
需要数据集和源码请点赞关注收藏后评论区留下QQ邮箱~~~
一、行为识别简介
行为识别是视频理解中的一项基础任务,它可以从视频中提取语义信息,进而可以为其他任务如行为检测,行为定位等提供通用的视频表征
现有的视频行为数据集大致可以划分为两种类型
1:场景相关数据集 这一类的数据集场景提供了较多的语义信息 仅仅通过单帧图像便能很好的判断对应的行为
2:时序相关数据集 这一类数据集对时间关系要求很高,需要足够多帧图像才能准确的识别视频中的行为。
例如骑马的例子就与场景高度相关,马和草地给出了足够多的语义信息
但是打开柜子就与时间高度相关,如果反转时序甚至容易认为在关闭柜子
如下图

二、数据准备
数据的准备包括对视频的抽帧处理,具体原理此处不再赘述
大家可自行前往官网下载数据集
视频行为识别数据集
三、模型搭建与训练
在介绍模型的搭建与训练之外,需要先了解的命令行参数,还有无名的必填参数dataset以及modality。前者用于选择数据集,后者用于确定数据集类型 是RGB图像还是Flow光流图像
过程比较繁琐 此处不再赘述
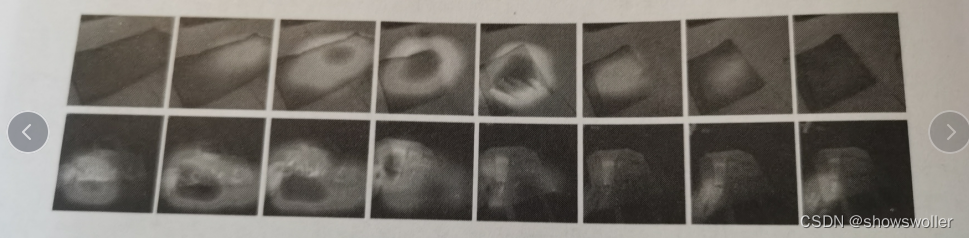
效果如下图
最终会得到如下的热力图,从红色到黄色到绿色到蓝色,网络的关注度从大到小,可以看到模块可以很好地定位到运动发生的时空区域
四、代码
项目结构如下
main函数代码
import os
import time
import shutil
import torch.nn.parallel
imd_norm_
from ops.dataset import TSNDataSet
from ops.models import TSN
from ops.transforms import *
from opts import parser
from ops import dataset_config
from ops.utils import AverageMeter, accuracy
from ops.temporal_shift import make_temporal_pool
from tensorboardX import SummaryWriter
best_prec1 = 0
def main():
global args, best_prec1
args = parser.parse_args()
num_class, args.train_list, args.val_list, args.root_path, prefix = dataset_config.return_dataset(args.dataset,
args.modality)
full_arch_name = args.arch
if args.shift:
full_arch_name += '_shift{}_{}'.format(args.shift_div, args.shift_place)
if args.temporal_pool:
full_arch_name += '_tpool'
args.store_name = '_'.join(
['TSM', args.dataset, args.modality, full_arch_name, args.consensus_type, 'segment%d' % args.num_segments,
'e{}'.format(args.epochs)])
args.store_name += '_nl'
if args.suffix is not None:
args.store_name += '_{}'.format(args.suffix)
print('storing name: ' + args.store_name)
check_rootfolders()
model = TSN(num_class, args.num_segments, args.modality,
base_model=args.arch,
consensus_type=args.consensus_type,
dropout=args.dropout,
img_feature_dim=args.img_feature_dim,
partial_bn=not args.no_partialbn,
pretrain=args.pretrain,
is_shift=args.shift, shift_div=args.shift_div, shift_place=args.shift_place,
fc_lr5=not (args.tune_from and args.dataset in args.tune_from),
temporal_pool=args.temporal_pool,
non_local=args.non_local)
crop_size = model.crop_size
scale_size = model.scale_size
input_mean = model.input_mean
in else True)
model = torch.nn.DataParallel(model, device_ids=args.gpus).cuda()
optimizer = torch.optim.SGD(policies,
args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)
if args.resume:
if args.temporal_pool: # early temporal pool so that we can load the state_dict
make_temporal_pool(model.module.base_model, args.num_segments)
if os.path.isfile(args.resume):
print(("=> loading checkpoint '{}'".format(args.resume)))
checkpoint = torch.load(args.resume)
args.start_epoch = checkpoint['epoch']
best_prec1 = checkpoint['best_prec1']
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
print(("=> loaded checkpoint '{}' (epoch {})"
.format(args.evaluate, checkpoint['epoch'])))
else:
print(("=> no checkpoint found at '{}'".format(args.resume)))
ate_dict']
model_dict = model.state_dict()
replace_dict = []
for k, v in sd.items():
if k not in model_dict and k.replace('.net', '') in model_dict:
print('=> Load after remove .net: ', k)
replace_dict.append((k, k.replace('.net', '')))
for k, v in model_dict.items():
if k not in sd and k.replace('.net', '') in sd:
print('=> Load after adding .net: ', k)
replace_dict.append((k.replace('.net', ''), k))
for k, k_new in replace_dict:
sd[k_new] = sd.pop(k)
keys1 = set(list(sd.keys()))
keys2 = set(list(model_dict.keys()))
set_diff = (keys1 - keys2) | (keys2 - keys1)
print('#### Notice: keys that failed to load: {}'.format(set_diff))
if args.dataset not in args.tune_from: # new dataset
print('=> New dataset, do not load fc weights')
sd = {k: v for k, v in sd.items() if 'fc' not in k}
if te_dict(model_dict)
if args.temporal_pool and not args.resume:
make_temporal_pool(model.module.base_model, args.num_segments)
cudnn.benchmark = True
# Data loading code
if args.modality != 'RGBDiff':
normalize = GroupNormalize(input_mean, input_std)
else:
normalize = IdentityTransform()
if args.modality == 'RGB':
data_length = 1
elif args.modality in ['Flow', 'RGBDiff']:
data_length = 5
train_loader = torch.utils.data.DataLoader(
TSNDataSet(args.root_path, args.train_list, num_segments=args.num_segments,
new_length=data_length,
modality=args.modality,
image_tmpl=prefix,
transform=torchvision.transforms.Compose([
train_augmentation,
Stack(roll=(args.arch in ['BNInception', 'InceptionV3'])),
ToTorchFormatTensor(div=(args.arch not in ['BNInception', 'InceptionV3'])),
normalize,
]), dense_sample=args.dense_sample),
batch_size=args.batch_size, shuffle=True,
num_workers=args.workers, pin_memory=True,
drop_last=True) # prevent something not % n_GPU
val_loader = torch.utils.data.DataLoader(
TSNDataSet(args.root_path, args.val_list, num_segments=args.num_segments,
new_length=data_length,
modality=args.modality,
image_tmpl=prefix,
random_shift=False,
transform=torchvision.transforms.Compose([
GroupScale(int(scale_size)),
GroupCenterCrop(crop_size),
Stack(roll=(args.arch in ['BNInception', 'InceptionV3'])),
ToTorchFormatTensor(div=(args.arch not in ['BNInception', 'InceptionV3'])),
normalize,
]), dense_sample=args.dense_sample),
batch_size=args.batch_size, shuffle=False,
num_workers=args.workers, pin_memory=True)
# define loss function (criterion) and optimizer
if args.loss_type == 'nll':
criterion = torch.nn.CrossEntropyLoss().cuda()
else:
raise ValueError("Unknown loss type")
for group in policies:
print(('group: {} has {} params, lr_mult: {}, decay_mult: {}'.format(
group['name'], len(group['params']), group['lr_mult'], group['decay_mult'])))
if args.evaluate:
validate(val_loader, model, criterion, 0)
return
log_training = open(os.path.join(args.root_log, args.store_name, 'log.csv'), 'w')
with open(os.path.join(args.root_log, args.store_name, 'args.txt'), 'w') as f:
f.write(str(args))
tf_writer = SummaryWriter(log_dir=os.path.join(args.root_log, args.store_name))
for epoch in range(args.start_epoch, args.epochs):
adjust_learning_rate(optimizer, epoch, args.lr_type, args.lr_steps)
# train for one epoch
train(train_loader, model, criterion, optimizer, epoch, log_training, tf_writer)
# evaluate on validation set
if (epoch + 1) % args.eval_freq == 0 or epoch == args.epochs - 1:
prec1 = validate(val_loader, model, criterion, epoch, log_training, tf_writer)
# remember best prec@1 and save checkpoint
is_best = prec1 > best_prec1
best_prec1 = max(prec1, best_prec1)
tf_writer.add_scalar('acc/test_top1_best', best_prec1, epoch)
output_best = 'Best Prec@1: %.3f\n' % (best_prec1)
print(output_best)
log_training.write(output_best + '\n')
log_training.flush()
save_checkpoint({
'epoch': epoch + 1,
'arch': args.arch,
'state_dict': model.state_dict(),
'optimizer': optimizer.state_dict(),
'best_prec1': best_prec1,
}, is_best)
def train(train_loader, model, criterion, optimizer, epoch, log, tf_writer):
batch_time = AverageMeter()
data_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
if args.no_partialbn:
model.module.partialBN(False)
else:
model.module.partialBN(True)
# switch to train mode
model.train()
end = time.time()
for i, (input, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
target = target.cuda()
input_var = torch.autograd.Variable(input)
target_var = torch.autograd.Variable(target)
# compute output
output = model(input_var)
loss = criterion(output, target_var)
# measure accuracy and record loss
prec1, prec5 = accuracy(output.data, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(prec1.item(), input.size(0))
top5.update(prec5.item(), input.size(0))
# compute gradient and do SGD step
loss.backward()
if args.clip_gradient is not None:
total_norm = clip_grad_norm_(model.parameters(), args.clip_gradient)
optimizer.step()
optimizer.zero_grad()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0:
output = ('Epoch: [{0}][{1}/{2}], lr: {lr:.5f}\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data {data_time.val:.3f} ({data_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
epoch, i, len(train_loader), batch_time=batch_time,
data_time=data_time, loss=losses, top1=top1, top5=top5, lr=optimizer.param_groups[-1]['lr'] * 0.1)) # TODO
print(output)
log.write(output + '\n')
log.flush()
tf_writer.add_scalar('loss/train', losses.avg, epoch)
tf_writer.add_scalar('acc/train_top1', top1.avg, epoch)
tf_writer.add_scalar('acc/train_top5', top5.avg, epoch)
tf_writer.add_scalar('lr', optimizer.param_groups[-1]['lr'], epoch)
def validate(val_loader, model, criterion, epoch, log=None, tf_writer=None):
batch_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to evaluate mode
model.eval()
end = time.time()
with torch.no_grad():
for i, (input, target) in enumerate(val_loader):
target = target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
prec1, prec5 = accuracy(output.data, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(prec1.item(), input.size(0))
top5.update(prec5.item(), input.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0:
output = ('Test: [{0}/{1}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
i, len(val_loader), batch_time=batch_time, loss=losses,
top1=top1, top5=top5))
print(output)
if log is not None:
log.write(output + '\n')
log.flush()
output = ('Testing Results: Prec@1 {top1.avg:.3f} Prec@5 {top5.avg:.3f} Loss {loss.avg:.5f}'
.format(top1=top1, top5=top5, loss=losses))
print(output)
if log is not None:
log.write(output + '\n')
log.flush()
if tf_writer is not None:
tf_writer.add_scalar('loss/test', losses.avg, epoch)
tf_writer.add_scalar('acc/test_top1', top1.avg, epoch)
tf_writer.add_scalar('acc/test_top5', top5.avg, epoch)
return top1.avg
def save_checkpoint(state, is_best):
filename = '%s/%s/ckpt.pth.tar' % (args.root_model, args.store_name)
torch.save(state, filename)
if is_best:
shutil.copyfile(filename, filename.replace('pth.tar', 'best.pth.tar'))
def adjust_learning_rate(optimizer, epoch, lr_type, lr_steps):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
if lr_type == 'step':
decay = 0.1 ** (sum(epoch >= np.array(lr_steps)))
lr = args.lr * decay
decay = args.weight_decay
elif lr_type == 'cos':
import math
lr = 0.5 * args.lr * (1 + math.cos(math.pi * epoch / args.epochs))
decay = args.weight_decay
else:
raise NotImplementedError
for param_group in optimizer.param_groups:
param_group['lr'] = lr * param_group['lr_mult']
param_group['weight_decay'] = decay * param_group['decay_mult']
def check_rootfolders():
"""Create log and model folder"""
folders_util = [args.root_log, args.root_model,
os.path.join(args.root_log, args.store_name),
os.path.join(args.root_model, args.store_name)]
for folder in folders_util:
if not os.path.exists(folder):
print('creating folder ' + folder)
os.mkdir(folder)
if __name__ == '__main__':
main()
opts类代码如下
#这里下面的参数应该要自行输入
import argparse
parser = argparse.ArgumentParser(description="PyTorch implementation of Temporal Segment Networks")
parser.add_argument('dataset', default="")
parser.add_argument('modality', default="RGB", choices=['RGB', 'Flow'])
parser.add_argument('--train_list', type=str, default="")
parser.add_argument('--val_list', type=str, default="")
parser.add_argument('--root_path', type=str, default="")
parser.add_argument('--store_name', type=str, default="")
# ========================= Model Configs ==========================
parser.add_argument('--arch', type=str, default="BNInception")
parser.add_argument('--num_segments', type=int, default=3)
parser.add_argument('--consensus_type', type=str, default='avg')
parser.add_argument('--k', type=int, default=3)
parser.add_argument('--dropout', '--do', default=0.5, type=float,
metavar='DO', help='dropout ratio (default: 0.5)')
parser.add_argument('--loss_type', type=str, default="nll",
choices=['nll'])
parser.add_argument('--img_feature_dim', default=256, type=int, help="the feature dimension for each frame")
parser.add_argument('--suffix', type=str, default=None)
parser.add_argument('--pretrain', type=str, default='imagenet')
parser.add_argument('--tune_from', type=str, default=None, help='fine-tune from checkpoint')
# ========================= Learning Configs ==========================
parser.add_argument('--epochs', default=120, type=int, metavar='N',
help='number of total epochs to run')
parser.add_argument('-b', '--batch-size', default=128, type=int,
metavar='N', help='mini-batch size (default: 256)')
parser.add_argument('--lr', '--learning-rate', default=0.001, type=float,
metavar='LR', help='initial learning rate')
parser.add_argument('--lr_type', default='step', type=str,
metavar='LRtype', help='learning rate type')
parser.add_argument('--lr_steps', default=[50, 100], type=float, nargs="+",
metavar='LRSteps', help='epochs to decay learning rate by 10')
parser.add_argument('--momentum', default=0.9, type=float, metavar='M',
help='momentum')
parser.add_argument('--weight-decay', '--wd', default=5e-4, type=float,
metavar='W', help='weight decay (default: 5e-4)')
parser.add_argument('--clip-gradient', '--gd', default=None, type=float,
metavar='W', help='gradient norm clipping (default: disabled)')
parser.add_argument('--no_partialbn', '--npb', default=False, action="store_true")
# ========================= Monitor Configs ==========================
parser.add_argument('--print-freq', '-p', default=20, type=int,
metavar='N', help='print frequency (default: 10)')
parser.add_argument('--eval-freq', '-ef', default=5, type=int,
metavar='N', help='evaluation frequency (default: 5)')
# ========================= Runtime Configs ==========================
parser.add_argument('-j', '--workers', default=8, type=int, metavar='N',
help='number of data loading workers (default: 8)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='path to latest checkpoint (default: none)')
parser.add_argument('-e', '--evaluate', dest='evaluate', action='store_true',
help='evaluate model on validation set')
parser.add_argument('--snapshot_pref', type=str, default="")
parser.add_argument('--start-epoch', default=0, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('--gpus', nargs='+', type=int, default=None)
parser.add_argument('--flow_prefix', default="", type=str)
parser.add_argument('--root_log',type=str, default='log')
parser.add_argument('--root_model', type=str, default='checkpoint')
parser.add_argument('--shift', default=False, action="store_true", help='use shift for models')
parser.add_argument('--shift_div', default=8, type=int, help='number of div for shift (default: 8)')
parser.add_argument('--shift_place', default='blockres', type=str, help='place for shift (default: stageres)')
parser.add_argument('--temporal_pool', default=False, action="store_true", help='add temporal pooling')
parser.add_argument('--non_local', default=False, action="store_true", help='add non local block')
parser.add_argument('--dense_sample', default=False, action="store_true", help='use dense sample for video dataset')
test_models类代码如下
# Notice that this file has been modified to support ensemble testing
from ops.transforms import *
from ops import dataset_config
from torch.nn import functional as F
# options
parser = argparse.ArgumentParser(description="TSM testing on the full validation set")
parser.add_argument('dataset', type=str)
# may contain splits
pars
parser.add_argument('--test_crops', type=int, default=1)
parser.add_argument('--coeff', type=str, default=None)
parser.add_argument('--batch_size', type=int, default=1)
parser.add_argument('-j', '--workers', default=8, type=int, metavar='N',
help='number of data loading workers (default: 8)')
# for true test
parser.add_argument('--test_list', type=str, default=None)
parser.add_argument('--csv_file', type=str, default=None)
parser.add_argument('--softmax', default=False, action="store_true", help='use softmax')
parser.add_argument('--max_num', type=int, default=-1)
parser.add_argument('--input_size', type=int, default=224)
parser.add_argument('--crop_fusion_type', type=str, default='avg')
parser.add_argument('--gpus', nargs='+', type=int, default=None)
parser.add_argument('--img_feature_dim',type=int, default=256)
parser.add_argument('--num_set_segments',type=int, default=1,help='TODO: select multiply set of n-frames from a video')
parser.add_argument('--pretrain', type=str, default='imagenet')
args = parser.parse_args()
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def accuracy(output, target, topk=(1,)):
"""Computes the precision@k for the specified values of k"""
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0)
res.append(correct_k.mul_(100.0 / batch_size))
return res
def parse_shift_option_from_log_name(log_name):
if 'shift' in log_name:
strings = log_name.split('_')
for i, s in enumerate(strings):
if 'shift' in s:
break
return True, int(strings[i].replace('shift', '')), strings[i + 1]
else:
return False, None, None
weights_list = args.weights.split(',')
test_segments_list = [int(s) for s in args.test_segments.split(',')]
assert len(weights_list) == len(test_segments_list)
if args.coeff is None:
coeff_list = [1] * len(weights_list)
else:
coeff_list = [float(c) for c in args.coeff.split(',')]
if args.test_list is not None:
test_file_list = args.test_list.split(',')
else:
test_file_list = [None] * len(weights_list)
data_iter_list = []
net_list = []
modality_list = []
total_num = None
for this_weights, this_test_segments, test_file in zip(weights_list, test_segments_list, test_file_list):
is_shift, shift_div, shift_place = parse_shift_option_from_log_name(this_weights)
if 'RGB' in this_weights:
modality = 'RGB'
else:
modality = 'Flow'
this_arch = this_weights.split('TSM_')[1].split('_')[2]
modality_list.append(modality)
num_class, args.train_list, val_list, root_path, prefix = dataset_config.return_dataset(args.dataset,
modality)
print('=> shift: {}, shift_div: {}, shift_place: {}'.format(is_shift, shift_div, shift_place))
net = TSN(num_class, this_test_segments if is_shift else 1, modality,
base_model=this_arch,
consensus_type=args.crop_fusion_type,
img_feature_dim=args.img_feature_dim,
pretrain=args.pretrain,
is_shift=is_shift, shift_div=shift_div, shift_place=shift_place,
non_local='_nl' in this_weights,
)
if 'tpool' in this_weights:
from ops.temporal_shift import make_temporal_pool
make_temporal_pool(net.base_model, this_test_segments) # since DataParallel
checkpoint = torch.load(this_weights)
checkpoint = checkpoint['state_dict']
# base_dict = {('base_model.' + k).replace('base_model.fc', 'new_fc'): v for k, v in list(checkpoint.items())}
base_dict = {'.'.join(k.split('.')[1:]): v for k, v in list(checkpoint.items())}
replace_dict = {'base_model.classifier.weight': 'new_fc.weight',
'base_model.classifier.bias': 'new_fc.bias',
}
for k, v in replace_dict.items():
if k in base_dict:
base_dict[v] = base_dict.pop(k)
net.load_state_dict(base_dict)
input_size = net.scale_size if args.full_res else net.input_size
if args.test_crops == 1:
cropping = torchvision.transforms.Compose([
GroupScale(net.scale_size),
GroupCenterCrop(input_size),
])
elif args.test_crops == 3: # do not flip, so only 5 crops
cropping = torchvision.transforms.Compose([
GroupFullResSample(input_size, net.scale_size, flip=False)
])
elif args.test_crops == 5: # do not flip, so only 5 crops
cropping = torchvision.transforms.Compose([
GroupOverSample(input_size, net.scale_size, flip=False)
])
elif args.test_crops == 10:
cropping = torchvision.transforms.Compose([
GroupOverSample(input_size, net.scale_size)
])
else:
raise ValueError("Only 1, 5, 10 crops are supported while we got {}".format(args.test_crops))
data_loader = torch.utils.data.DataLoader(
TSNDataSet(root_path, test_file if test_file is not None else val_list, num_segments=this_test_segments,
new_length=1 if modality == "RGB" else 5,
modality=modality,
image_tmpl=prefix,
test_mode=True,
remove_missing=len(weights_list) == 1,
transform=torchvision.transforms.Compose([
cropping,
Stack(roll=(this_arch in ['BNInception', 'InceptionV3'])),
ToTorchFormatTensor(div=(this_arch not in ['BNInception', 'InceptionV3'])),
GroupNormalize(net.input_mean, net.input_std),
]), dense_sample=args.dense_sample, twice_sample=args.twice_sample),
batch_size=args.batch_size, shuffle=False,
num_workers=args.workers, pin_memory=True,
)
if args.gpus is not None:
devices = [args.gpus[i] for i in range(args.workers)]
else:
devices = list(range(args.workers))
net = torch.nn.DataParallel(net.cuda())
net.eval()
data_gen = enumerate(data_loader)
if total_num is None:
total_num = len(data_loader.dataset)
else:
assert total_num == len(data_loader.dataset)
data_iter_list.append(data_gen)
net_list.append(net)
output = []
def eval_video(video_data, net, this_test_segments, modality):
net.eval()
with torch.no_grad():
i, data, label = video_data
batch_size = label.numel()
num_crop = args.test_crops
if args.dense_sample:
num_crop *= 10 # 10 clips for testing when using dense sample
if args.twice_sample:
num_crop *= 2
if modality == 'RGB':
length = 3
elif modality == 'Flow':
length = 10
elif modality == 'RGBDiff':
length = 18
else:
raise ValueError("Unknown modality "+ modality)
data_in = data.view(-1, length, data.size(2), data.size(3))
if is_shift:
data_in = data_in.view(batch_size * num_crop, this_test_segments, length, data_in.size(2), data_in.size(3))
rst = net(data_in)
rst = rst.reshape(batch_size, num_crop, -1).mean(1)
if args.softmax:
# take the softmax to normalize the output to probability
rst = F.softmax(rst, dim=1)
rst = rst.data.cpu().numpy().copy()
if net.module.is_shift:
rst = rst.reshape(batch_size, num_class)
else:
rst = rst.reshape((batch_size, -1, num_class)).mean(axis=1).reshape((batch_size, num_class))
return i, rst, label
proc_start_time = time.time()
max_num = args.max_num if args.max_num > 0 else total_num
top1 = AverageMeter()
top5 = AverageMeter()
for i, data_label_pairs in enumerate(zip(*data_iter_list)):
with torch.no_grad():
if i >= max_num:
break
this_rst_list = []
this_label = None
for n_seg, (_, (data, label)), net, modality in zip(test_segments_list, data_label_pairs, net_list, modality_list):
rst = eval_video((i, data, label), net, n_seg, modality)
this_rst_list.append(rst[1])
this_label = label
assert len(this_rst_list) == len(coeff_list)
for i_coeff in range(len(this_rst_list)):
this_rst_list[i_coeff] *= coeff_list[i_coeff]
ensembled_predict = sum(this_rst_list) / len(this_rst_list)
for p, g in zip(ensembled_predict, this_label.cpu().numpy()):
output.append([p[None, ...], g])
cnt_time = time.time() - proc_start_time
prec1, prec5 = accuracy(torch.from_numpy(ensembled_predict), this_label, topk=(1, 5))
top1.update(prec1.item(), this_label.numel())
top5.update(prec5.item(), this_label.numel())
if i % 20 == 0:
print('video {} done, total {}/{}, average {:.3f} sec/video, '
'moving Prec@1 {:.3f} Prec@5 {:.3f}'.format(i * args.batch_size, i * args.batch_size, total_num,
float(cnt_time) / (i+1) / args.batch_size, top1.avg, top5.avg))
video_pred = [np.argmax(x[0]) for x in output]
video_pred_top5 = [np.argsort(np.mean(x[0], axis=0).reshape(-1))[::-1][:5] for x in output]
video_labels = [x[1] for x in output]
if args.csv_file is not None:
print('=> Writing result to csv file: {}'.format(args.csv_file))
with open(test_file_list[0].replace('test_videofolder.txt', 'category.txt')) as f:
categories = f.readlines()
categories = [f.strip() for f in categories]
with open(test_file_list[0]) as f:
vid_names = f.readlines()
vid_names = [n.split(' ')[0] for n in vid_names]
assert len(vid_names) == len(video_pred)
if args.dataset != 'somethingv2': # only output top1
with open(args.csv_file, 'w') as f:
for n, pred in zip(vid_names, video_pred):
f.write('{};{}\n'.format(n, categories[pred]))
else:
with open(args.csv_file, 'w') as f:
for n, pred5 in zip(vid_names, video_pred_top5):
fill = [n]
for p in list(pred5):
fill.append(p)
f.write('{};{};{};{};{};{}\n'.format(*fill))
cf = confusion_matrix(video_labels, video_pred).astype(float)
np.save('cm.npy', cf)
cls_cnt = cf.sum(axis=1)
cls_hit = np.diag(cf)
cls_acc = cls_hit / cls_cnt
print(cls_acc)
upper = np.mean(np.max(cf, axis=1) / cls_cnt)
print('upper bound: {}'.format(upper))
print('-----Evaluation is finished------')
print('Class Accuracy {:.02f}%'.format(np.mean(cls_acc) * 100))
print('Overall Prec@1 {:.02f}% Prec@5 {:.02f}%'.format(top1.avg, top5.avg))
创作不易 觉得有帮助请点赞关注收藏~~~
本文转载自: https://blog.csdn.net/jiebaoshayebuhui/article/details/127856224
版权归原作者 showswoller 所有, 如有侵权,请联系我们删除。
版权归原作者 showswoller 所有, 如有侵权,请联系我们删除。