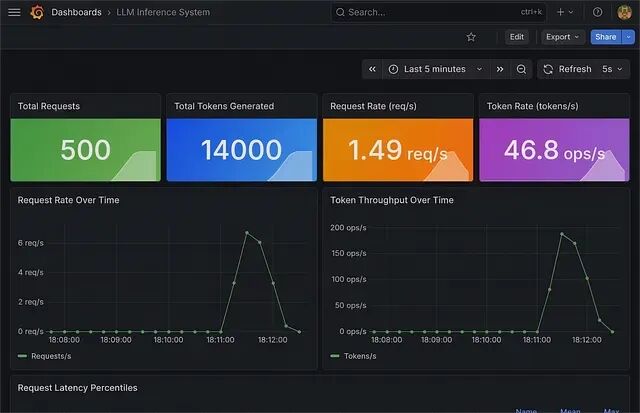
从零构建 Mini-vLLM:KV-Cache、动态批处理与分布式推理全流程
Mini-vLLM是一个从零开始写的推理引擎,我们的目标不是为了造轮子,而是要知道轮子是如何工作的。

LMCache:基于KV缓存复用的LLM推理优化方案
LMCache针对TTFT提出了一套KV缓存持久化与复用的方案。项目开源,目前已经和vLLM深度集成。
vLLM 性能优化实战:批处理、量化与缓存配置方案
这篇文章将介绍怎么让 vLLM 真正干活——持续输出高令牌/秒,哪些参数真正有用,以及怎么在延迟和成本之间做取舍。
vLLM 吞吐量优化实战:10个KV-Cache调优方法让tokens/sec翻倍
十个经过实战检验的 vLLM KV-cache 优化方法 —— 量化、分块预填充、前缀重用、滑动窗口、ROPE 缩放、后端选择等等 —— 提升 tokens/sec。

vLLM推理加速指南:7个技巧让QPS提升30-60%
下面这些是我在实际项目里反复用到的几个调优手段,有代码、有数据、也有一些踩坑经验。
【AI实战】大模型 LLM 部署推理框架的 vLLM 应用
大模型 LLM 推理框架的 vLLM 应用



