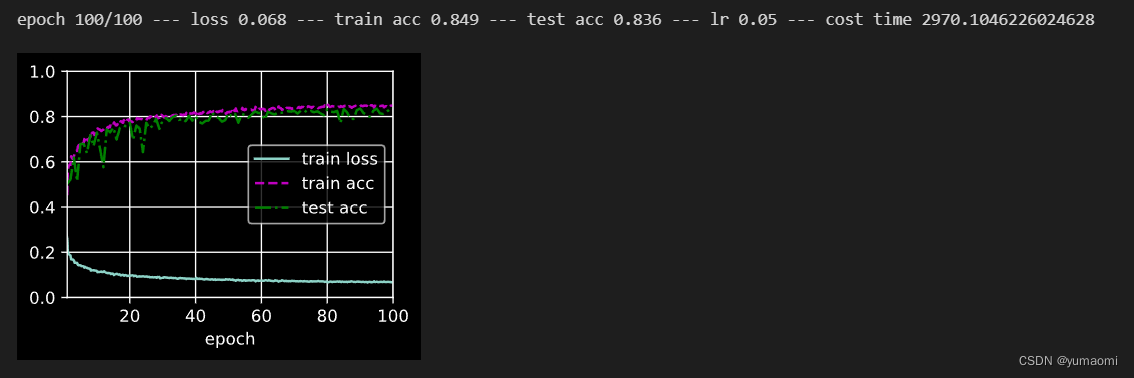
版权归原作者 yumaomi 所有, 如有侵权,请联系我们删除。