
1 常用GPU显存不足时的各种Trick
1)监控GPU
监控GPU最常用的当然是nvidia-smi,但有一个工具能够更好的展示信息:gpustat
nvidia-smi
watch --color -n1 gpustat -cpu #动态事实监控GPU
2)估计模型显存
GPU的内存占用率主要由两部分组成。
一是**优化器参数**,**模型自身的参数**,**模型中间每一层的缓存**,都会在内存中开辟空间来进行保存,所以模型本身会占用很大一部分内存。模型自身的参数指的就是各个网络层的 Weight 和Bias,这部分显存在模型加载完成之后就会被占用, 注意到的是,有些层是有参数的,如CNN, RNN;而有些层是无参数的, 如激活层, 池化层等。从Pytorch 的角度来说,当你执行
model.to(device)
时, 你的模型就加载完毕,此时你的模型就已经加载完成了。
二是**batch size的大小**,在模型结构固定的情况下,尽量将batch size设置大,充分利用GPU的内存。
计算模型参数量:torchsummary
import torch as t
from torchsummary import summary
rgb = t.randn(1,3,352,480).cuda()
net = FCN(12).cuda()
out = net(rgb)
summary(net,input_size=(3,352,480),batch_size=1)
3)显存不足时的Trick
此处不讨论多GPU,分布式计算等情况,只讨论一些常规的Trick。
降低batch size
适当降低batch size,则模型每层的输入输出就会成线性减少, 效果相当明显。batch_size是训练神经网络中的一个重要的超参数,该值决定了一次将多少数据送入神经网络参与训练。在显存允许的前提下, batch_size应该越大越好,可以修改图像输入尺寸达到平衡。即,在合理范围内调整图像尺寸,使显存尽可能占满, batch_size尽可能大。
选择更小的数据类型
一般默认情况下,整个网络中采用的是32位的浮点数,如果切换到 16位的浮点数,其显存占用量将接近呈倍数递减。
精简模型
在设计模型时,适当的精简模型,如原来两层的LSTM转为一层;原来使用LSTM, 现在使用GRU;减少卷积核数量;尽量少的使用 Linear ,全连接层参数较多,较少参数或则不用全连接层。使用全局平均池化进行替代等。
数据角度
对于文本数据来说,长序列所带来的参数量是呈线性增加的, 适当的缩小序列长度可以极大的降低参数量。
total_loss
考虑到loss本身是一个包含梯度信息的tensor,因此,正确的求损失和的方式为:
total_loss += loss.item()
释放不需要的张量和变量
采用del释放你不再需要的张量和变量,要求我们在写模型的时候注意变量的使用,不要随心所欲,漫天飞舞。
Relu 的 inplace 参数
激活函数
Relu()
有一个默认参数
inplace
,默认为Flase, 当设置为True的时候,我们在通过
relu()
计算得到的新值不会占用新的空间而是直接覆盖原来的值,这表示设为True, 可以节省一部分显存。
梯度累积
首先了解一些Pytorch的基本知识:
在Pytorch 中,当我们执行
loss.backward()时, 会为每个参数计算梯度,并将其存储在 paramter.grad 中, 注意到,paramter.grad是一个张量, 其会累加每次计算得到的梯度。在 Pytorch 中, 只有调用
optimizer.step()时才会进行梯度下降更新网络参数。我们知道, batch size 与占用显存息息相关,但有时候我们的batch size 又不能设置的太小,这咋办呢?答案就是梯度累加。
传统的训练:
for i,(feature,target) in enumerate(train_loader):
outputs = model(feature) #前向传播
loss = criterion(outputs,target) #计算损失
optimizer.zero_grad() #清空梯度
loss.backward() #计算梯度
optimizer.step() #反向传播,更新网络参数
加入梯度累加之后的代码如下:
for i,(features,target) in enumerate(train_loader):
outputs = model(images) #前向传播
loss = criterion(outputs,target) #计算损失
loss = loss/accumulation_steps #可选,如果损失要在训练样本上取平均
loss.backward() #计算梯度
if ((i+1)%accumulation_steps) == 0:
optimizer.step() #反向传播,更新网络参数
optimizer.zero_grad() #清空梯度
** **我们发现,梯度累加本质上就是累加
accumulation_steps
个
batchsize
或accumulationsteps
的梯度, 再根据累加的梯度来更新网络参数,以达到真实梯度类似
batch_size
的效果。在使用时,需要注意适当的扩大学习率。
更详细来说, 我们假设
batch size = 4
,
accumulation steps = 8
, 梯度积累首先在前向传播的时候以
batch_size=4
来计算梯度,但是不更新参数,将梯度积累下来,直到我们计算了
accumulation steps
个 batch, 我们再更新参数。其实本质上就等价于:
真正的 batch_size = batch_size * accumulation_steps
梯度积累能很大程度上缓解GPU显存不足的问题,推荐使用。
梯度检查点
梯度检查点是一种以时间换空间的方法,通过减少保存的激活值压缩模型占用空间,但是在计算梯度时必须重新计算没有存储的激活值。详情参考:陈天奇的 Training Deep Nets with Sublinear Memory Cost
混合精度训练
混合精度训练在单卡和多卡情况下都可以使用,通过cuda计算中的half2类型提升运算效率。一个half2类型中会存储两个FP16的浮点数,在进行基本运算时可以同时进行,因此FP16的期望速度是FP32的两倍。
分布式训练Distribution Training
数据并行 Data Parallelism
模型并行 Model Parallelism
4)提高GPU内存利用率
当没有设置好CPU的线程数时,Volatile GPU-Util是在反复跳动的,0% → 95% → 0%。这其实是GPU在等待数据从CPU传输过来,当从总线传输到GPU之后,GPU逐渐开始计算,利用率会突然升高,但是GPU的算力很强大,0.5秒就基本能处理完数据,所以利用率接下来又会降下去,等待下一个batch的传入。
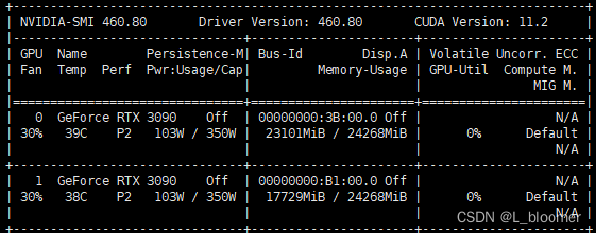
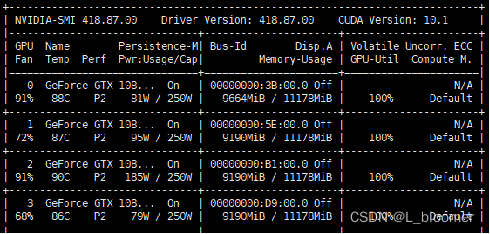
GPU会很快算完给进去的数据,利用率的主要瓶颈在CPU的数据吞吐量上面,解决方法:
配置更强大的内存条,配合更好的CPU;
在PyTorch的Dataloader上做更改和优化,包括num_workers,pin_memory,会提升速度
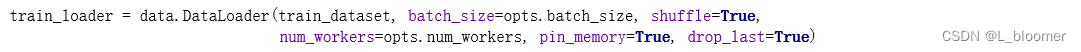
num_workers
为了提高利用率,首先要将num_workers设置得体,4、8、16是几个常选的参数。经过测试,将num_workers设置的非常大,如24、32等,其效率反而降低,因为模型需要将数据平均分配到几个子线程去进行预处理,分发等数据操作,设高了反而影响效率。当然,线程数设置为1,是单个CPU来进行数据的预处理和传输给GPU,效率也会低。
pin_memory
当服务器或者电脑的内存较大,性能较好的时候,建议打开pin_memory。该参数为True时可以直接映射到GPU的相关内存块上,省掉了一点数据传输时间。
2 数据处理及算法角度提高利用率
以医学图像分割算法为例**,**从算法工程化的角度出发,探讨算法流程的设计、模型的训练和部署,使设计的分割算法能够落地,可以考虑**多阶段分割**、**合理的图像分块**、**模型优化**及**模型训练技巧**来**提高GPU显存的利用率**。
医学影像数据是多样性的,如何进行预处理,然后送入网络进行训练,可选的方案比较灵活,我们就来探讨一下处理医学影像数据的常用方式。
不同设备厂商、医院、医生的差异,导致扫描的胸部CT影像存在较大的差异。扫描的身体范围差异较大,包括胸部、腹部和骨盆。不同设备扫描的图像分辨率差异也较大。个体差异导致影像中器官的形状和大小差异较大。综合以上因素,最终扫描重建的CT影像的图像矩阵差异大,尤其Z轴图像大小从515到2024变化。针对CT影像特点,可采用以下的数据处理方法:**固定大小****/****固定分辨率**;**整体输入****/****分块输入**,各个方法的优缺点如下:
固定大小
优点:不同case的显存占用一致,可多batch的模型训练和推理;
缺点:图像缩放到固定大小会导致目标的变形
固定分辨率
优点:能够保留人体器官的尺度信息;
缺点:不同case的显存占用不一致,存在out of memory(OM)的风险。同时单卡只能采用one batch的方式进行训练和推理
输入整图
优点:能够保留图像的全局上下文信息;算法的预处理和后处理逻辑相对简单
缺点:对GPU显存的依赖性比较高
分块输入
优点:增加了数据的多样性;能够灵活的利用GPU显存
缺点:丢失了目标的上下文信息;不合理的图像分块会导致图像块边缘处的目标分割效果欠佳。采用overlap的图像分块也会增加运算量;算法预处理和后处理逻辑更加复杂。
采用多阶段算法(定位+分割)解决扫描范围的差异,例如肺分割
解决方案如下:
采用二阶段分割算法,第一阶段采用低分辨率的整图作为输入,实现肺区域的定位;第二阶段采用高分辨率的分块图像(分左肺和右肺)作为输入,实现肺分割。算法流程如下:
1)二阶段级联3D UNet,第一阶段粗分割模型(比如spacing=2mm)实现肺区域定位,第二阶段细分割模型(比如 spacing=1mm)实现肺分割。粗分割过程处理速度较快,增加的时间在可接受的范围;粗分割的准确率对细分割的影响较低,由此可以尽可能降低粗分割模型的复杂度。
2)根据人体解剖结构对图像进行切块处理,最后对分块分割结果进行合并。根据第一阶段的肺定位结果,裁剪背景区域,按照人体解剖结构特点对CT影像进行切块,切分为左肺和右肺。同时保证肺处于图像块的中心,消除目标处于图像块的边缘导致的分割效果变差。这样保留了单肺的完整性,降低了上下文信息的丢失,增加了数据的多样性。当然除了图像切块,也可以对网络切块,此方案并未采用。
3)降低显存占用的网络结构设计,采用bottleneck block、降低Unet深度(三次下采样)、降低初始卷积的宽度;为模型或模型的一部分设置checkpoint,检查点用计算换内存。检查点部分并不保存中间激活值,而是在反向传播时重新计算它们;混合精度训练减少显存占用,实现半精度推理的加速;分布式训练解决各个GPU显卡负载不均衡问题,提高显存的利用率。
4)模型并行。模型并行的高级思想是将模型的不同子网放置到不同的设备上,并相应地实现该forward方法以在设备之间移动中间输出。由于模型的一部分只能在任何单个设备上运行,因此一组设备可以共同为更大的模型服务。这里仅展示模型并行的思想,具体可参考模型并行最佳实践
5)spacing处理:不同CT扫描的spacing存在差异;CT扫描的x,y,z轴spacing不一致。
针对所有CT图像的spacing存在差异,可以将其归一化到同一分布(比如平均spacing)。但是对于长尾数据,经过归一化,数据原始特征将发生较大变化,需要注意resample方法。如果spacing满足均匀分布,可采用多尺度spacing训练,或设计多尺度spacing模型。在推理时,增加条件判断,不同spacing的数据采用不同的模型。除此之外,可以采用从粗到细、固定大小的分割pipeline。虽然采用固定大小会导致图像形变,但通过粗分割定位能够消除不同的CT扫描差异(扫描范围、图像spacing、个体差异),降低图像形变。细分割采用固定尺度,实现目标的分割。
针对x,y,z轴spacing不一致的问题,可以resample到各项同性或者各项异性。基于最长轴的spacing和size,设置目标图像的spacing和size,进行归一化,对其中不足目标大小的图像轴,可以扩大crop的范围,或者采用零值padding。
参考:
GPU 显存不足怎么办
显存不够,如何训练大型神经网络
PyTorch中在反向传播前为什么要手动将梯度清零?
如何破解医学影像分析算法显存不足的困境
版权归原作者 L_bloomer 所有, 如有侵权,请联系我们删除。