
1. 概述
Dario Pavllo等人于2019年提出了VideoPose3D模型,旨在把输入视频转换成人体各关键点相对于根关节的相对三维位置。为了实现这一目的,作者采取的是两步走的策略。首先要利用现成的2D姿态检测算法提取出视频各帧里人体各关键点的2D坐标,然后用自己的模型对它进行进一步处理,最终输出各关键点的相对3D坐标。在所有数据都有标签的情况下,只需要用作者提到的时域膨胀卷积模型(Temporal dilated convolutional model)即可。然而,作者考虑到了,在实际情况下,带标签的真实3D姿态的数据量往往是有限的,因而他们提出了一种无监督训练的方法,需要把它与有监督训练相结合,构成了一种所谓的半监督训练方法。接下来让我们具体地看一下这两种训练过程及它们是如何结合在一起的。
2. 时域膨胀卷积模型
首先利用现成的2D姿态检测算法提取出视频各帧里人体各关键点的坐标,然后把它们拼接在一起,构成一个三维数组,作为该模型的输入。具体来说,这个数组的通道数(第3维的长度)等于关节数
,代表了各个关节点的横纵坐标;第一维为设定好的帧的感受野的大小,在给定一个完整视频的情况下,我们可以综合考虑到过去以及未来的信息,所以待预测帧应当位于当前维度的中央;如果是实时的姿态估计,那么我们将只能使用过去的信息(这时的卷积操作被称为因果卷积(causal convolution) ),此时待预测帧可以位于当前维度的一端。如果是单帧预测,那么这个数组的第二维的长度为1,至于多帧预测的情况(设帧数为
,
),原文中没有提及到如何处理,个人猜测可以直接将单帧预测时的数组拼接在一起,此时第二维的长度为n。为了简单起见,我们这里只介绍单帧预测,多帧的情况可依此类推。
设,时域感受野为243帧,卷积核的长度
,因而此时模型的输入数组的形状为
,首先依次把它通过一个共有1024个
卷积核的卷积层,批归一化层,ReLU激活函数,dropout层,得到的中间输出的形状为
,这种卷积实际上是一维的时域卷积,可以参考一下TCN的结构。再把它依次通过 B 个残差块,最后再通过一个卷积层得到
的输出向量。残差块的组成如下图所示,值得注意的是,第
个残差块中的前一个卷积是膨胀系数为
的膨胀卷积(
),这样做的好处是神经元的感受野能随着层数的增加而呈指数增长,使得高层神经元能综合考虑到所有输入帧的信息,从而得到更全面准确的判断。此外,在进行残差连接时,由于残差块的输入输出维度不一致,所以在把输入加到输出上之前,要先对输入进行裁剪。

提出的全卷积3D姿态估计模型的结构
3. 半监督训练方法
对于带标注的真实3D姿态样例,我们可以先使用上述模型估计出各关节点的3D坐标,然后通过计算平均每关节位置误差(mean per-joint position error, MPJPE),直接对其进行有监督的训练。然而,正如前面所言,在实际情况下,带3D标签的视频样例数目往往有限,所以他们设计了一种方法来利用无标签的视频来对模型进行训练。大体思路是,先通过上面的时域卷积模型(又被称为编码器或姿态模型),从二维坐标中估计出三维坐标,然后再通过解码器把它投影成二维坐标,并检查它与原始输入之间的一致性,这种做法实际上是受到了无监督机器翻译中的循环一致性(cycle consistency)的启发。
3.1 轨迹模型与骨长L2损失
作者提到,人体在屏幕空间上的投影不仅取决于姿态模型输出的各关节相对于根关节的坐标,而且还会受到人体的根关节在相机坐标系下的全局坐标(又被称为轨迹)的影响。设想如果没有这个全局坐标的话,人体将始终以一个固定的大小被投影到屏幕的中心。所以,作者又提出了一个所谓的轨迹模型,来对人体的轨迹做出预测,最后结合轨迹与姿态,才能得到人体在屏幕空间上的正确投影。轨迹模型与姿态模型虽然在结构上很相似,但是它们不会共享任何参数,因为作者观察到当以多任务方式训练它们时,两者之间会产生负面影响。在对轨迹模型训练时,用的是带标签的真实3D姿态数据,损失函数是作者提出的加权平均每关节位置误差(WMPJPE):
其中 是关节点在相机空间中的深度。所表示的含义是给和相机相距较远的关键点赋予较低的权重,这是因为当人体与相机离得比较远的时候,同样的绝对偏差,在投影到屏幕上后,实际观察到的偏差会比较小,而且人体与相机相隔越远,估计出精确轨迹的难度也就越大,因而所赋予的权重应随距离的增大而逐渐减小。

以半监督方式训练的3D姿态估计模型
3.2 相关讨论
作者提出的方法还考虑到了光学成像过程对结果的影响,为此还需要用到相机的内在参数,比如焦距、主点等,以及一些非线性透镜畸变参数。虽然在实际实验中,作者发现在Human3.6M中使用的相机的光学变形现象对姿态估计的影响几乎可以忽略不计,但是作者还是把它们添加到模型中,因为它们确实能让对真实相机成像过程的建模更加准确。
4. 实验与评估
作者总共使用了三种方式对模型进行评估,此处我们只介绍其中的两种。评估方法1是使用以毫米为单位的平均每关节位置误差(MPJPE),即预测关节点与真值之间的欧氏距离。评估方法2是先通过平移、旋转、缩放来使预测与真值对齐后,再计算平均每关节位置误差,这被称为P-MPJPE。
下表显示了使用评估方法1时,作者的有4个残差块和243帧的感受野的卷积模型以及其它6个其它模型在Human3.6M数据集上的运行结果。可以看出,该模型具有比所有其他模型都更低的平均误差,并且不像其他许多模型(+)那样依赖于额外数据。在评估方法1作者所提出的模型的平均表现比以前的最佳结果好6毫米,对应于11%的误差减少。在评估方法2下,虽然优势略有减小,但仍然具有最小的平均误差。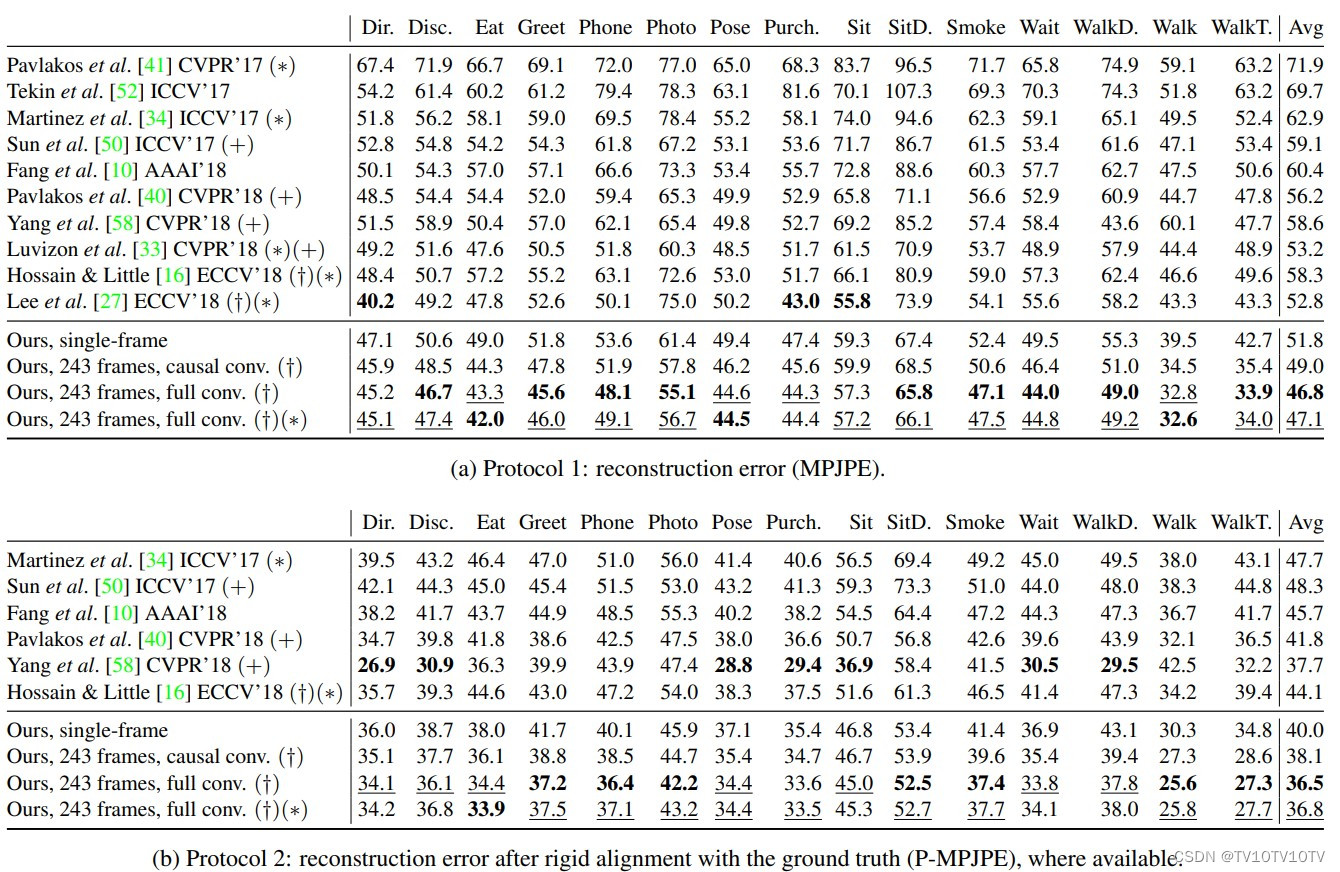
在Human3.6M数据集上的误差对比,†、∗、+三个符号分别代表使用了时域信息,真实的边界框和额外数据
从单帧和243帧感受野的模型的结果对比中可以看出,243帧感受野的模型的确利用了一段时间内的信息,因此其误差比前者平均低了5mm。此外,作者的模型在行走等高动态的环境下的优势会更为突出。
附:论文链接:3D human pose estimation in video with temporal convolutions and semi-supervised training
知乎链接(同一作者):VideoPose3D:基于视频的3D人体关键点检测 - 知乎 (zhihu.com)
版权归原作者 TV10TV10TV 所有, 如有侵权,请联系我们删除。