
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
大多数自动驾驶汽车使用 3D 激光扫描仪(即所谓的 LiDAR)来感知周围的 3D 世界。LiDAR 生成汽车周围场景的局部 3D 点云。这些 3D 点云广泛用于众多机器人和自动驾驶任务,如定位、物体检测、避障、映射、场景解释和轨迹预测。一个典型的 LiDAR 传感器每秒生成大约 10 个这样的点云。
预测传感器在未来可能会看到什么的能力可以增强自动驾驶汽车的决策。这个方向中一个有前途的应用是将预测的点云用于路径规划任务,例如避免碰撞。与预测(例如预测交通agent的未来3D包围盒)的方法不同,点云预测不需要任何前置推理步骤(例如定位、检测或跟踪)就可以预测未来场景。在预测的点云上运行现成的检测和跟踪系统会产生未来的 3D 对象边界框,正如去年不同研究人员在点云预测中所展示的那样(Weng et al. at CoRL’20; Lu et al. )
从机器学习的角度来看,点云预测是一个有趣的问题,因为下一次传入的 LiDAR 扫描总是提供地面实况数据。此属性提供了以自监督的方式训练点云预测的潜力,不需要进行昂贵的标记,并且还可以在线评估其性能,仅在未知环境中具有很小的时间延迟。

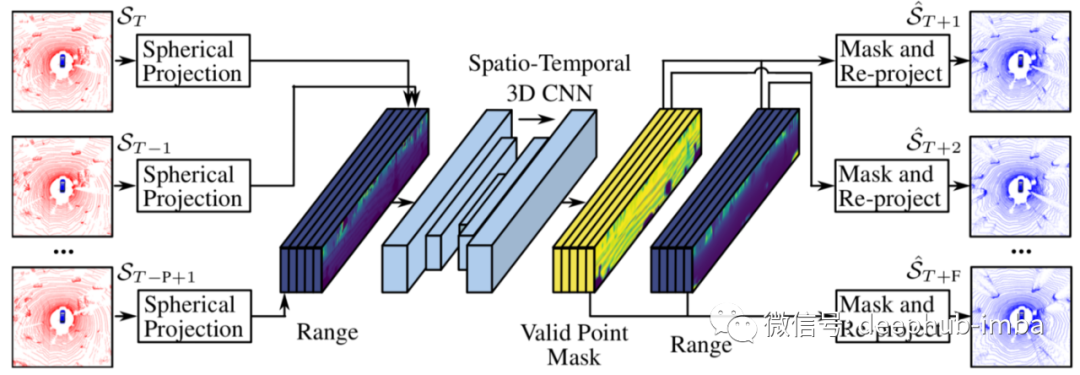
最近由 Benedikt Mersch 在 CoRL 2021 上展示工作中(有源代码),解决了从给定的过去扫描序列预测大型无序未来点云的问题。高维和稀疏的 3D 点云数据使点云预测成为一个尚未完全探索的具有挑战性的问题。可以通过将预测的未来场景流应用到最后接收到的扫描或生成一组新的未来点来估计未来点云。与现有的利用递归神经网络对应时间建模的方法不同,Mersch等人使用三维卷积联合空间和时间编码信息生成新的点云来预测未来的场景。他们提出的方法采用一种新的基于连接距离图像的三维表示作为输入。这种方法联合估计未来范围内图像和每个点的分数,以确定多个未来时间步长的有效或无效点。并通过使用跳过连接和圆形填充的来获取环境的结构细节,并提供比其他最先进的点云预测方法更准确的预测。
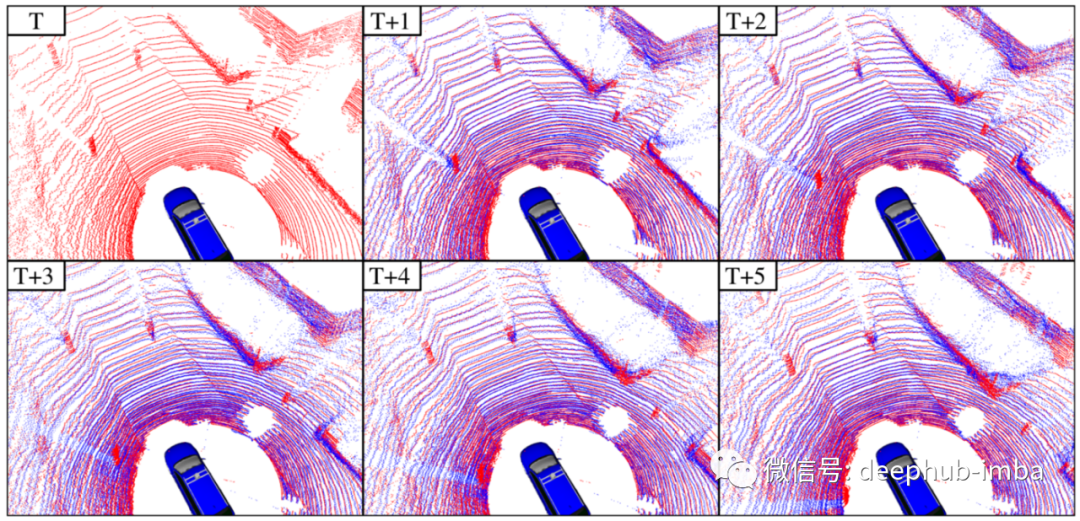
当前的点云(右上角)和预测未来5个点云。对应时间步长的真值点用红色表示,预测点用蓝色表示。
这种方法允许用较少的参数预测未来不同大小的详细点云从而优化训练和推断时间。此外,该方法也是完全自监督的不需要任何人工标记的数据。总之,该方法可以从给定的输入序列中通过时序三维卷积网络快速联合时空点云处理来预测详细的未来三维点云序列,优于目前最先进的点云预测方法,并且可很好地推广到不可见环境,在线运行速度也比典型的旋转3D激光雷达传感器帧率更快。
论文名称:
B. Mersch, X. Chen, J. Behley, and C. Stachniss, “Self-supervised Point Cloud Prediction Using 3D Spatio-temporal Convolutional Networks,” in Proc. of the Conf. on Robot Learning (CoRL), 2021.
https://www.ipb.uni-bonn.de/wp-content/papercite-data/pdf/mersch2021corl.pdf
https://github.com/PRBonn/point-cloud-prediction
喜欢就关注一下吧:
点个 在看 你最好看!********** **********