
更多可见计算机视觉-Paper&Code - 知乎
小目标检测
数据方面
- 将图像resize成不同的大小
- 对小目标进行数据增强,过采样策略oversampling,重复正样本数
- 在图片内用实例分割的Mask抠出小目标图片再使用paste等方法
常见的几种数据增强方法如下
- cutout:将图片区域随机扣除
- cutmix:将cutout扣除后的区域用同一batch中样本进行填充
- mixup:随机将两张图片进行融合
- mosaic:在将四张样本图片拼接起来,模型在一个batch中看到了4倍更多的信息

分割中常用的8倍+1的输入大小,513 (PASCAL VOC) 或者 769 (Cityscapes)
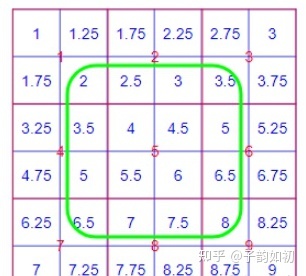
align_corners=False默认

align_corners =True 分割中常用
Label Smoothing
Label Smoothing Regularization(LSR),即标签平滑正则化。主要也可以在模型蒸馏里进行soft label学习而不是one hot。
onehot:便于生成、但类别间无关,对错误标签很敏感,易高置信度过拟合
soft label:能够赋予不同类别间的一定相关性。本质上LSR可以降低模型的置信度,抑制正负样本输出差值,防止模型过拟合,从而提高其健壮性和性能
模型方面
- 提高细节信息,增加空洞卷积,将下采样从32倍改为8倍
- 传统的分类网络为了减少计算量,都使用到了下采样,而下采样过多,会导致小目标的信息在最后的特征图上只有几个像素(甚至更少),信息损失较多
- 下采样扩张的感受野比较利于大目标检测,而对于小目标,感受野可能会大于小目标本身,导致效果较差
- 空洞卷积可以很好的扩大卷积核的感受野,可以很好的保留图像的空间特征,也不会损失图像信息,适用于小目标检测(不过对于像素级任务空洞卷积会导致像素连续信息丢失)
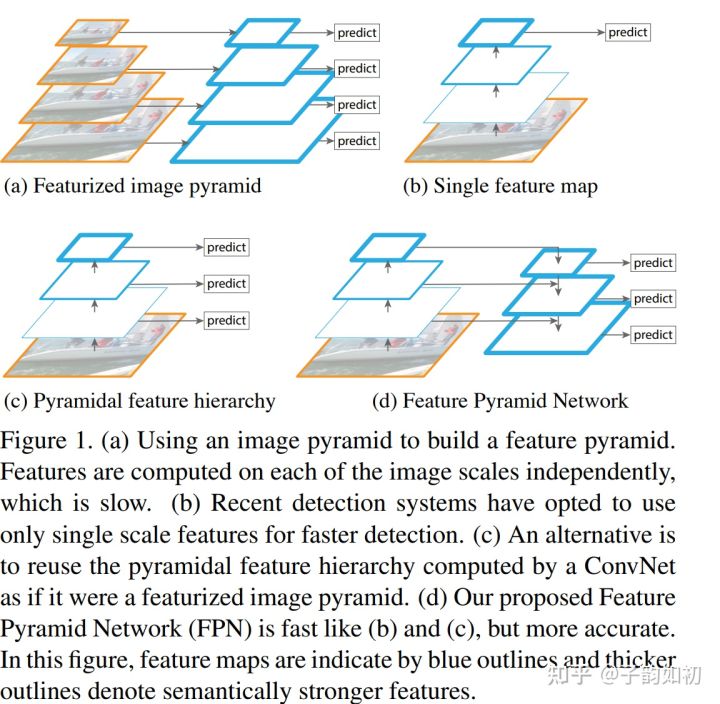
- 特征金字塔网络FPN
FPN论文链接
保持高分辨率浅层特征图感受野小适合小目标检测,细节信息更加丰富。深层特征图感受野大适合大目标检测,语义信息更丰富
- Scale Normalization for Image Pyramids

在训练时,每次回传那些大小在预先指定范围内的proposal的gradient,而忽略掉过大或者过小的proposal;在测试时,建立大小不同的Image Pyramid,同样只保留那些大小在指定范围内的输出结果
- 更多更稠密的Anchor
5.** GAN方法**
使用GAN对小目标生成一个和大目标很相似的Super-resolved Feature,然后把这个Super-resolved Feature叠加在原来的小目标的特征图上,以此增强对小目标特征表达来提升小目标的检测性能
- 利用Context信息
检测人脸时,图片中不会仅仅只有一张脸,会有其他部位
- loss上增加小目标的权重
样本不均衡
子韵如初:Paper Reading - 综述系列 - 语义分割中正负样本不均衡问题
Paper Reading - Loss系列 - OHEM Training Region-based Object Detectors with Online Hard Example Mining - 知乎
目标遮挡
Repulsion Loss: Detecting Pedestrians in a Crowd
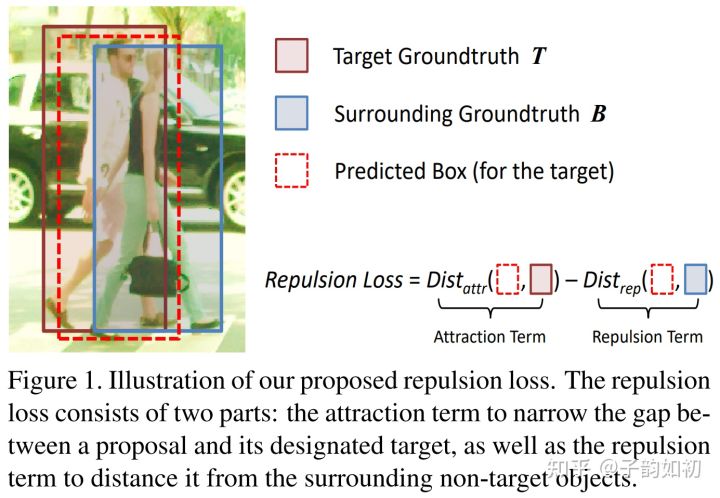
行人之间互相遮挡,导致传统的检测器容易受遮挡的干扰。提出了Repulsion Loss来尽可能让预测框贴近真实框的同时,又能与同类排斥
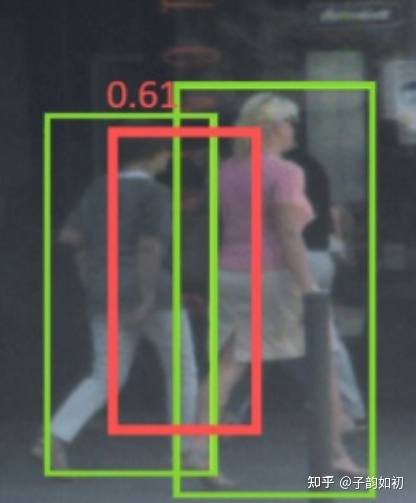
假设我们目标行人是左一,但是他被左二被遮挡了。那么左二的GT会导致模型的预测框去往左二移动shift
其次,NMS操作是为了抑制去除掉多余的框。 左一的预测框因为距离左二太近,会被左二的预测框给抑制,导致出现漏检。导致任务对NMS阈值有很强的的敏感性,阈值太低了会带来漏检,阈值太高了会标出错误的目标
现有的方法仅仅要求预测框尽可能靠近目标框,而没有考虑周围附近的物体。因此提出Repulsion Loss,该损失函数在要求预测框Pred靠近目标框Target(吸引)的同时,也要求预测框Pred远离其他不属于目标Target**的真实框(排斥)**该损失函数很好的提升了行人检测模型的性能,并且降低了NMS对阈值的敏感性
More
人体姿态识别中,如图,应该怎么样区分那条腿属于哪个人的呢。可通过人体部位距离进行判定

版权归原作者 子韵如初 所有, 如有侵权,请联系我们删除。