
为了系统性地理解机器学习模型的不同评价指标及其之间的关系,我们将从其定义出发,探究其物理含义及彼此之间的联系,并从数学上给出相应的公式推导,以方便后续用到时复习理解。由于篇幅较长,因此将其分为两篇,这是第一部分,第二部分参见:机器学习分类器评价指标详解(Precision, Recall, PR, ROC, AUC等)(二)
那我们开始吧,
为了判断学习器的好坏,需要对其进行性能评估,而进行性能评估就需要评价标准,针对学习器类型的不同,评价指标也不相同,一般而言,回归任务的评价指标是均方误差,其公式为:
而平时我们见到更多的是分类任务的学习模型,所以下面我们主要讨论分类任务中常见的性能度量指标 。
为了讨论的简单,我们以二分类任务为例,给定一个二分类分类器,其对于测试样本的分类结果会出现四种情况:
将正类分为正类,将正类分为负类;
将负类分为正类,将负类分为负类。
如果我们把上述四种情况统一到一个矩阵中就是所谓的混淆矩阵,如下:
预测类别 Prediction Label
正类
负类
真正标签
True Label
正类
真正例 (True Positive, TP)
假负例 (False Negative, FN)
负类
假正例 (False Positive, FP)
真负例 (True Negative, TN)
根据这个矩阵,可以衍生出若干有不同针对性的度量指标,分别介绍如下:
1.正确率(Accuracy)
其定义为
由其定义可知,正确率考察的是分类器的整体分类性能,也即是正确分类的样本数占总样本数的比例。虽然其使用率很高,但是当正负样本不均衡的时候,该指标将失去其有效力。比如,在测试样本中,90%的样本都是正样本,那我们可以把所有样本都预测为正样本,从而轻松得到90%的正确率,然而这种分类器是没有任何意义的。
这就说明了:由于样本不平衡的问题,导致了得到的高准确率结果含有很大的水分。即如果样本不平衡,准确率就会失效。
正因为如此,也就衍生出了其它两种指标:精准率和召回率。
2.精准率(Precision)
又称查准率,其定义为
精准率是针对预测结果而言的 (这一点对于理解其本身的含义很重要),
根据其定义可知,精准率考察的是在所有预测为正类的样本中真正为正类的概率,也即在预测为正类的样本中,有多大把握可以预测正确,或者说在找到的所有正类中,有多少是准确的(也即为何叫查准率)。由此也可以看到,它是针对预测结果(分母)进行评价的。
虽然精准率和准确率这两个词很近,但是却是完全不同的含义。精准率代表对正样本结果中的预测准确程度,而准确率则代表整体的预测准确程度,既包括正样本,也包括负样本。
与此同时,可能我们不仅仅关心查找中有多少正确的,我们还关心在所有正类中有多少被找出来了,即查得全不全,该指标即是查全率。
3.召回率(Recall)
又称查全率,其定义为
根据其分母(TP+FN等于所有正样本的数量)可知,它是针对原样本而言的。其是指在实际为正的样本中被预测为正类的概率。
之所以要关心查得全不全,是因为有时候我们更关注有多少我们关心的样本被漏掉了。比如在重大疾病的筛查中,我们不希望漏查一个有疾病的病人,也即是我们想要把所有的病人预测为病人,哪怕这样会把健康的人错误地预测为病人,这就类似于:宁可错杀一千,也不可放过一个。
这也反映出查准率和查全率是一对矛盾的度量。 一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。比如,我们关注的病人,即把病人看作正类。如果我们想把所有的病人尽可能都找到(查全率高),那么就会造成更多的健康人被错误地判断为病人(错误的正类,也即是FP增大,而且随着查找的进行,FP增大的速度要大于TP增加的速度,越到后面找出病人越难,因为这些病人的病症可能比较轻,而有些健康人可能伴有这类疾病的相似症状,导致大量的健康人被误判,而只能找到少量病人。也即,FP的增加速度远大于TP的增加速度,所以precision会下降;反之,如果我们追求的是在我们诊断为病人的样本中,真正的病人尽可能的多(也即查准率高),那么我们可以选择把最有把握的(病症最明显的)那些患者判断为病人,但是,同时,我们就会漏掉一些病症没有那么明显的真正的病人,导致TP减少,而TP+FN也即总得正类样本(真正的病人)数不变,所以recall会降低。
只有在少数简单的任务中才能同时取得较高的查准率与查全率,这也是为什么我们平时看到的PR曲线会是如下形状。
4.PR曲线
假如有一个PR曲线的示例图,如下所示,其横坐标为recall,纵坐标为precision。

图1:PR曲线
我们先来说一下这个曲线是如何得到的。
给定了分类器的分类结果,对于非离散型的分类器(离散型的分类器是指直接给出正负类分类结果的分类器,如SVM,决策树,至于离散型的分类器该如何画PR曲线会在后面给出),每个样本都会得到一个概率值,该概率值表示分类器将其分为正类的概率,也可以理解为分类器的自信度,也即是分类器有多大的把握将其分为正类。这一点也比较重要,即该概率是指分类器将样本分为正类的概率。我们首先对预测结果的概率值按照降序顺序对样本进行排序,则排在最前面的其概率值最大,也即分类器认为其是最可能的正类样本。按照此样本顺序,逐个把样本作为正类进行预测,正样本个数是逐渐在累加的。每换一个样本(就得到分类器的一次分类结果),就能得到PR曲线上的一个点。以查全率为横坐标,查准率为纵坐标,遍历完所有的样本,就可以得到整个PR曲线。
这里有一点需要注意,为什么要首先对样本进行排序?从上述过程我们可以知道,其类似于描点作图法,如果我们不排序,也可以得到最终的PR曲线。但是,如果不排序,就需要使用不同的策略,-概率值大于阈值的分为正类,概率值低于阈值的分为负类,此处的阈值就是指当前样本对应的概率值。我们需要对样本的概率值进行两两比较来判断类别,每拿到一个概率值,需要跟其他概率一一对比,也即要用两层循环才能完成所有值的对比,其复杂度为,但是排序之后,就不需要对概率值进行比较,只需要从前往后逐个将样本分为正样本,所以只需要遍历一次即可,复杂度为
,不过,排序的复杂度为
,所以排序之后,作图的整体复杂度为
。这就是为什么要先进行排序。
PR曲线直观地显示出学习器在样本总体上的查全率、 查准率。在进行比较时,若一个分类器的PR曲线被另一个分类器的曲线完全"包住" , 则可断言后者的性能优于前者,如图1中,分类器 A 的性能优于分类器 C; 如果两个分类器的 PR 曲线发生了交叉,如图1中的 A 与 B ,则难以一般性地断言两者孰优孰劣。只能在具体的查准率或查全率条件下进行比较然而,在很多情形下,人们往往仍希望把分类器 A 与 B 比出个高低。 这时一个比较合理的判据是比较 PR 曲线节面积的大小,它在一定程度上表征了分类器在查准率和查全率上取得相对"双高"的比例。但这个值不太容易估算,因此人们设计了一些综合考虑查准率、查全率的性能度量。
"平衡点 " (Break-Event Point,简称 BEP)就是这样一个度量,它是" 查准率=查全率"时的取值。例如图1中分类器 C 的 BEP 是 0.64,而基于 BEP的比较,可认为学习器A优于B。
但是平衡点过于简单,使用的不多,更常用的是F1 score,其定义如下
其中P表示Precision, R表示Recall,F1 score是二者的调和平均。
在一些应用中,对查准率和查全率的重视程度有所不同。例如在商品推荐系统中,为了尽可能少打扰用户,更希望推荐内容确是用户感兴趣的,此时查准率更重要;而在逃犯信息检索系统中,更希望尽可能少漏掉逃犯,此时查全率更重要。F1 度量的一般形式是,它能让我们表达出对查准率/查全率的不同偏好,其定义为
其中
度量了查全率对查准率的相对重要性。
时退化为标准的F1,
时更侧重于查全率,
时更侧重于查准率。
是precision与recall的加权调和平均,F1是调和平均,具体公式如下:
表示recall是precision的
倍那么重要,
与算术平均 与几何平均
相比,调和平均更重视较小值。
此外,还可以将与假设检验中的两类错误联系在一起,在假设检验中,一般会把我们关心的对象的对立面作为原假设,比如在做显著性假设检验时,一般原假设为没有显著性差别。
所以,如果我们关心的是正类,那么原假设就是负类。
假设检验中的第一类错误是,当原假设错误时,却接受原假设,即取伪
第二类错误是,当原假设正确时,却拒绝原假设,即取真
那么,结合混淆矩阵可知,
FP 为第一类错误,即把负类(即原假设是负类正确)分为正类(拒绝了原假设)
FN 为第二类错误。即把正类(即原假设是负类错误)分为负类(接收了原假设)
证明如下:
因为
即
所以
注意到PR曲线的两个指标都聚焦于正例(precision与recall的分子都是TP),所以当遇到更需要关注正类样本,而正样本的数量有比较少的任务时,适合使用PR曲线。
与此同时,PR曲线的缺点是当正负类样本不均衡,或者样本的正负分布发生较大变化时PR曲线会很不稳定,而针对此正负样本不均衡的问题,或者想同时关注正类和负类样本时,我们可以使用ROC曲线。
5.ROC曲线
ROC (Receiver Operating Characteristic) 曲线,又称受试者操作特征曲线。该曲线最早应用于二战中雷达信号检测领域,用于区分信号与噪声。后来人们将其用于评价模型的预测能力,ROC 曲线也是基于混淆矩阵得出的。与PR不同的是,ROC曲线使用的指标是真正率(True positive rate, TPR)与假正率 (False positive rate, FPR),其横坐标为FPR, 纵坐标为TPR.
真正率又称为敏感度(sensitivity),假正率又可以看作(1-特异度(specificity)),
特异度可以看作关注负类时的敏感度。
ROC曲线的形状大概为图2中所示。
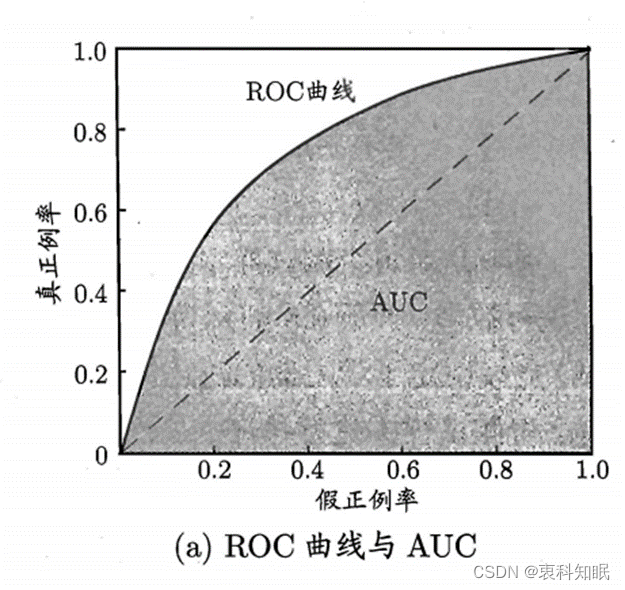
图2:ROC曲线
图中虚线表示随机猜测,所以正常情况下ROC曲线都处于虚线的左上方。
ROC曲线的画法跟PR曲线类似,也是先对分类结果中的样本进行降序排序,然后依次将样本分为正类,从前往后遍历一次所有的样本,最终得到ROC曲线。该过程也可以理解为依次使用从高到低的概率值作为阈值,大于阈值的样本分为正类,小于阈值的样本分为负类。遍历完所有阈值最终得到整个ROC曲线。不过值得注意的是,如果遇到相同概率的样本,也即前后若干个概率值相同,如果我们还是以重复的概率值作为阈值进行计算,那么等同于重复前面的工作,得到的也是ROC曲线上的点,此时,为了避免重复,遇到相同阈值时,我们直接将其对应的样本分为正样本(也即加入逐个扩大的正样本集合),重复此过程,直至遇到与该阈值不同的概率值。
为了更加直观地理解该过程,下图3是一个具体的例子,共有20个样本,其中10个正类,10个负类,左侧是对应的ROC曲线,图中标记点旁边的数值表示使用的阈值,右侧是样本的真实标签(Class列)与分类器给出的预测概率(Score列)。
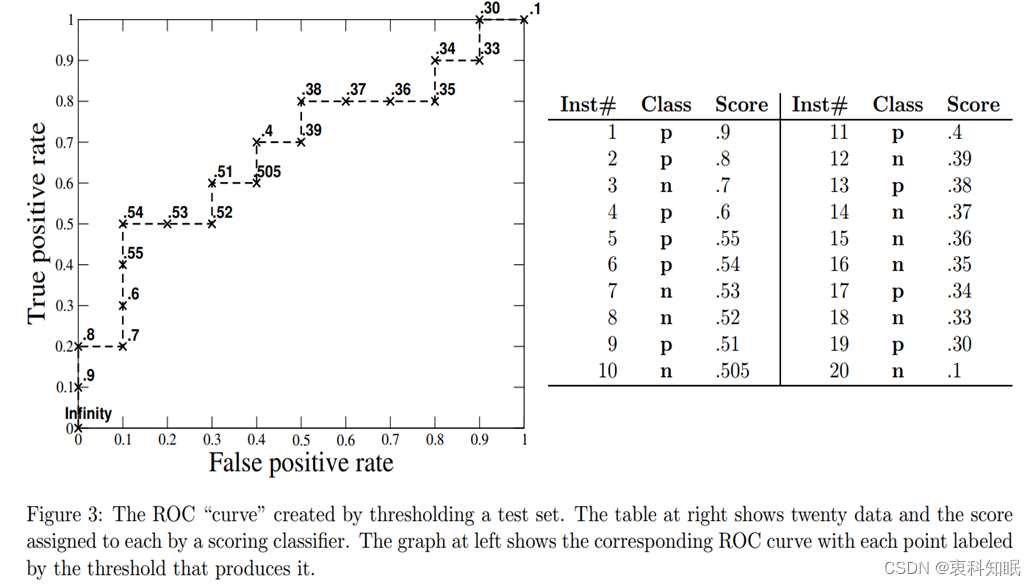
图3
由此我们可知,如果我们选择的阈值非常大,比如正无穷,因为我们关注点的是分类器将样本分为正类的概率,那么如果阈值为正无穷,所有的样本将被分为负类,所以TP=FP=0, 那么TPR与FPR也都等于0,此时对应着ROC曲线上的原点(0,0)。相反,如果我们的阈值非常小,比如为负无穷,那么所有的样本将被分为正类,则FN=TN=0, 那么,TPR=FPR=1, 此时对应着ROC曲线右上方的(1,1)点。还有一个比较特殊的点(0,1),该点意味着,FPR=0, TPR=1, 也即是FP=0, FN=0.
即所有的样本都分对了,所以该点是完美分类点。所以ROC曲线越靠近这个点表示分类器的分类效果越好。
还有一种更直观地绘制ROC曲线的方法。首先,根据样本标签统计出 正负样本的数量,假设正样本数量为P,负样本数量为N;接下来,把横轴的刻度间隔设置为1/N,纵轴的刻度间隔设置为1/P;再根据模型输出的预测概率对样本进行排序(从高到低);依次遍历样本,同时从零点开始绘制ROC曲线,每遇到一个正样本就沿纵轴方向绘制一个刻度间隔的曲线,每遇到一个负样本就沿横轴方向绘制一个刻度间隔的曲线,直到遍历完所有样本,曲线最终停在(1,1)这个点,整个ROC曲线绘制完成。
我们注意到TPR与FPR的分母,TP+FN=所有的正类样本总数, FP+TN=所有的负类样本总数。
也即,TPR与FPR都是针对实际样本的,而不是针对分类结果的(其分母是常数,而如果是针对分类结果,其分母会变化,如precision的分母)。所以即使正负类的数量各自发生了改变,也不会互相影响。也就是说,即使正例与负例的比例发生了很大变化,ROC曲线也不会产生大的变化,而像Precision使用的TP和FP就会随着正负类样本比例的变化而变化,即易受类别分布改变的影响。也就是说ROC曲线对样本不均衡比价鲁棒,这也是ROC曲线优于PR曲线的地方。如下图4所示,

图4 此处实线和虚线表示两个不同的分类器
图中负例增加了10倍,ROC曲线没有改变,而PR曲线则变了很多。
文献[1]中说当正负类样本比例发生变化时,ROC曲线不变(identical),我猜测应该是没有太大变化,而不是一点都不变,根据TPR与FPR的定义,
就拿图4中的例子来说,负样本增加10倍,正样本不变
那么TP, FN都不会变,所以TPR是不变的,但是,并不能保证FP与TN会以相同的倍数变化,也许二者变化的倍数很近(比如新增的样本与原来的样本分布相同),但是变化的倍数应该不会完全一致,所以我猜测FPR会发生微小的变化,但是不影响ROC的大体走势。
大多数情况下这种稳定性被认为是优点,但是有时也是缺点,因为负样本增多,FP也会成倍增加,如果是比较关心正类样本的准率率的话,那么就会导致precision(precision=TP/(TP+FP))下降(此时PR曲线会更合适刻画这种变化)。
第一部分就先到这吧,太长了容易看困,哈哈哈
如果还不困,第二部分由此进入:机器学习分类器评价指标详解(Precision, Recall, PR, ROC, AUC等)(二)
参考:
[1] ROC Graphs: Notes and Practical Considerations for Data Mining Researchers
[2] 周志华《机器学习》
[3] Probabilistic interpretation of AUC | 0-fold Cross-Validation
[4] Measuring classifier performance: a coherent alternative to the area under the ROC curve
[5] Probabilistic output for SVM and comparisons to regularized likelihood methods
[6] A Note on Platt’s Probabilistic Outputs for Support Vector Machines
[7] LIBSVM: A Library for Support Vector Machines
版权归原作者 衷科知眠 所有, 如有侵权,请联系我们删除。