
ARMA中文全称为自回归移动平均模型,广泛用于时间时间序列分析中。本文以statsmodels 模块中自带数据集co2为例,实战研究ARMA模型。
一、探索性数据分析。
首先导入必要的package与数据集
from statsmodels.datasets import co2
data=co2.load(as_pandas=True).data
print(data)
得到的data为DataFrame 格式的格式,数据结构为2284行,1列。
对数据进行可视化,这里用pandas 的画图方法,能较好地显示横坐标,个人感觉比plt.plot()好用。
data.plot()
plt.show()
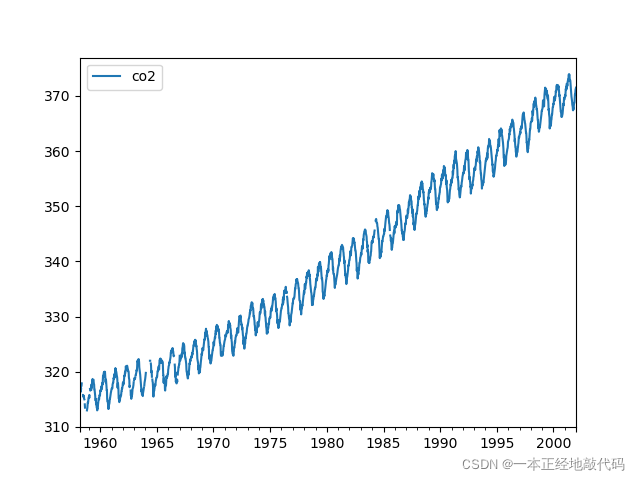
这里看到两个信息:1、数据并不是以天为单位,所以画出的图中存在间断点,2、数据本身存在周期与趋势。
解决办法是先做一个数据上采样,将数据转变为月度平均,然后做一个12阶滞后的差分,消除趋势与周期
data=data.resample('M').mean().ffill()#均值上采样,用强项填充填充缺失值
data_diff=data.diff(12).dropna()#12阶差分,删掉缺失值print(data_diff.head(10))
输出前10 条数据,1958年3月份-1959年2月份的12条数据由于缺失被删除了,所以差分后的数据从1959年3月份开始。
画图检验12阶差分后数据的平稳性,平不平稳不敢说,至少比原始数据要好。
data_diff.plot()
plt.show()

所以我们用更为严格的方法来说明问题,这里用单位根检验(ADF)把原始数据和差分后数据均检验了一遍。原始数据P值为0.99,大于0.05,拒绝数据平稳的假设;差分后数据通过平稳性检验。
from statsmodels.tsa.stattools import adfuller#导入tsa.stattools中的ADFprint("12阶差分数据单位根检验的P值",adfuller(data_diff)[1])print("原始数据单位根检验的P值 ",adfuller(data)[1])#12阶差分数据单位根检验的P值 0.000778539367442881#原始数据单位跟检验的P值 0.9989453312516823
凡事都有一个度,若是差分后数据“过于平稳”,便相当于白噪声了,我们无法从中提取任何有用信息,所以接下来进行白噪声检验,各阶滞后项P值均小于0.05,拒绝为白噪声的原假设。
from statsmodels.stats.diagnostic import acorr_ljungbox
print('数据白噪声检验的结果',acorr_ljungbox(data_diff,lags=[6,12,24],return_df=True))

二、定阶拟合模型
对数据定阶有很多方法,
1、ACF、PACF图像定阶
from statsmodels.graphics.tsaplots import plot_acf,plot_pacf#导入package
fig,axes=plt.subplots(2,1)#画2行1列的组合图
fig.subplots_adjust(hspace=0.5)#调整两图之间间隔,单纯为了美观
plot_acf(data_diff,ax=axes[0])#画ACF图
plot_pacf(data_diff,ax=axes[1])#画PACF图
plt.show()
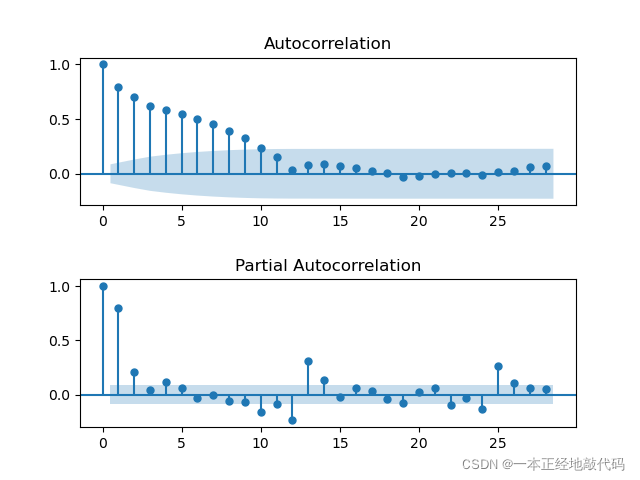
ACF超过阈值的阶数作为MA的参数,PACF超过阈值threshold的阶数作为AR的参数。根据上图可将参数选为(3,11)
2、statsmodels自带的方法定阶
这种方法比看图说话更为严谨,但缺点是计算量大,有时甚至跑不出结果(反正阶数过高我的电脑没跑出来#捂脸#)
from statsmodels.tsa.stattools import arma_order_select_ic
res=arma_order_select_ic(data_diff,max_ar=15,max_ma=15)print(res[1])#res返回两个结果,第一个为bic值的矩阵数组,第二个为阶数
三、拟合模型
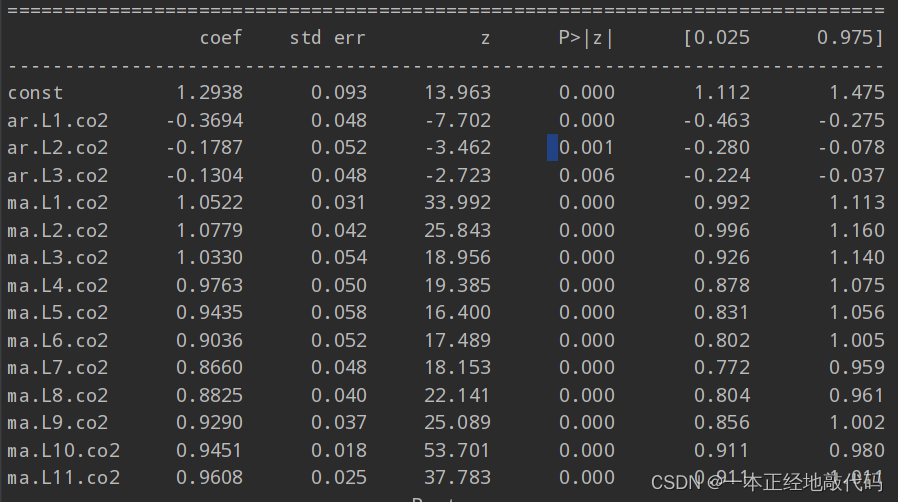
接下来用定好的阶数拟合模型,注意拟合的模型一定要加fit()方法,不然无法输出结果,这一点跟机器学习sklearn中模式是一样的。输出结果中P值均小于0.05,拒绝系数为0的原假设。
from statsmodels.tsa.arima_model import ARMA#导入ARMA类
model=ARMA(data_diff,order=(3,11)).fit(disp=-1)print(model.summary())
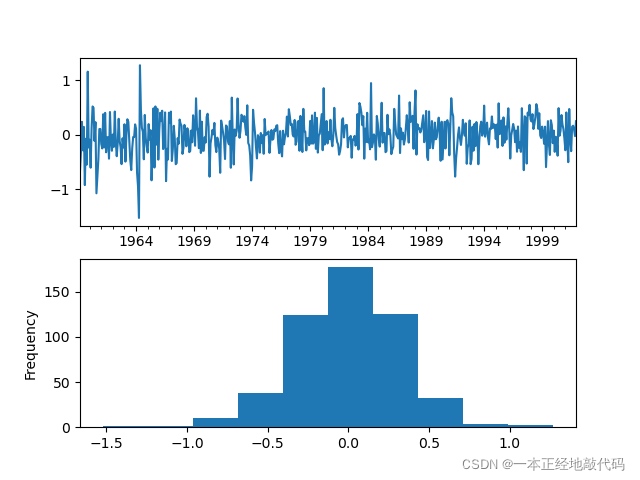
接下来评判模型是否“学习”到位?输出模型残差值,残差为白噪声,说明模型拟合得较好。
reside=model.resid#模型残差值
fig,axes=plt.subplots(2,1)
reside.plot(ax=axes[0])
reside.plot(kind='hist',ax=axes[1])
plt.show()print(acorr_ljungbox(reside,lags=[6,12,24],return_df=True))#残差白噪声检验
四、根据模型进行短期预测
ARMA在短期预测效果较长期好,接下来进行推后12期预测,这里一同将之前的数据预测出来了(没搞懂+11为什么会预测出来12期)
preds=model.predict(0,len(data_diff)+11)#预测后12期
preds=pd.DataFrame(preds,columns=['predict'])#转化为DataFrame用于合并print(preds)
final_data=pd.merge(data,data_diff,how='outer',left_index=True,right_index=True)#将采样后数据预差分数据合并,注意how='outer'
final_data=pd.merge(final_data,preds,how='outer',left_index=True,right_index=True)#将预测值和上行形成的数据合并,how='outer'print(final_data)
final_data.to_csv('D:/yuce.csv')
将数据保存在本地,数据长下面这样,最下面predict多出12个值,这里没有展示。
将数据都保存在本地有诸多好处,每次修改无需再跑一遍模型,直接从本地读取数据进行分析即可。
直接读取本地整理好的数据,第二行代码是把预测的差分值加在原始数据上,得到预测数值。+10是为了作图的时候好区分,没有其他含义。
df=pd.read_excel('D:/co2预测.xlsx',index_col=0)
df['predict_value']=df['co2_x'].shift(12)+df['predict']+10
接下来进行可视化,在第一个子图中画出整体值的预测效果,红色线为预测值,绿色线为实际值
fig,axes=plt.subplots(2,1)#生成2行1列组合图
fig.subplots_adjust(hspace=0.5)#调整两图之间间隔
df['co2_x'].plot(color='g',ax=axes[0])
df['predict_value'].plot(color='r',ax=axes[0])
axes[1].set_title('value')
plt.legend()
在第二个子图中绘制差分值,同样红色代表预测值,绿色代表实际值。
df['co2_y'].plot(color='g',ax=axes[1])#绘制真实差分值
df['predict'].plot(color='r',ax=axes[1])#绘制预测的差分值
axes[0].set_title('diff_value')
plt.legend()
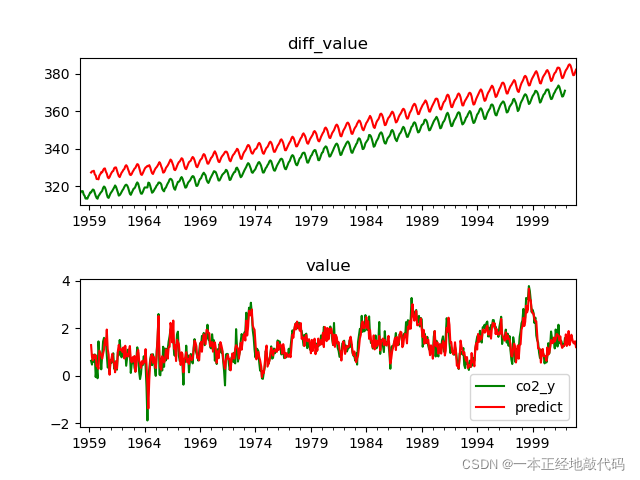
可以看出模型将大致的趋势与周期拟合出来了,但还有很多地方值得改进。
首先就是数据集本身噪声较少,具有明显的周期性与趋势性,所以拟合的模型相对表现良好,生活中大部分数据的信噪比没有这么高,会给模型拟合带来难度和挑战。
其次是差分阶数的选择与模型阶数的确定可以更加细致,更好的参数常常意味着更好的预测效果,能让数据价值得到最大化挖掘。
版权归原作者 一本正经地敲代码 所有, 如有侵权,请联系我们删除。