
23年8月新加坡技术和设计大学发表的综述,“AIGC for Various Data Modalities: A Survey“,讨论多种模态的AIGC技术调研。
AI 生成内容 (AIGC) 方法旨在使用 AI 算法生成文本、图像、视频、3D 资产和其他媒体。由于其广泛的应用和最近工作的潜力,AIGC的发展最近引起了很多关注,并且已经为各种数据模态开发了AIGC方法,例如图像,视频,文本,3D形状(如体素、点云、网格和神经隐式场)、3D场景,3D人类化身(包括身体和头部的avatar), 3D 运动和音频 – 每种运动都有不同的特征和挑战。此外,跨模态AIGC方法也有许多重大发展,其中生成方法可以在一种模态中接收条件输入,并在另一种模态中产生输出。示例包括从各种模态到图像、视频、3D 形状、3D 场景、3D 化身(身体和头部)、3D 运动(骨架和化身)和音频等模态。
本文全面回顾不同数据模态(包括单模态和交叉模态方法)的AIGC方法,重点介绍每种环境中的各种挑战,代表性工作和最近的技术方向。还以各种方式展示几个基准数据集的比较结果。此外,还讨论了挑战和潜在的未来研究方向。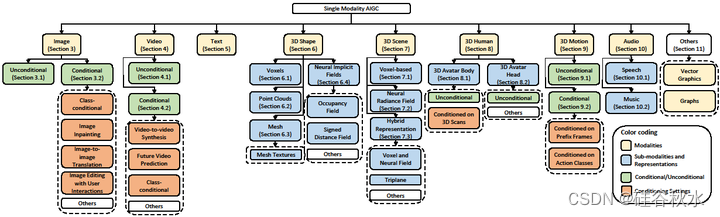
以下内容强调一下3D内容生成。
3D形状模态
神经隐式场
神经隐式场(或神经场)是对 3D 形状的隐式再现,其中神经网络“表征”3D 形状。为了观察3D形状,3D点坐标作为输入馈到神经网络中,并且可以预测与每个点相关的属性。神经场预测的属性往往是占用值 [27]、[312] 或符号距离值 [28],可以从中推断出 3D 形状。例如,通过查询 3D 空间的占用值,可以推断 3D 形状占用了 3D 空间的哪些区域。神经场具有作为连续表示的优势,以高分辨率和高内存效率对 3D 形状进行编码。还可以灵活地编码各种拓扑。然而,从神经场中提取 3D 表面通常很慢,因为需要用神经网络(通常是 MLP)对 3D 点进行密集评估。此外,由于缺乏有效监督训练的真值,因此训练神经场可能很困难,而且在神经场表示中训练生成模型(如 GAN)也不简单。此外,由于每个神经场只捕获一个3D形状,因此需要学习泛化和生成新形状的能力。编辑 3D 形状也可能很困难,因为信息隐式地存储为神经网络权重。
占用场。IM-GAN [27] 和 ONet [312] 是第一个执行 3D 形状生成的,同时用神经网络对隐式场进行建模,神经网络为每个点分配一个占用值。LDIF [313]根据结构化隐函数[314]模板将形状分解为一组重叠区域,提高了神经隐式场的效率和泛化性。Peng[315]介绍了卷积占用网络,可扩展,并且还比以前全连接架构有所改进。
符号距离场。符号距离场 (SDF) 预测到 3D 目标表面的度量符号距离,相比来说仅预测占用场中的占用值(如上所述)提供的效用有限。例如,SDF 的符号距离值可用于曲面光线投射渲染模型,其梯度可用于计算曲面法线。DeepSDF [28] 第一个使用神经场来预测每个 3D 点到3D形状表面的符号距离值。然而,基于ReLU的神经网络往往难以编码高频信号,例如纹理,因此SIREN [316]用周期激活函数,更好地处理高频细节。与以前依靠低维潜代码在各种形状进行泛化的方法不同,MetaSDF [317] 旨在通过元学习 [318] 提高神经 SDF 的泛化能力。网格IM-GAN [285]将空间分割成一个网格,并分别学习捕获每个网格单元的局部几何形状(而不是全局隐式函数),这也使局部的组成和排列能够创建新形状。SDF-扩散模型[268]提出了一种基于扩散的方法,通过去噪扩散过程迭代地提高SDF的分辨率,以SDF形式生成高分辨率3D形状。
其他。一些方法还探索了用神经场对3D形状[319][320]的操作和编辑。其他工作[321][322][323]旨在从原始点云数据构建神经隐式场。Dupont[324]学习在给定输入数据的情况下直接生成隐式神经表征(functa),该数据可用于表示各种任务(包括生成)的输入数据。
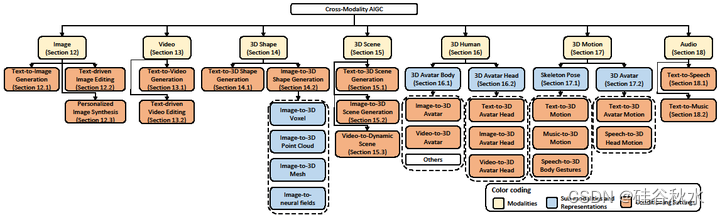
交叉模态形状生成
文本到 3D 形状生成
在文本到 3D 形状的生成中,目标是生成与文本描述对应的 3D 资产。这是非常困难的,因为大多数3D形状生成模型都是在ShapeNet [265]等特定目标类别的数据集上进行训练的,并且很难推广到零样本设置。另一个挑战是缺乏用于训练的大规模 3D 形状字幕数据,这可能会限制经过训练的文本到 3D 形状模型的能力。
早期的方法用文本 -3D 形状对训练其生成模型。Text2Shape [560] 在 ShapeNet 数据集 [265] 上收集了一个自然语言描述数据集,并用它来训练用于文本到 3D 形状生成的 3D GAN。Liu[561]采用隐式占用场表示,并用隐式最大似然估计(IMLE)方法代替GAN。ShapeCrafter [562]收集一个更大的数据集(Text2Shape++),并用预训练BERT [563]对文本信息进行编码。但是,由于缺少文本-3D形状对,这些方法也无法执行零样本生成。为了克服这个问题,最近的工作通常依赖于两种方法来执行文本引导的3D形状生成:基于CLIP的方法或基于扩散的方法。
基于CLIP的方法。CLIP-Forge [564] 用 CLIP 通过图像训练生成模型,但在推理时用文本嵌入。Text2Mesh [565] 利用 CLIP 来操纵 3D 网格的样式,用 CLIP 在渲染的图像(来自网格)和文本提示之间强制执行语义相似性。CLIP-Mesh [566] 以类似的方式使用 CLIP,但能够直接生成形状和纹理。DreamFields [567] 根据自然语言提示生成 3D 模型,同时避免使用任何 3D 训练数据。具体来说,DreamFields从许多摄像机视图中优化NeRF(表征3D目标),以便根据预训练的CLIP模型,渲染的图像在目标字幕下得分很高。Dream3D [568] 用Stable Diffusion之前结合 3D 形状,形成NeRF 的初始化,通过基于 CLIP 的损失进行优化(如DreamFields)。
基于扩散的方法。DreamFusion [41] 采用了与 DreamField 类似的方法,但将基于 CLIP 的损失替换为基于通过分数蒸馏采样 (SDS) 方法在预训练的图像扩散模型采样的损失。SJC [569] 还采用 SDS 来优化其 3D 表示(这是基于 DVGO [345] 和 TensoRF [348] 的体素 NeRF),并采用Stable Diffusion作为其基于图像的扩散模型。Magic3D [570] 提出一种从粗到细的优化方法,通过基于 SDS 的方法优化多个扩散先验,最终生成纹理网格。Magic3D显著提高DreamFusion的速度(提高了2×),同时实现更高的分辨率(提高了8×)。Latent-NeRF [571] 建议在潜扩散模型的潜空间中操作 NeRF 以提高效率,并在生成过程中引入形状引导,允许用户将 3D 形状引导到所需的形状。最近的一些工作还探索了用生成扩散模型的基于SDF表示(例如,Diffusion-SDF [572],SDFusion [573]),或者专注于从文本输入生成纹理(例如,TEXTure [574],Text2Tex [575])。
图像到3D形状生成
除了从文本输入生成3D形状外,许多方法还专注于从输入图像合成3D形状。这是非常具有挑战性的,因为图像可能存在深度信息模糊,并且3D形状的某些部分也可能被遮挡,在图像中不可见。这个方向的工作通常增加一个图像编码器来捕捉图像信息,同时提高图像与输出3D形状之间的对应关系。一些工作还减少了对3D数据的依赖,旨在仅从图像中完全学习3D形状。以下根据3D 表示不同对方法进行分类。
图像到 3D 体素。一些早期的工作侧重于将 3D 形状生成为体素。3D-R2N2 [576] 是一种 RNN 架构,接收目标实例的一个或多个图像并输出相应的 3D 体素占用网格,其中输出的 3D 目标可以向 RNN 馈送更多观察值,按顺序细化。TL- embedding network工作[577]引入一种基于自动编码的方法,用于将图像映射到3D体素图,该方法学习一种平均表示,其中既可以从图像中预测3D体素,也可以通过组合特征向量进行条件生成。Rezende[578]和Yan[579]学习从像素中恢复3D体结构,仅使用2D图像数据作为监督。Pix2Vox[580]在目标的每部分进行高质量的重建并融合,学习跨视图的上下文。
图像到 3D 点云。一些方法还探索了以图像为条件的3D点云生成,比体素表示更具可扩展性。Fan[581]旨在设计点集生成网络架构并探索基于Chamfer 距离和Earth-Mover距离的损失函数,从单个输入图像重建3D点云。PC2 [582]引入一种基于条件扩散的方法,从输入图像重建点云,包括一个投影调节方法,其中让局部图像特征在每个扩散步骤中投影到点云。
图像到 3D 网格。人们对从图像输入生成 3D 网格也非常感兴趣。Kato[583]提出一种神经渲染器,该渲染器可以将网格输出(即网格顶点投影到屏幕坐标系并生成图像)作为可微分操作,从而能够从图像生成3D网格。另外,Kanazawa[584]提出一种仅用一组RGM图像生成网格的方法,无需真实3D数据或目标的多视图图像,这使图像到网格重建成为可能。Pixel2Mesh [585] 还用基于图卷积网络 (GCN) 架构以粗到细的方式从单个 RGB 图像生成 3D 网格,学习将椭球网格变形为目标形状。Liao[586]设计一个不同的Marching Cubes层,该层允许学习给定原始观测值(例如,图像或点云)作为输入的显式表面网格表示。
图像到神经场。为了进一步提高可扩展性和分辨率,一些工作探索从图像生成神经场。DISN [587] 引入一种将单个图像作为输入并预测 SDF 的方法,SDF 是一个连续场,以任意分辨率表示 3D 形状。Michalkiewicz [588] 将level set方法整合到架构中,并在 CNN 的架构中引入了3D 表面的隐式表示作为一个独特层,提高从图像进行 3D 重建的准确性。SDFDiff [589] 是一种基于光线投射 SDF 的可微分渲染,允许从一个或多个图像中以高水平细节和复杂的拓扑进行 3D 重建。
跨模态 3D 场景视图合成
随AIGC方法的不断进步,更多的研究集中在3D场景生成,而不仅仅是3D形状。此类场景的生成可以通过其他输入模式(如文本、图像和视频)进行控制,
文本到3D场景生成
许多最近工作都探索文本输入对3D场景进行建模。由于缺乏配对的文本-3D场景数据,大多数利用CLIP或预训练的文本到图像模型来处理文本输入。Text2Scene [590] 利用 CLIP 将场景分解为子部分进行处理,从而用文本(或图像)输入对 3D 场景进行建模和风格化。Set-the-scene [591] 和 Text2NeRF [592] 借助文本到图像 扩散模型从文本生成 NeRF,表示 3D 场景。SceneScape [593] 和 Text2Room [594] 进一步利用预训练的单目深度预测模型来提高几何一致性,并直接生成场景的 3D 纹理网格表示。Po&Wetzstein [595]提出一种局部条件扩散技术,用于生成具有各种文本字幕的组合场景。MAV3D [596] 旨在通过文本到视频扩散模型生成 4D 动态场景。
图像到3D场景生成
与使用可能相当模糊的字幕不同,一些方法还从图像输入中合成 3D 场景表示,其中 3D 场景与图像中描绘的内容非常接近。PixelNeRF [597] 通过重投影方法基于一个或几个姿态图像预测 NeRF。Pix2NeRF [598] 通过构建 π-GAN [333] 来学习从单图像输出神经辐射场。LOLNeRF [599] 旨在学习自动解码器 [28] 从单视图重建 3D 目标。另一方面,NeRF-VAE [600] 探索一种基于 VAE 的方法,通过未见场景很少的视图学习生成一个 NeRF。最近,Chan[601]引入一种基于扩散的方法,从单个图像生成新视图,其中潜3D特征场捕获在推理过程中采样的场景表示分布。
视频到动态3D场景生成
除了编码静态3D场景(使用图像或文本输入)外,另一条工作研究旨在编码动态场景,其中场景可以随时间变化。这有时也称为 4D 视图合成,其中将视频作为输入,并获得动态 3D 场景表示,用户可以在任何给定时间渲染场景的图像。Xian[602] 学习神经辐射场(没有视图依赖性),同时估计深度随时约束场景的几何形状。D-NeRF [603]、NSFF [604] 和 Nerfies [605] 旨在通过动态 NeRF 表示,从单目视频中合成具有复杂和非刚体几何形状的动态场景新视图,该表示还考虑时域使场景变形。NR-NeRF [606] 将场景变形实现为光线弯曲,使直线光线非刚性变形。D2NeRF [607] 以完全自监督的方式学习场景动态和静态部分的单独辐射场,有效地解耦动态和静态分量。
版权归原作者 硅谷秋水 所有, 如有侵权,请联系我们删除。