
论文地址:https://arxiv.org/pdf/1706.02413.pdf
代码地址:https://github.com/yanx27/Pointnet_Pointnet2_pytorch
一、论文动机
1.PointNet只使用了MLP和最大池化,没有能力捕获局部特征,然而局部结构已被证明是卷积结构成功的重要因素(就是感受野越来越大,由局部逐渐到整体)
2.PointNet里全局特征直接由max pooling获得,这会有巨大的信息损失
3.分割任务的全局特征是直接与点特征拼接,生成的特征辨别能力有限
二、论文方法
1.使用多个set abstraction层叠加,逐步提取局部特征
2.分割任务使用encoder-decoder结构,先降采样再上采样,通过多个set abstraction结构实现多层次的降采样,得到不同规模的point-wise feature,最后一个输出可以看作global feature,decoder通过反向插值和skip connection将对应层的特征进行拼接,实现上采样的同时还可以获得local+global的point-wise feature,使得最终的特征更具辨识力。
三、网络结构
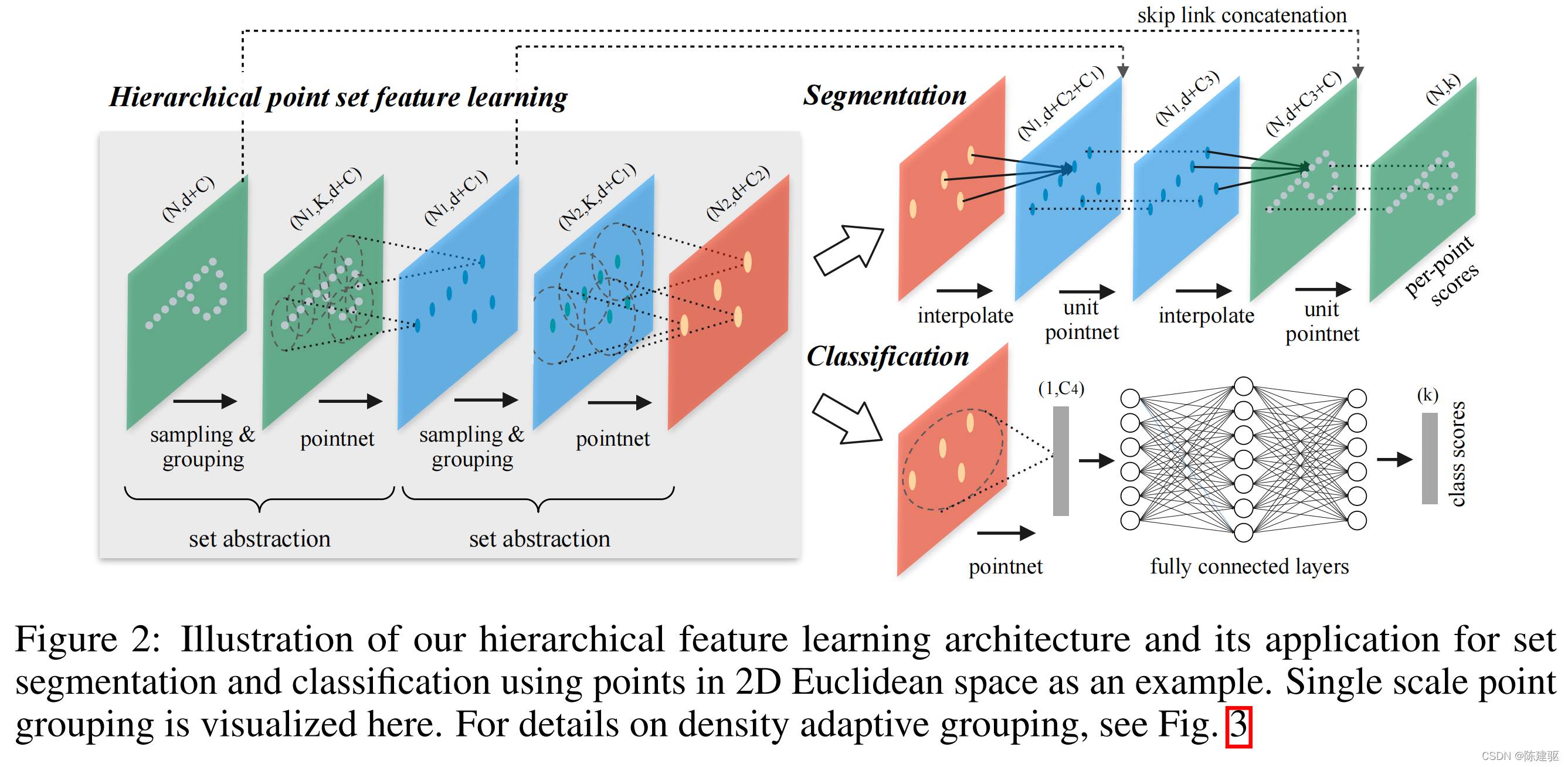
pointnet++先使用集合抽象层提取局部特征,从小的邻域获得精细的几何结构,通过叠加集合抽象层,这些局部特征被进一步划分为更大的单元,并处理产生更高层次的特征,这个过程不断重复,直到获取整个点集的特征。
Set Abstraction
1.采样层
在输入点集中使用最远点采样(FPS)来选取中心点,该算法选取的中心点可以更好的覆盖点集
该层的输入为N*(d+c),d为坐标,c为额外特征,输出为 N1*(d),N1为采样后的中心点。(具体看代码)
FPS流程:先随机选一个点加入集合,计算其他点离它的距离,选择最远的点,加入集合,再计算其他点离集合的位置(后面集合里面有好多点,算这个点到集合里面所有点的距离,选最小的作为它离集合的距离),重复上面的,直到选择了我们提前设定的N1个中心点。
2.分组层
以每个选取的中心点为中心,找到其规模内的K个邻点,共同组成一个局部区域
该层的输入N*(d+c)和N1*(d),分组完输出N1K(d+c),其中K为我们选定的邻域规模
邻域的选取有两种方法:KNN选择离中心点最近的K个点
球半径查询,选定半径球体,如果球体里面的点大于K,直接取前K个,不足的话就重采样,凑够K。
3.Pointnet层
输入N1K(d+c),输出N1*(d+c1),c1是指卷积完的局部特征。
首先将局部区域中的点坐标转换为相对于质心的坐标,然后通过相对坐标和点特征,我们可以捕获到局部区域内点与点的关系。
非均匀采样密度下的鲁棒性学习
因为pointnet++主要是对局部特征的一个提取,但这样面临一个问题,就是稀疏点云的局部邻域训练可能不能很好的挖掘点云的局部信息。这里pointnet++提出两种方案:
1.Multi-scale grouping(MSG)
对当前层的每个中心点,取不同的radius,得到多个不同大小的同心圆,也就是得到了多个相同中心但规模不同的局部区域,分别对这些局部区域进行pointnet提取,然后再将所有表征拼接。
2.Multi-resolution grouping(MRG)
MSG的计算量特别大,而MRG的某一层特征是由两部分组成的,左边是对上一层的各个局部邻域特征进行聚合,右边是用一个单一的pointnet在当前局部区域处理原始点云。具体看代码部分。
上采样
Pointnet++会随着网络逐层降采样点,这样可以保证网络获取足够的全局信息,但这样就无法用于分割,因为分割必须输入输出点一样,所以常见的方法就是插值上采样,上采样使用的反向插值,根据上一层距离当前层要推理点最近的K个点的特征进行加权,离得远权重就小,离得近就大,插值出推理点特征。具体见代码的Feature Propagation(FP)模块
分类和分割网络结构
分类网络:
先使用多层PointNetSetAbstractionMSG类,最后使用一个PointNetSetAbstraction类,将所有点分为一组,得到全局特征,三个全连接层,前两个有bn,relu,dropout
分割网络:
先使用多层PointNetSetAbstractionMSG类,然后使用相同个数的PointNetFeaturePropagation上采样类最终得到 [B,N,D1],然后使用conv1d对点特征降维到K,conv1d后bn,relu,dropout。
四、代码阅读
import torch
import torch.nn as nn
import torch.nn.functional as F
from time import time
import numpy as np
#打印时间
def timeit(tag, t):
print("{}: {}s".format(tag, time() - t))
return time()
#对点云数据进行归一化处理,以centor为中心,球半径为1
def pc_normalize(pc):
#pc维度[n,3]
l = pc.shape[0]
#求中心,对pc数组的每一列求平均值,得到[x_mean,y_mean,z_mean]
centroid = np.mean(pc, axis=0)
#求这个点集里面的点到中心点的相对坐标
pc = pc - centroid
#将同一行的元素求平方再相加,再开方求最大。x^2+y^2+z^2,得到最大标准差
m = np.max(np.sqrt(np.sum(pc**2, axis=1)))
#进行归一化,这里使用的是Z-score标准化方法
pc = pc / m
return pc
#主要用来在ball query过程中确定每一个点距离采样点的距离,返回的是两组点之间的欧氏距离,N*M矩阵
def square_distance(src, dst):
"""
Calculate Euclid distance between each two points.
src^T * dst = xn * xm + yn * ym + zn * zm;
sum(src^2, dim=-1) = xn*xn + yn*yn + zn*zn;
sum(dst^2, dim=-1) = xm*xm + ym*ym + zm*zm;
dist = (xn - xm)^2 + (yn - ym)^2 + (zn - zm)^2
= sum(src**2,dim=-1)+sum(dst**2,dim=-1)-2*src^T*dst
Input:
src: source points, [B, N, C]
dst: target points, [B, M, C]
Output:
dist: per-point square distance, [B, N, M]
"""
B, N, _ = src.shape
_, M, _ = dst.shape
#torch.matmul也是一种矩阵相乘操作,但是它具有广播机制,可以进行维度不同的张量相乘
dist = -2 * torch.matmul(src, dst.permute(0, 2, 1)) #[B,N,M]
dist += torch.sum(src ** 2, -1).view(B, N, 1) #[B,N,M]+[B,N,1]dist每一列都加上后面的列值
dist += torch.sum(dst ** 2, -1).view(B, 1, M) #[B,N,M]+[B,1,N]dist每一行都加上后面的行值
return dist
#按照输入的点云数据和索引返回索引的点云数据
def index_points(points, idx):
"""
Input:
points: input points data, [B, N, C]
idx: sample index data, [B, S]
Return:
new_points:, indexed points data, [B, S, C]
"""
device = points.device
B = points.shape[0]
view_shape = list(idx.shape) #view_shape=[B,S]
view_shape[1:] = [1] * (len(view_shape) - 1) #去掉第零个数,其余变为1,[B,1]
repeat_shape = list(idx.shape)
repeat_shape[0] = 1 #[1,S]
#arrange生成[0,...,B-1],view后变为列向量[B,1],repeat后[B,S]
batch_indices = torch.arange(B, dtype=torch.long).to(device).view(view_shape).repeat(repeat_shape)
#下面这个感觉理解不了,后面自己敲一下验证一波
new_points = points[batch_indices, idx, :]#从points中取出每个batch_indices对应索引的数据点
return new_points
#最远点采样算法,返回的是npoint个采样点在原始点云中的索引
def farthest_point_sample(xyz, npoint):
"""
Input:
xyz: pointcloud data, [B, N, 3]
npoint: number of samples
Return:
centroids: sampled pointcloud index, [B, npoint]
"""
device = xyz.device
B, N, C = xyz.shape
#初始化一个中心点矩阵,用于存储采样点的索引位置
centroids = torch.zeros(B, npoint, dtype=torch.long).to(device)
#distance矩阵用于记录某个batch中所有点到某个采样点的距离,初始值很大,后面会迭代
distance = torch.ones(B, N).to(device) * 1e10
#farthest表示当前最远的点,也是随机初始化,范围0-N,初始化B个
farthest = torch.randint(0, N, (B,), dtype=torch.long).to(device)
#初始化0-B-1的数组
batch_indices = torch.arange(B, dtype=torch.long).to(device)
for i in range(npoint):
centroids[:, i] = farthest#先把第一个随机采样点下标放入
centroid = xyz[batch_indices, farthest, :].view(B, 1, 3)#取出初始化的B个点的坐标
dist = torch.sum((xyz - centroid) ** 2, -1) #求每个batch里面每个点到中心点的距离 [B,N]
#建立一个mask,如果dist中记录的距离小于distance里的,则更新distance的值,这样distance里保留的就是每个点距离所有已采样的点的最小距离
mask = dist < distance
distance[mask] = dist[mask]
farthest = torch.max(distance, -1)[1] #得到最大距离的下标作为下一次的选择点
return centroids
#用于寻找球形领域中的点,S为FPS得到的中心点个数
def query_ball_point(radius, nsample, xyz, new_xyz):
"""
Input:
radius: local region radius
nsample: max sample number in local region
xyz: all points, [B, N, 3]
new_xyz: query points, [B, S, 3]
Return:
group_idx: grouped points index, [B, S, nsample]
"""
device = xyz.device
B, N, C = xyz.shape
_, S, _ = new_xyz.shape
group_idx = torch.arange(N, dtype=torch.long).to(device).view(1, 1, N).repeat([B, S, 1])
sqrdists = square_distance(new_xyz, xyz) #计算中心点坐标与全部点坐标的距离 [B,S,N]
group_idx[sqrdists > radius ** 2] = N #找到所有大于半径的,其group_idx直接置N,其余不变
group_idx = group_idx.sort(dim=-1)[0][:, :, :nsample]#将所有点到中心点的距离从小到大排序,取前nsample个
#有可能前nsample里有距离大于半径的,我们要去除掉,当半径内的点不够nsample时,我们对距离最小的点进行重复采样
#group_idx[:, :, 0]获得距离最小的点,他的shape是[B,S],所以view一下,再repeat
group_first = group_idx[:, :, 0].view(B, S, 1).repeat([1, 1, nsample])
#看哪些点是球体外的,得到一个mask,用mask进行赋值,把最近的点赋值给刚采样在球体外的点
mask = group_idx == N
group_idx[mask] = group_first[mask]
return group_idx
#采样与分组,xyz与points的区别,一个特征只有xyz,一个是其他特征
def sample_and_group(npoint, radius, nsample, xyz, points, returnfps=False):
"""
Input:
npoint:
radius:
nsample:
xyz: input points position data, [B, N, 3]
points: input points data, [B, N, D]
Return:
new_xyz: sampled points position data, [B, npoint, nsample, 3]
new_points: sampled points data, [B, npoint, nsample, 3+D]
"""
B, N, C = xyz.shape
#S个中心点
S = npoint
#从原点云通过FPS采样得到采样点的索引,
fps_idx = farthest_point_sample(xyz, npoint) # [B, npoint]
new_xyz = index_points(xyz, fps_idx) #[B,npoint,C]
idx = query_ball_point(radius, nsample, xyz, new_xyz) #每个中心点采样nsample个点的下标[B,npoint,nsample]
grouped_xyz = index_points(xyz, idx) # [B, npoint, nsample, C]
#每个点减去质心的坐标
grouped_xyz_norm = grouped_xyz - new_xyz.view(B, S, 1, C)
if points is not None:
grouped_points = index_points(points, idx)
new_points = torch.cat([grouped_xyz_norm, grouped_points], dim=-1) # [B, npoint, nsample, C+D]
else:
new_points = grouped_xyz_norm
if returnfps:
return new_xyz, new_points, grouped_xyz, fps_idx
else:
return new_xyz, new_points
#直接将所有点作为一个group
def sample_and_group_all(xyz, points):
"""
Input:
xyz: input points position data, [B, N, 3]
points: input points data, [B, N, D]
Return:
new_xyz: sampled points position data, [B, 1, 3]
new_points: sampled points data, [B, 1, N, 3+D]
"""
device = xyz.device
B, N, C = xyz.shape
new_xyz = torch.zeros(B, 1, C).to(device) #原点为采样点
grouped_xyz = xyz.view(B, 1, N, C)
if points is not None:
new_points = torch.cat([grouped_xyz, points.view(B, 1, N, -1)], dim=-1)
else:
new_points = grouped_xyz
return new_xyz, new_points
#该类实现普通的SetAbstraction,然后通过sample_and_group的操作形成局部的group,然后对局部group的每一个点进行MLP操作,最后进行最大池化,得到局部的全局特征
class PointNetSetAbstraction(nn.Module):
def __init__(self, npoint, radius, nsample, in_channel, mlp, group_all):
super(PointNetSetAbstraction, self).__init__()
self.npoint = npoint
self.radius = radius
self.nsample = nsample
#nn.ModuleList是一个存储器,自动将每个module的参数添加到网络之中,可以把任意nn.module的子类(nn.Conv2d,nn.Linear)加到里面
self.mlp_convs = nn.ModuleList()
self.mlp_bns = nn.ModuleList()
last_channel = in_channel
for out_channel in mlp:
self.mlp_convs.append(nn.Conv2d(last_channel, out_channel, 1))
self.mlp_bns.append(nn.BatchNorm2d(out_channel))
last_channel = out_channel
self.group_all = group_all
def forward(self, xyz, points):
"""
Input:
xyz: input points position data, [B, C, N]
points: input points data, [B, D, N]
Return:
new_xyz: sampled points position data, [B, C, S]
new_points_concat: sample points feature data, [B, D', S]
"""
xyz = xyz.permute(0, 2, 1)
if points is not None:
points = points.permute(0, 2, 1)
if self.group_all:
new_xyz, new_points = sample_and_group_all(xyz, points)
else:
new_xyz, new_points = sample_and_group(self.npoint, self.radius, self.nsample, xyz, points)
# new_xyz: sampled points position data, [B, npoint, C]
# new_points: sampled points data, [B, npoint, nsample, C+D]
new_points = new_points.permute(0, 3, 2, 1) # [B, C+D, nsample,npoint]
#下面是pointnet操作,对局部进行MLP操作,利用1*12d卷积相当于把C+D当作特征通道
#对[nsample,npoint]的维度上进行逐像素卷积
for i, conv in enumerate(self.mlp_convs):
bn = self.mlp_bns[i]
new_points = F.relu(bn(conv(new_points)))
#对每一个group做maxpooling得到局部的全局特征,[B,3+D,npoint]
new_points = torch.max(new_points, 2)[0]
new_xyz = new_xyz.permute(0, 2, 1)
return new_xyz, new_points
#MSG方法的set abstraction,radius_list是一个列表
class PointNetSetAbstractionMsg(nn.Module):
#例如128,[0.2,0.4,0.8],[32,64,128],320,[[64,64,128],[128,128,256],[128,128,256]]
def __init__(self, npoint, radius_list, nsample_list, in_channel, mlp_list):
super(PointNetSetAbstractionMsg, self).__init__()
self.npoint = npoint
self.radius_list = radius_list
self.nsample_list = nsample_list
self.conv_blocks = nn.ModuleList()
self.bn_blocks = nn.ModuleList()
for i in range(len(mlp_list)):
convs = nn.ModuleList()
bns = nn.ModuleList()
last_channel = in_channel + 3
for out_channel in mlp_list[i]:
convs.append(nn.Conv2d(last_channel, out_channel, 1))
bns.append(nn.BatchNorm2d(out_channel))
last_channel = out_channel
self.conv_blocks.append(convs)
self.bn_blocks.append(bns)
def forward(self, xyz, points):
"""
Input:
xyz: input points position data, [B, C, N]
points: input points data, [B, D, N]
Return:
new_xyz: sampled points position data, [B, C, S]
new_points_concat: sample points feature data, [B, D', S]
"""
xyz = xyz.permute(0, 2, 1)
if points is not None:
points = points.permute(0, 2, 1)
B, N, C = xyz.shape
S = self.npoint
#找到S个中心点
new_xyz = index_points(xyz, farthest_point_sample(xyz, S))
#对不同的半径做ball query,将不同半径下的点云特征保存在new_points_list中,最后再拼接到一起
new_points_list = []
for i, radius in enumerate(self.radius_list):
K = self.nsample_list[i]
#按照球形分组
group_idx = query_ball_point(radius, K, xyz, new_xyz)
grouped_xyz = index_points(xyz, group_idx)
#进行归一化处理
grouped_xyz -= new_xyz.view(B, S, 1, C)
if points is not None:
grouped_points = index_points(points, group_idx)
grouped_points = torch.cat([grouped_points, grouped_xyz], dim=-1)
else:
grouped_points = grouped_xyz
#进行维度交换,准备卷积,D维特征,每组K个点
grouped_points = grouped_points.permute(0, 3, 2, 1) # [B, D, K, S]
for j in range(len(self.conv_blocks[i])):
conv = self.conv_blocks[i][j]
bn = self.bn_blocks[i][j]
grouped_points = F.relu(bn(conv(grouped_points)))
#卷积完在组内的点进行最大池化
new_points = torch.max(grouped_points, 2)[0] # [B, D', S]
new_points_list.append(new_points)
new_xyz = new_xyz.permute(0, 2, 1)
new_points_concat = torch.cat(new_points_list, dim=1)#在特征维度进行合并
return new_xyz, new_points_concat
#特征上采样模块,当点的个数只有一个时,采用repeat直接复制成N个点,当点数大于1个时,采用线性插值的方法进行上采样,拼接上下采样对应点的SA的特征,再对拼接后的每个点做一次MLP
class PointNetFeaturePropagation(nn.Module):
def __init__(self, in_channel, mlp):
super(PointNetFeaturePropagation, self).__init__()
self.mlp_convs = nn.ModuleList()
self.mlp_bns = nn.ModuleList()
last_channel = in_channel
for out_channel in mlp:
self.mlp_convs.append(nn.Conv1d(last_channel, out_channel, 1))
self.mlp_bns.append(nn.BatchNorm1d(out_channel))
last_channel = out_channel
def forward(self, xyz1, xyz2, points1, points2):
"""
Input:
xyz1: input points position data, [B, C, N]
xyz2: sampled input points position data, [B, C, S]
points1: input points data, [B, D, N]
points2: input points data, [B, D, S]
Return:
new_points: upsampled points data, [B, D', N]
"""
xyz1 = xyz1.permute(0, 2, 1) #[B,N,C]
xyz2 = xyz2.permute(0, 2, 1) #[B,S,C]
points2 = points2.permute(0, 2, 1) #[B,S,D]
B, N, C = xyz1.shape
_, S, _ = xyz2.shape
#如果该层只有一个点,那么上采样直接复制成N个点即可
if S == 1:
interpolated_points = points2.repeat(1, N, 1)
else:
dists = square_distance(xyz1, xyz2) #计算上一层与该层点之间的距离[B,N,S]
dists, idx = dists.sort(dim=-1)#默认升序排列,取距离N个点最小的三个S里面的点
dists, idx = dists[:, :, :3], idx[:, :, :3] # [B, N, 3]
dist_recip = 1.0 / (dists + 1e-8)#求距离的倒数,距离越远,权重越小
norm = torch.sum(dist_recip, dim=2, keepdim=True) #对离的最近的三个点权重相加
weight = dist_recip / norm #weight是指计算权重,他们三个权重和为1
#index_points之后维度是[B,N,3,C],在第二维度求和,等于三个点特征加权之后的和。[B,N,C]
interpolated_points = torch.sum(index_points(points2, idx) * weight.view(B, N, 3, 1), dim=2)
if points1 is not None:
points1 = points1.permute(0, 2, 1)
new_points = torch.cat([points1, interpolated_points], dim=-1)
else:
new_points = interpolated_points
new_points = new_points.permute(0, 2, 1)
for i, conv in enumerate(self.mlp_convs):
bn = self.mlp_bns[i]
new_points = F.relu(bn(conv(new_points)))
return new_points
版权归原作者 CVplayer111 所有, 如有侵权,请联系我们删除。