
【AI实战】大模型 LLM 部署推理框架的 vLLM 应用
vLLM介绍
vLLM is a fast and easy-to-use library for LLM inference and serving.
vLLM 速度很快:
- State-of-the-art serving throughput
- Efficient management of attention key and value memory with PagedAttention
- Continuous batching of incoming requests
- Optimized CUDA kernels
vLLM灵活且易于使用:
- Seamless integration with popular HuggingFace models
- High-throughput serving with various decoding algorithms, including parallel sampling, beam search, and more
- Tensor parallelism support for distributed inference
- Streaming outputs
- OpenAI-compatible API server
vLLM 无缝支持多数 Huggingface 模型,包括:
- BLOOM (bigscience/bloom, bigscience/bloomz, etc.)
- GPT-2 (gpt2, gpt2-xl, etc.)
- GPT BigCode (bigcode/starcoder, bigcode/gpt_bigcode-santacoder, etc.)
- GPT-J (EleutherAI/gpt-j-6b, nomic-ai/gpt4all-j, etc.)
- GPT-NeoX (EleutherAI/gpt-neox-20b, databricks/dolly-v2-12b, stabilityai/stablelm-tuned-alpha-7b, etc.)
- LLaMA (lmsys/vicuna-13b-v1.3, young-geng/koala, openlm-research/open_llama_13b, etc.)
- MPT (mosaicml/mpt-7b, mosaicml/mpt-30b, etc.)
- OPT (facebook/opt-66b, facebook/opt-iml-max-30b, etc.)
环境配置
环境要求
- OS: Linux
- Python: 3.8 or higher
- CUDA: 11.0 – 11.8
- GPU: compute capability 7.0 or higher (e.g., V100, T4, RTX20xx, A100, L4, etc.)
安装 vllm
- pip安装
pip install vllm
- 源码安装
git clone https://github.com/vllm-project/vllm.git
cd vllm
pip install -e . # This may take 5-10 minutes.
算力要求
算力查询方法
- 打开bing查询地址:https://cn.bing.com/
- 查询方式选择 国际版
- 输入查询内容:
t4 GPUs compute capability我的 GPU 是 T4,修改 t4 为你的即可 - 查询结果如下:
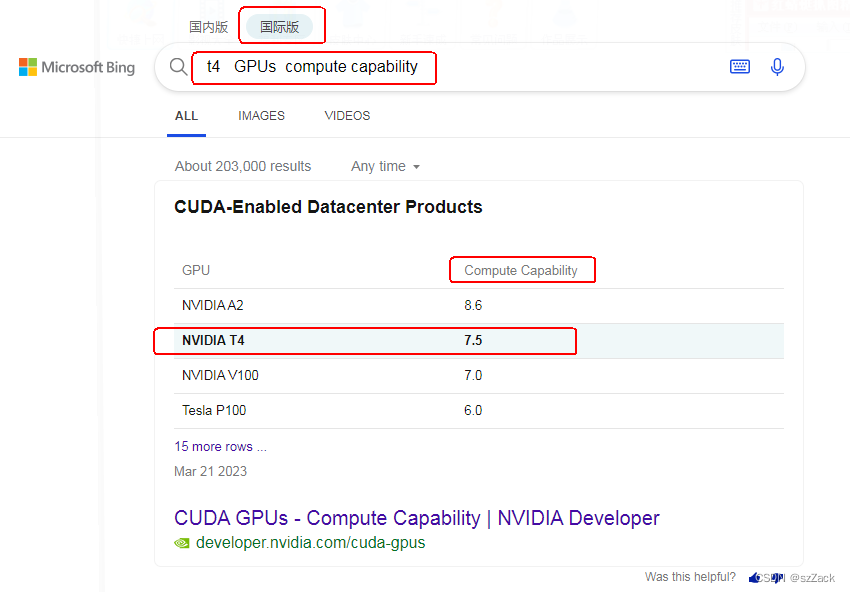
算力问题
vllm 对GPU 的 compute capability 要求必须大于等于 7.0,否则会报错,错误信息如下:
RuntimeError: GPUs with compute capability less than 7.0 are not supported.
Quickstart
离线批量推理
示例代码:
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="facebook/opt-125m")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
API Server
以
FastAPI server
为例子, 服务使用
AsyncLLMEngine
类来支持异步请求。
- 开启服务:
python -m vllm.entrypoints.api_server
默认接口:
http://localhost:8000
默认模型:
OPT-125M model
- 测试:
curl http://localhost:8000/generate \
-d '{
"prompt": "San Francisco is a",
"use_beam_search": true,
"n": 4,
"temperature": 0
}'
兼容 OpenAI Server
- 开启服务:
python -m vllm.entrypoints.openai.api_server --model facebook/opt-125m
可选参数:
--host
,
--port
- 查询服务:
curl http://localhost:8000/v1/models
- 测试:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "facebook/opt-125m",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
Serving
分布式推理和服务
安装依赖库:
pip install ray
- 多GPU推理 4块GPU推理:
from vllm import LLM
llm = LLM("facebook/opt-13b", tensor_parallel_size=4)
output = llm.generate("San Franciso is a")
使用 tensor_parallel_size 指定 GPU 数量
- 多GPU服务
python -m vllm.entrypoints.api_server \
--model facebook/opt-13b \
--tensor-parallel-size 4
- 扩展到多节点 运行vllm之前开启
Ray runtime:
# On head node
ray start --head
# On worker nodes
ray start --address=<ray-head-address>
使用 SkyPilot 运行服务
安装 SkyPilot :
pip install skypilot
sky check
serving.yaml:
resources:
accelerators: A100
envs:
MODEL_NAME: decapoda-research/llama-13b-hf
TOKENIZER: hf-internal-testing/llama-tokenizer
setup: |
conda create -n vllm python=3.9 -y
conda activate vllm
git clone https://github.com/vllm-project/vllm.git
cd vllm
pip install .
pip install gradio
run: |
conda activate vllm
echo 'Starting vllm api server...'
python -u -m vllm.entrypoints.api_server \
--model $MODEL_NAME \
--tensor-parallel-size $SKYPILOT_NUM_GPUS_PER_NODE \
--tokenizer $TOKENIZER 2>&1 | tee api_server.log &
echo 'Waiting for vllm api server to start...'
while ! `cat api_server.log | grep -q 'Uvicorn running on'`; do sleep 1; done
echo 'Starting gradio server...'
python vllm/examples/gradio_webserver.py
开启服务:
sky launch serving.yaml
其他可选参数:
sky launch -c vllm-serve-new -s serve.yaml --gpus A100:8 --env MODEL_NAME=decapoda-research/llama-65b-hf
测试:
浏览器打开:
https://<gradio-hash>.gradio.live
模型
vLLM支持的模型
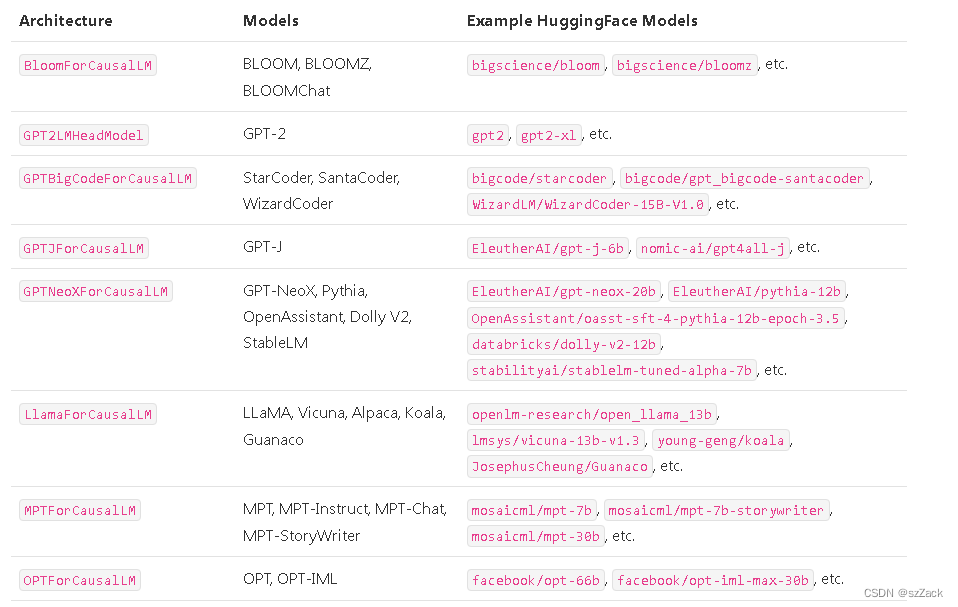
https://vllm.readthedocs.io/en/latest/models/supported_models.html#supported-models
添加自己的模型
本文档提供了将HuggingFace Transformers模型集成到vLLM中的高级指南。
https://vllm.readthedocs.io/en/latest/models/adding_model.html
参考
1.https://vllm.readthedocs.io/en/latest/
2.https://github.com/vllm-project/vllm
3.https://vllm.ai/
4.https://github.com/vllm-project/vllm/discussions
5.https://github.com/skypilot-org/skypilot/blob/master/llm/vllm
本文转载自: https://blog.csdn.net/zengNLP/article/details/131764968
版权归原作者 szZack 所有, 如有侵权,请联系我们删除。
版权归原作者 szZack 所有, 如有侵权,请联系我们删除。