

如果你从事软件开发,你就会知道 Bug 是生活的一部分。当你开始你的项目时,Bug 就可能存在,当你把你的产品交付给客户时,Bug 也可能存在。在过去的几十年中,软件开发社区已经开发了许多的技术工具、IDE、代码库等来帮助开发者尽早地发现 Bug,以避免在产品交付的时候仍旧存在 Bug。
不幸的是,机器学习开发人员和数据科学家并没有享受到传统软件所提供的强大的调试工具。这就是为什么我们中的许多人在训练脚本中经常性使用 “print” 语句。这一问题在分布式训练和在集群上开展大规模实验时尤其突出,虽然你可以保存工作日志,但是通过这些工作日志来定位 Bug 简直无异于大海捞针。
在这篇文章中,将讨论调试机器学习代码与传统软件的不同之处,以及为什么调试机器学习代码要困难得多。然后,将展示如何使用更好的机制来捕获调试信息、在训练期间实时监控常见问题、发现问题后及时干预以防止发生进一步的错误及浪费计算机资源。
具体地,主要通过 Amazon SageMaker Debugger(一个用于机器学习模型调试的开源库)实现上述目的。
机器学习调试与传统软件开发调试有何不同?
如果机器学习以软件的形式呈现,那么将能够找到许多调试工具来解决 Bug 的问题,比如:
- 使用集成开发环境(IDE),设置断点并检查中间变量;
- 使用开发所使用的编程语言进行异常处理和类型检查;
- 使用静态代码分析工具查找错误并检查是否符合标准;
- 使用诸如 gdb 的调试库;
- 使用日志和“print”语句。
但是现阶段的机器学习调试仍然是一项十分困难的工作,主要原因如下:
- 机器学习不仅仅是简单的代码
首先,让我们考察一个典型的数据科学问题——面对一个数据集和一个对应的问题描述,需要建立一个基于数据的模型来实现预测,并且评价该模型的准确性,然后在模型达到要求后,进行部署、集成、销售等。
相较于传统软件,机器学习代码涉及到更多的非固定的组分。如:数据集、模型结构、微调过后的模型权重、优化算法及其参数、训练后的梯度等。
在某种意义上,机器学习代码在训练阶段是“动态的”。因为模型本身是随着模型训练而改变或发展的。在训练过程中,模型中的数百万个参数或权重每一步都在变化。一旦训练完成,它就会停止改变,此时,在训练过程中没有发现的错误现在已经成为模型的一部分。而传统软件代码中,有严格的逻辑和规则,不会在每次运行时改变,即使有条件分支,但代码仍然是“静态的”。
调试这个动态的、不断演化的代码需要不同于传统软件开发调试的工具。需要的是通过分析数百万个不断变化的变量来监测训练进度,并在满足某些条件时采取动作。主要通过监视模型参数、优化参数和指标,及时发现诸如梯度消失、activation saturation 等问题。
而调试工具的缺乏,导致大部分机器学习开发人员通过 “print” 语句分析模型训练的过程。
- 难以在机器学习训练过程中实施监测和干预
考虑到效率和经济因素,很多机器学习训练代码运行在集群上,或者至少在各大云平台中,大部分都不是在个人计算机上运行。而在集群上训练模型时设置断点几乎是不可能的。
当你的编程范式改变时,你的调试工具和方法也应该随之改变。在集群上进行分布式训练时,监视进度的主要方法是插入代码以生成日志以供分析。但这是不够的,相反,需要的是一种更简单的方法来实时监控进度,并在满足特定条件时发出提醒或采取一些行动。而这就给我们带来了下一个挑战。
- 调试机器学习代码可能需要大量重写或改变框架
机器学习代码的核心依赖于一系列高度优化的线性代数子程序,这些语言通常用C语言、C++语言和CUDA语言编写。更高层次的框架,如TensorFlow、PyTorch、MXNet和其他框架,对底层程序代码进行封装,并提供一种设计和训练模型的简便方法。当减少代码复杂度时,一定程度上提升了调试的困难度。
机器学习框架的实现方式有以下两种:(1)声明式方法,将模型体系结构定义为一个计算图,然后进行编译、优化和执行(例如TensorFlow)(2)命令式方法,将模型体系结构定义为一个计算图,然后按定义执行(例如Pythorch,TensorFlow eager mode)。在声明式方法中,无法访问优化的计算图,因此调试可能会更困难。在命令式方法中,调试更容易,但需要在较低的级别上测试代码以获取调试数据,在某些情况下,还需要权衡性能。
为了更好地进行调试,必须编写额外的代码加入到训练脚本中,或者重写代码以支持不同的框架。或者更糟的是,在多个框架上维护相同的模型。而这些操作可能会引入更多的 bug。
- Bug 会让开发者在硬件、时间上付出更多的成本
大多数机器学习 Bug 可以在训练过程的早期发现,如一些常见的问题:初始化不好、梯度消失、activation saturation 等。而其他问题则是随着时间的推移而显现的,如过拟合等。而无论是训练早期还是训练后期发现的问题,都将导致资源的浪费。
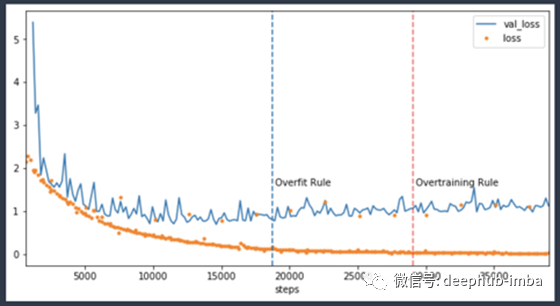
在上图中可以看到,当模型开始超过20k步时,应该停止。当训练持续到40k步左右,计算成本是原来的两倍。这样的问题很常见,因为普遍存在着指定了固定数量的 epochs 来执行训练,然后出去吃午饭的情况。
机器学习调试涉及到哪些操作?
一个好的机器学习调试工具或方法应该具备的主要功能如下:
- 捕获(capture)
能够捕获模型和优化器的有关参数和指标数据。开发人员能够指定数据采集频率,并对调试数据进行后处理操作。
- 反应(react)
能够监视捕获数据中的变更并作出反应。开发人员能够指定模型在满足条件(如:梯度消失、过拟合)时停止训练。
- 分析(analyze)
能够允许使用者在模型训练期间实时分析捕获的数据。开发人员能够对捕获的数据进行脱机分析。
使用 Amazon SageMaker Debugger 进行机器学习模型的开发调试
Amazon SageMaker Debugger 使得开发人员能够监测模型训练情况,实现针对训练阶段的模型参数的监测、记录、分析。可以通过以下两种途径使用 Amazon SageMaker Debugger:
- Amazon SageMaker managed training 方式
当使用 Amazon Sagemaker 训练模型时,将自动启用 Amazon SageMaker Debugger。并且不需要对训练脚本进行任何更改,只需指定要监视的问题,它就会自动运行监视,可以捕获梯度消失、过拟合等问题。还可以在训练期间记录张量,并将其保存在 Amazon S3中,以便进行实时或离线分析。
smdebug开源库方式
可以在 TensorFlow、Keras、PyTorch、MXNet或XGBoost 等编写的训练代码中加入
smdebug
开源库相关代码,以进行调试。
具体地,Amazon SageMaker debugger 的 capture、react、analyze 使用方法如下:
通过 debugger hooks 获得调试数据
机器学习训练中的大部分代码都是为了实现对于模型参数的优化。通过优化算法,对比预测值和真实值、计算梯度、更新权重。通常涉及到百万数量级的权重参数和偏差参数。

为了在训练阶段捕获重要信息,Amazon SageMaker Debugger 自动将 Hooks 添加到 TensorFlow、Keras、PyTorch、MXNet或XGBoost代码中。当指定SageMaker Debugger Hook 时,可以针对性地保存重要数据和信息。Amazon SageMaker Debugger 提供一个预定义的张量列表,可以通过这个列表保存权重、偏差、梯度、损失、优化器变量等参数。也可以通过声明 regex 字符串指定需要捕获的模型特定层中的特定张量。
在 Amazon SageMaker 使用 Hooks
如果使用Amazon SageMaker 进行模型训练,则会自动配置Amazon SageMaker Debugger,无需更改训练代码主体。只需要声明如下内容:
fromsagemaker.debuggerimportRule, DebuggerHookConfig
debugger_hook_config = DebuggerHookConfig(
hook_parameters={"save_interval": '100'},
collection_configs=[
CollectionConfig("losses"),
CollectionConfig("weights"),
CollectionConfig("gradients"),
CollectionConfig("biases")]
)
通过上述代码,Hook 将间隔100步自动存储 losses、weights、gradients、biases等参数。当然,也可以指定采样起止步数。
当调用SageMaker TensorFlow estimator 时,通过 Amazon SageMaker Python SDK将 Hook 传递给 debugger_Hook_config参数。代码如下:
tf_estimator = TensorFlow(entry_point = 'tf-training-script.py',
...
...
debugger_hook_config = debugger_hook_config)
本地环境下通过
smdebug
开源库使用 Hooks
当在个人电脑中进行模型训练或者 Amazon SageMaker 未能够自动配置 Hooks 时,可以使用
smdebug
库手动配置。以 Keras 和 PyTorch 为例:
在 Keras 代码中使用 Hook
importsmdebug.tensorflowassmd
job_name = 'tf-debug-job'
hook = smd.KerasHook(out_dir=f'./smd_outputs/{job_name}',
tensorboard_dir=f'./tb_logs/{job_name}',
save_config=smd.SaveConfig(save_interval=1),
include_collections=['gradients', 'biases'])
opt = tf.keras.optimizers.SGD(learning_rate=0.01, momentum=0.9, name='SGD')
opt = hook.wrap_optimizer(opt)
通过上述代码,首先导入
smdebug
包,然后实例化 KerasHook。通过 KerasHook 保存梯度和偏差张量至
out_dir
,保存 TensorBoard 日志到
tensorboard_dir
。
在 PyTorch 代码中使用 Hook
importsmdebug.pytorchassmd
net = get_network()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
job_name = 'pytorch-debug-job'
hook = smd.Hook(out_dir=f'./smd_outputs/{job_name}',
save_config=smd.SaveConfig(save_interval=10),
include_collections=['gradients', 'biases'])
hook.register_module(net)
hook.register_loss(criterion)
通过上述代码,首先导入
smdebug
包,然后实例化 Hook,最后将 hook 添加到神经网络中。除了对优化函数使用 hook,也可以对损失函数使用 hook。
此外,可以通过
hook.record_tensor_value
来记录指定的张量数据。
forepochinrange(10):
running_loss = 0.0
fori, datainenumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
# Use hook to record tensors
hook.record_tensor_value(tensor_name="loss", tensor_value=loss)
loss.backward()
optimizer.step()
使用 debugger rules 对调试数据变更做出反应
如果只是单纯的对数据进行采样记录,并不能很好的实现调试工作。真正意义上实现调试,要求在训练阶段能够实时的做出反应。因此引入 debugger rules,对代码运行过程中的某一条件进行监测,当条件发生改变时做出停止训练、发生通知等操作。
Amazon SageMaker Debugger 内置了部分常用的条件判断函数:死亡节点(dead relu)、张量爆炸(exploding tensor)、权重初始化不良(poor weight initialization)、激活函数饱和(saturated activation)、梯度消失(vanishing gradient)、分类不平衡(calss imbalance)、过拟合等。如果想要自定义条件,可以通过
smdebug
库函数进一步编写。
如果使用Amazon SageMaker 进行模型训练,则会自动运行 debugger rules。当然也可以使用
smdebug
库在本地环境运行相关函数。
在 Amazon SageMaker 中使用 debugger rules
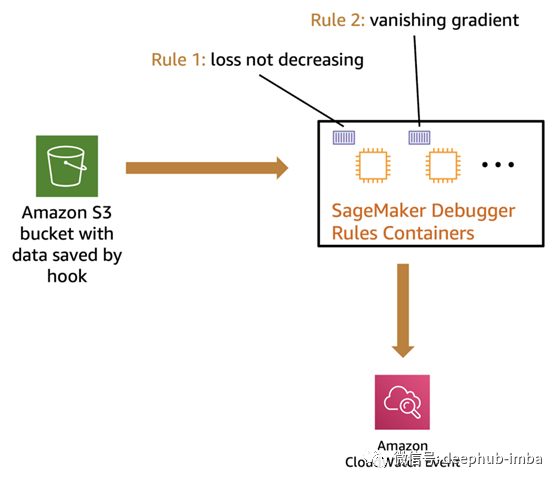
具体代码如下:
debug_rules = [
Rule.sagemaker(rule_configs.overtraining()),
Rule.sagemaker(rule_configs.overfit()),
Rule.custom(name='MyCustomRule',
image_uri='840043622174.dkr.ecr.us-east-2.amazonaws.com/sagemaker-debugger-rule-evaluator:latest',
instance_type='ml.t3.medium',
source='rules/my_custom_rule.py',
rule_to_invoke='CustomGradientRule',
volume_size_in_gb=30,
rule_parameters={"threshold": "20.0"})
]
通过上述代码,添加了两个内置条件(overtraining,overfitting)和一个自定义条件(customGradientRule)。
编写自定义条件,需要声明需要调用的 SageMaker 资源(本例中为 t3.medium)。
在SageMaker framework estimator 函数(例如下面的TensorFlow estimator)中,可以将规则配置作为其中的 rules 参数。这将指示Amazon SageMaker不仅启动一个训练进程,还启动 rules 进程。

在本地环境中使用 debugger rules
下面的代码将演示如何定义一个名为CustomGradientRule的规则。通过该规则检查梯度的绝对平均值是否大于某个阈值,如果没有指定阈值,则阈值为10。
fromsmdebug.rulesimportRule
classCustomGradientRule(Rule):
def__init__(self, base_trial, threshold=10.0):
super().__init__(base_trial)
self.threshold = float(threshold)
definvoke_at_step(self, step):
fortnameinself.base_trial.tensor_names(collection="gradients"):
t = self.base_trial.tensor(tname)
abs_mean = t.reduction_value(step, "mean", abs=True)
ifabs_mean>self.threshold:
returnTrue
returnFalse
为了调用该规则,需要创建一个rule_object:
fromsmdebug.rulesimportinvoke_rule
fromsmdebug.trialsimportcreate_trial
trial = create_trial(path=’./smd_outputs/<JOB_NAME>)
rule_obj = CustomVanishingGradientRule(trial, threshold=0.0001)
invoke_rule(rule_obj, start_step=0, end_step=None)
使用 Amazon SageMaker Debugger 分析调试数据
使用hook可以在训练期间导出数据,如权重、梯度和其他数据;而 rule 允许在训练阶段监测模型条件是否改变,以便采取行动。在某些情况下,开发者只想分析原始数据并将其绘制出来,以找到尚不了解的问题。具体的可视化方法如下:
- 通过 Amazon SageMaker Studio 进行可视化
Amazon SageMaker Studio 建立在 Jupyter Notebook 之上,它集成了跟踪实验、在训练期间可视化性能曲线以及在实验中比较不同试验结果的功能。还可以通过选择 debugger hook 保存的数据值来调出自定义图表。
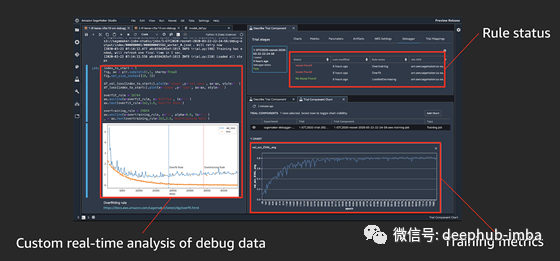
- 本地环境下使用
smdebug库进行可视化
以如下代码为例:
hook = smd.Hook(out_dir=f'./smd_outputs/{job_name}',
save_config=smd.SaveConfig(save_interval=10),
include_collections=['gradients', 'biases'])
首先通过 Hook 存储 梯度和偏差。
importsmdebug.pytorchassmd
trial = smd.create_trial(path=PATH_TO_S3_OR_LOCAL_DIR')
然后建立一个 trial,以便实时分析。
trial.tensor_names()
通过 tensor_names() 查询保存的张量:
[2020-03-3006:02:17.108ip-172-31-28-67:31414INFOlocal_trial.py:35] Loadingtrialpytorch-exp03-30-05-53-52atpath ./smd_outputs/pytorch-exp03-30-05-53-52
[8]:
['CrossEntropyLoss_output_0',
'Net_conv1.bias',
'Net_conv2.bias',
'Net_fc1.bias',
'Net_fc2.bias',
'Net_fc3.bias',
'gradient/Net_conv1.bias',
'gradient/Net_conv1.weight',
'gradient/Net_conv2.bias',
'gradient/Net_conv2.weight',
'gradient/Net_fc1.bias',
'gradient/Net_fc1.weight',
'gradient/Net_fc2.bias',
'gradient/Net_fc2.weight',
'gradient/Net_fc3.bias',
'gradient/Net_fc3.weight',
'loss_output_0']
通过 trail.tensor().values() 查询所有数据:
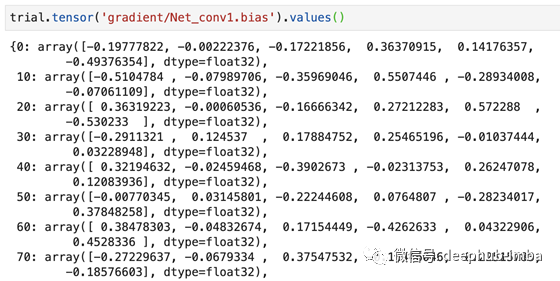
注意到梯度每10步保存一次,这是我们在 hook 中预先指定的。通过在循环中运行上述命令来查询最近的值,可以在训练期间检索张量。这样,可以绘制性能曲线,或在训练过程中可视化权重的变化。

Amazon SageMaker Debugger 工作流程
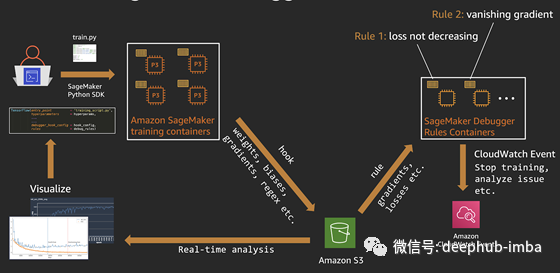
- 使用SageMaker Python SDK和各框架(TensorFlow、PyTorch等)开始Amazon SageMaker 上的深度学习训练任务。
- Amazon SageMaker在指定数量的CPU或GPU上启动训练进程。同时SageMaker启动 rule 进程以监控训练过程。
- 使用debug Hook config,Amazon SageMaker把权重、偏差和其他张量保存到指定的S3位置。
- 在 Hook 采集数据的基础上, rule 进程执行指定的条件监控。
- 当指定的条件发生状态变化,采取停止训练、发生通知等行动。
- 可以使用smdebug库来创建 trial 对象。trail对象可用于查询张量,以便于执行实时或脱机分析及可视化。
总结
调试是一项具有挑战性的工作,本文中讨论了机器学习开发调试和普通软件开发调试的差异,并且给出了通过 Amazon SageMaker Debugger 进行调试的办法。
而使用Amazon SageMaker Debugger的三种途径如下:
- 通过在 Amazon SageMaker 全托管服务平台使用,将免去手动配置等操作。
- 通过
smdebug开源库在个人电脑等本地环境使用,需要进行一定的手动配置。 - 可以通过 Amazon SageMaker 进行模型训练,通过本地环境执行 rules 对调试数据进行可视化分析。
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********