
Meta公司(原Facebook)在今年9月29日首次推出一款人工智能系统模型:Make-A-Video,可以从给定的文字提示生成短视频。
Make-A-Video研究基于文本到图像生成技术的最新进展,该技术旨在实现文本到视频的生成,可以仅用几个单词或几行文本生成异想天开、独一无二的视频,将无限的想象力带入生活。比如一句“三马奔腾”生成视频:
初步预览地址:https://makeavideo.studio/
文章链接:https://arxiv.org/abs/2209.14792
本篇文章将根据论文边解读边介绍文本生成视频的效果、技术、发展和理解。
一、摘要
我们提出了Make-A-Video——一种直接将文本到图像(T2I)生成的最新巨大进展转换为文本到视频(T2V)的方法。我们的直觉很简单:从成对的文本图像数据中了解世界的样子和描述方式,并从无监督的视频片段中了解世界是如何移动的。Make-A-Video有三个优点:(1)它加快了T2V模型的训练(它不需要从头开始学习视觉和多模态表示),(2)它不需要成对的文本视频数据,以及(3)生成的视频继承了当今图像生成模型的广度(审美、幻想描述等方面的多样性)。我们设计了一种简单而有效的方法,用新颖有效的时空模块建立T2I模型。首先,我们分解全时间U-Net和注意张量,并在空间和时间上近似它们。其次,我们设计了一个时空流水线来生成高分辨率和帧速率视频,其中包括视频解码器、插值模型和两个超分辨率模型,可以实现除T2V以外的各种应用。Make-a-video在时空分辨率、对文本的忠实度和质量等各个方面都开创了文本到视频生成的最新技术,由定性和定量测量确定。
二、文本生成视频
2.1、效果预览
模型可以为不同的视觉概念集生成具有连贯运动的高质量视频,如:
一只穿着红色斗篷超级英雄服装的狗,在天空中飞翔。

一对年轻夫妇在大雨中行走

猫手里拿着遥控器看电视

还有一些其他的例子:

2.2、难点:没有文本-视频对的数据集
互联网为研究收集了数十亿计的文本-图像数据对,这是文本生成图像能够成功建模的基石之一。然而,由于无法轻松收集类似大小的文本-视频数据集,为文本生成视频复制这种成功是极其有限的,而且目前都已经存在了可以生成图像的模型,从头开始训练文本生成视频模型也是极其浪费资源的。
无监督学习使网络能够从数量级的更多数据中学习,这些大量的数据对于学习世界上更微妙、更不常见的概念的表示非常重要,以这种方式预先训练的模型比单独以监督方式训练的模型具有更高的性能,受这些动机的启发,Make-A-Video孕育而生。
Make-A-Video利用T2I模型学习文本和视觉世界之间的对应关系,并使用未标记(未配对)视频数据的无监督学习来学习真实运动。
2.2、难点:推断动作和事件
文本生成图像都是静态的,人们通常可以从静态图像推断出动作和事件,但是计算机并不具备这种能力,且描述图像的文本并不能完全展现这种动作和事件细节。
同样,作者使用了无监督学习,即使没有文字描述,无监督学习也足以了解世界上不同的实体是如何移动和相互作用的。
Make-A-Video开创了T2V新一代的最新技术。
作者使用函数保持变换,在模型初始化阶段扩展了空间层,以包含时间信息。扩展的时空网络包括新的注意力模块,可以从视频集合中学习时间世界动态。该程序通过将先前训练的T2I网络中的知识瞬间转移到新的T2V网络中,大大加快了T2V培训过程。作者训练空间超分辨率模型以及帧插值模型,提高生成视频的分辨率,并支持更高(可控)的帧速率。
2.3、主要贡献
- 我们利用联合文本-图像先验来绕过对成对文本-视频数据的需要,这反过来又允许我们潜在地扩展到更大数量的视频数据。
- 我们提出了空间和时间上的超分辨率策略,首次在用户提供文本输入的情况下生成高清、高帧速率视频。
- 我们根据现有T2V系统评估Make-A-Video,并提出:(A)定量和定性测量的最新结果,以及(b)比现有T2V文献更全面的评估。
三、模型
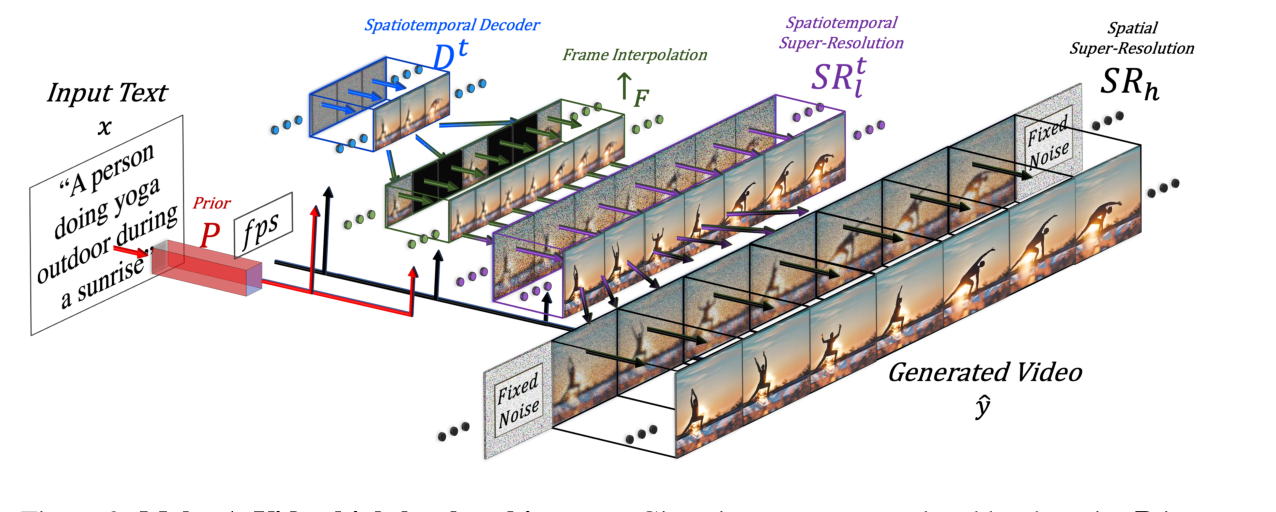
主要框架如上图所示,Make-A-Video由三个主要组件组成:(i)基于文本图像对训练的基本T2I模型(ii)时空卷积层和注意力层以及(iii)用于提高帧率的帧插值网络和两个用来提升画质的超分网络
Make-A-Video的最终T2V推理方案(如图2所示)可以表述为:
y
t
^
=
S
R
h
∘
S
R
l
t
∘
↑
F
∘
D
t
∘
P
∘
(
x
^
,
C
x
(
x
)
)
\hat{y_{t}}=\mathrm{SR}_{h} \circ \mathrm{SR}_{l}^{t} \circ \uparrow_{F} \circ \mathrm{D}^{t} \circ \mathrm{P} \circ\left(\hat{x}, \mathrm{C}_{x}(x)\right)
yt^=SRh∘SRlt∘↑F∘Dt∘P∘(x^,Cx(x))
其中,ˆyt是生成的视频,SRh、SRl是空间和时空超分辨率网络(第3.2节),↑F是帧插值网络,Dt是时空解码器,P是先验,ˆx是BPE编码的文本,Cx是CLIP文本编码器,x是输入文本
3.1、文本生成图像
在添加时空信息前,模型的主干是一个基于文本生成图像的T2I模型。使用以下网络从文本生成高分辨率图像:(i)一个先前的网络P(ii)一个解码器网络D,以及(iii)两个超分辨率网络,将生成的图像分辨率分别增加到256×256和768×768像素,最终生成图像。
3.2、时空层次
为了将二维条件网络(即只能生成2d图像)扩展到时间维度,作者修改了两个关键构建块(卷积层和注意力层),这两个构建块现在不仅需要空间维度,还需要时间维度,以便生成视频。
,然后基于U-Net的扩散网络进行时间修改,利用时空解码器Dt生成16个RGB帧,然后通过在16个生成的帧和超分辨率网络SRtl之间插值来增加有效帧速率。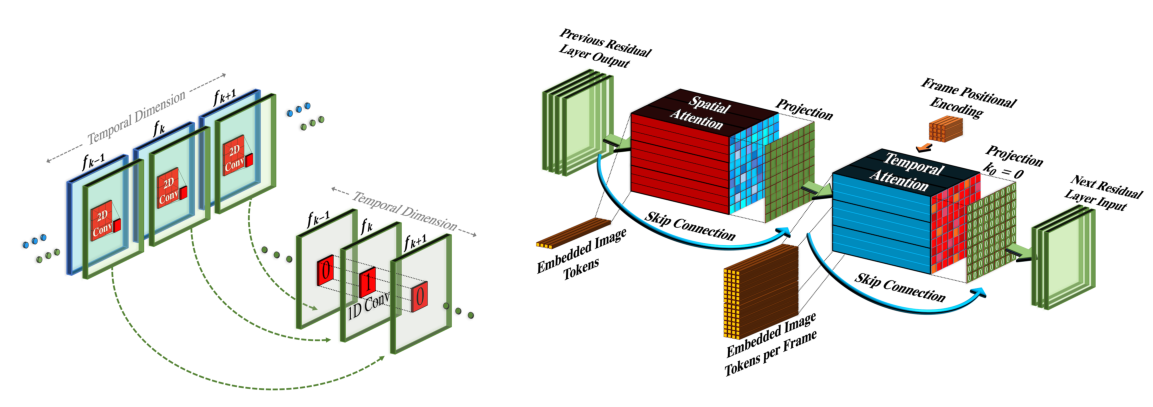
超分辨率包含幻觉信息。为了不出现闪烁的伪影,幻觉必须在帧之间保持一致。因此,我们的SRtl模块跨空间和时间维度运行。由于内存和计算的限制以及高分辨率视频数据的稀缺性,将SRh扩展到时间维度是一个挑战。因此,SRh仅沿空间维度运行。但为了在帧之间产生一致的细节幻觉,我们对每个帧使用相同的噪声初始化
3.3、伪三维卷积层
受可分离卷积的启发(Cholet,2017),我们在每个2D卷积(conv)层之后叠加一个1D卷积,如图3所示。这有助于空间轴和时间轴之间的信息共享,而不会屈服于3D conv层的繁重计算负载。此外,它在预先训练的2D conv层和新初始化的1D conv层之间创建了一个具体分区,允许我们从头开始训练时间卷积,同时保留空间卷积权重中先前学习的空间知识。
伪三维卷积层定义为:
Conv
P
3
D
(
h
)
:
=
Conv
1
D
(
Conv
2
D
(
h
)
∘
T
)
∘
T
,
\operatorname{Conv}_{P 3 D}(h):=\operatorname{Conv}_{1 D}\left(\operatorname{Conv}_{2 D}(h) \circ T\right) \circ T,
ConvP3D(h):=Conv1D(Conv2D(h)∘T)∘T,
3.4 、伪3D注意层
T2I网络的一个重要组成部分是注意层,作者将维度分解策略扩展到了注意力层。在每个(预先训练的)空间注意层之后,叠加一个时间注意层,与卷积层一样,它近似于一个完整的时空注意层。伪三维注意层定义为:
ATTN
P
3
D
(
h
)
=
unflatten
(
A
T
T
N
1
D
(
A
T
T
N
2
D
(
flatten
(
h
)
)
∘
T
)
∘
T
)
.
\operatorname{ATTN}_{P 3 D}(h)=\text { unflatten }\left(A T T N_{1 D}\left(A T T N_{2 D}(\text { flatten }(h)) \circ T\right) \circ T\right) .
ATTNP3D(h)= unflatten (ATTN1D(ATTN2D( flatten (h))∘T)∘T).
帧速率调节。除了T2I条件之外,类似于CogVideo(Hong等人,2022),作者还添加了一个额外的条件参数fps,表示生成的视频中每秒的帧数。对每秒不同帧数的条件进行调节,使额外的增强方法能够在训练时处理有限的可用视频量,并在推理时对生成的视频提供额外的控制。
3.5、帧插值网络
除了时空修改外,作者还训练了一个新的屏蔽帧内插和外推网络↑F,能够通过帧插值来增加生成视频的帧数,以获得更平滑的生成视频,或者通过帧前/帧后外推来延长视频长度。为了提高内存和计算限制内的帧速率,我们对屏蔽帧插值任务的时空解码器Dt进行微调,通过对屏蔽输入帧进行零填充,实现视频上采样。
3.6、训练
上述Make-A-Video的不同组件都是独立训练的,唯一接收文本作为输入的组件是之前的P。
解码器接收CLIP图像嵌入作为输入,而超分辨率组件接收降采样图像作为训练期间的输入。在对图像进行训练后,我们添加并初始化新的时间层,并在未标记的视频数据上对其进行微调。从原始视频中采样16帧,f ps的随机范围为1到30。我们使用beta函数进行采样,在训练解码器时,从较高的FPS范围(较少运动)开始,然后过渡到较低的FPS幅度(较多运动)。屏蔽帧插值组件从时间解码器进行微调。
四、实验
因为是独立训练的,所以每个组件训练的数据集都不同
数据集:NSFW、HD-VILA-100M、WebVid-10M、HD-VILA-10M、UCF-101、MSR-VTT
定量评估:Frechet Video Distance (FVD)、 Inception Score(IS)、Frechet Inception Distance (FID) 、CLIPSIM (视频帧和文本之间的平均CLIP相似性)
人工评估:在Amazon Mechanical Turk(AMT)收集了包含300个提示的评估集,询问注释者,如果有T2V系统,他们会对生成什么感兴趣。另外使用Imagen的DrawBench提示进行人类评估。我们评估视频质量和文本视频忠诚度。对于视频质量,我们以随机顺序显示两个视频,并询问注释者哪一个质量更高。
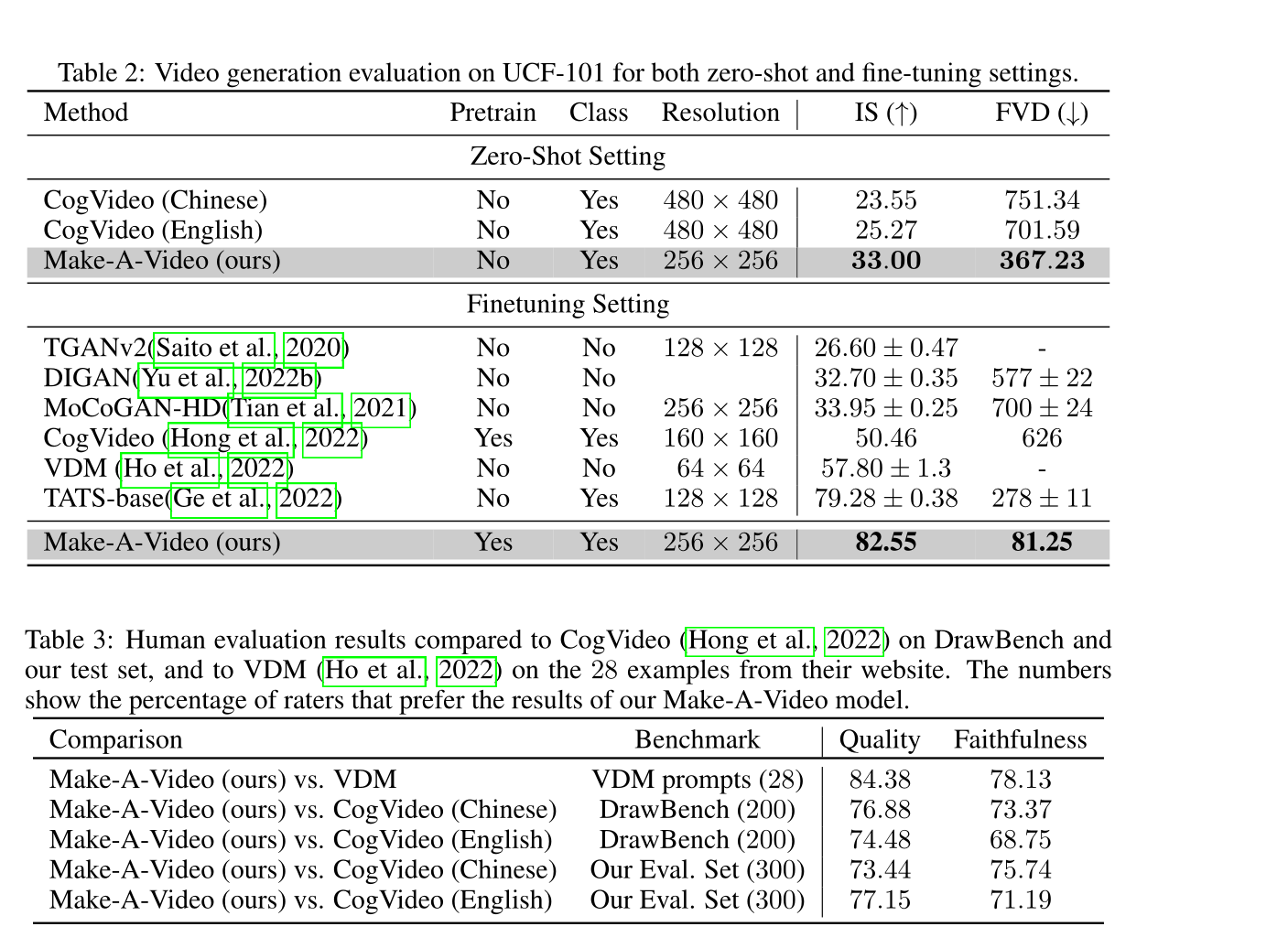
五、定量结果
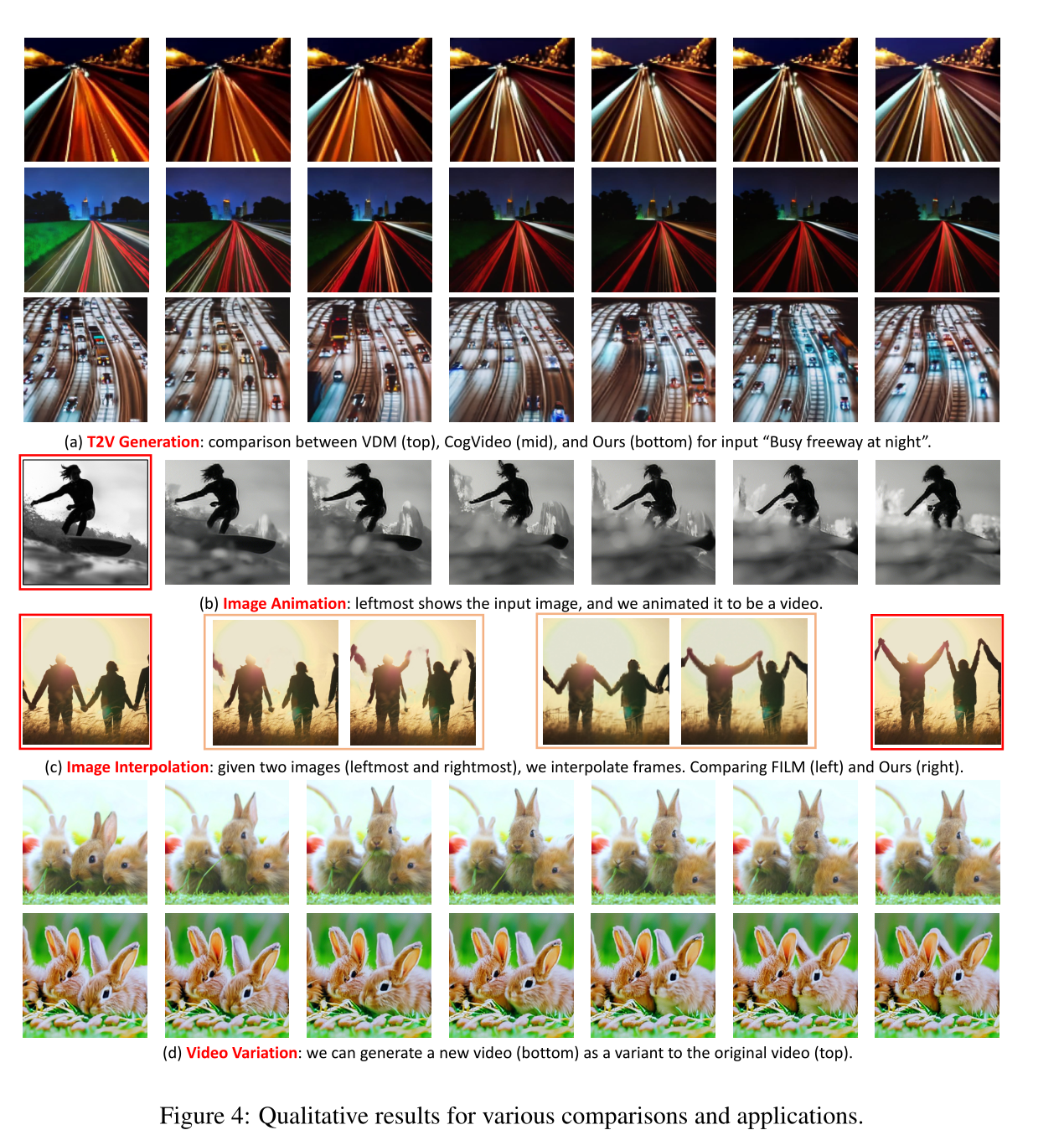
六、定性结果
七、讨论
向我们周围的世界学习是人类智力的最大优势之一。正如我们通过观察很快学会识别人、地点、事物和行为一样,如果生成系统能够模仿人类的学习方式,那么它们将更具创造性和实用性。且使用无监督学习学习动态的世界,还有助于研究人员摆脱对标记数据的依赖。
作者在最后提到的几个技术限制:
- 无法学习文本和只能在视频中推断出的现象之间的关联。如何整合这些内容(例如,生成一段某人从左到右或从右到左挥手的视频)
- 生成更长的视频,其中包含多个场景和事件
- 描述更详细的故事。
- 模型已经学习并可能夸大了社会偏见,包括有害的偏见。
最后
💖 个人简介:人工智能领域研究生,目前主攻文本生成图像(text to image)方向
📝 关注我:中杯可乐多加冰
🔥 限时免费订阅:文本生成图像T2I专栏
🎉 支持我:点赞👍+收藏⭐️+留言📝
版权归原作者 中杯可乐多加冰 所有, 如有侵权,请联系我们删除。