
【论文极速读】Prompt Tuning——一种高效的LLM模型下游任务适配方式
FesianXu 20230928 at Baidu Search Team
前言
Prompt Tuning是一种PEFT方法(Parameter-Efficient FineTune),旨在以高效的方式对LLM模型进行下游任务适配,本文简要介绍Prompt Tuning方法,希望对读者有所帮助。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
∇
\nabla
∇ 联系方式:
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用(https://www.zhihu.com/column/c_1265262560611299328)
微信公众号:机器学习杂货铺3号店
众所周知,当前LLM是人工智能界的香饽饽,众多厂商和研究者都希望能够在LLM上进行应用推广和研究,这就难免需要对LLM进行下游任务的适配,最理想的情况当然是可以用私有数据,进行全网络端到端的微调。但是LLM现在参数量巨大,大部分都大于6B,有些甚至达到了100B以上,即便是端到端微调都需要大量的硬件资源。 PEFT(Parameter-Efficient FineTune)旨在最高效地引入参数,探索合适的训练方式,使得LLM适配下游任务的代价最小化,而本文提到的Prompt Tuning [1] 就是这样一个工作。
在介绍这个工作之前,我们得知道什么是prompt,关于prompt的内容之前在博文[2]中曾经介绍过,简单来说,就是用某种固定的模板或者范式,尝试去让LLM去适配下游任务,从在prompt中是否提供例子的角度上看,又可以分为one-shot prompt, few-shot prompt, zero-shot prompt等。但是,在文章[3]中提到过,不同的prompt模板对性能的影响巨大,如Fig 1.所示,我们也把这种prompt称之为硬提示词(hard-prompt)。既然有『硬』的,那么就肯定有『软』的prompt,soft-prompt指的是模型可以通过学习的方式去学习出prompt模板,经典工作包括P-Tuning [3], prefix prompt [4], soft prompt [5],以及本文将会介绍到的prompt tuning [1]。
Fig 1. 不同的prompt模板对性能影响巨大
如Fig 2.所示,在prompt tuning中,在原有hard prompt模板之前拼接了若干个可学习的token,我们用
P
∈
R
p
×
d
\mathbf{P} \in \mathbb{R}^{p \times d}
P∈Rp×d表示soft prompt部分,其中
p
p
p为拼接的token数量,用
X
∈
R
n
×
d
\mathbf{X} \in \mathbb{R}^{n \times d}
X∈Rn×d 表示hard prompt部分。那么,完整的prompt可表示为
[
P
;
X
]
∈
R
(
p
+
n
)
×
d
[\mathbf{P};\mathbf{X}] \in \mathbb{R}^{(p+n) \times d}
[P;X]∈R(p+n)×d,模型的目标既变为了
P
(
Y
∣
[
P
;
X
]
)
P(\mathbf{Y}|[\mathbf{P};\mathbf{X}])
P(Y∣[P;X])。此时,LLM的参数和embedding层的参数都是设置为**不可学习的** (❄),整个网络只有soft prompt层是可学习的(🔥),这意味着微调模型需要的内存和计算代价都大大减小了 。

Fig 2. prompt tuning在原有hard-prompt模板之前,拼接了若干个可学习的token,并将其视为soft-prompt。
只需要设置不同的soft prompt就可以适配不同的下游任务了,如Fig 3. 所示,在模型参数量足够大(
≥
10
B
\ge 10B
≥10B)的时候,采用prompt tuning的效果足以比肩全参数微调,而且所需参数量只有后者的万分之一,是名副其实的参数高效(Parameter-Efficient)方法。而不管在什么尺度的模型下,prompt tuning的结果都要远远优于hard prompt design的结果,人工设计的prompt模板确实很难与模型自己学习出来的竞争。

Fig 3. (a)在10B以上的模型中,采用prompt tuning的结果可以和全模型端到端微调的结果持平,(b)而prompt tuning增加的参数量只有全模型端到端微调的万分之一。
此外,作者在论文中还进行了更多实验去验证prompt tuning的有效性和其他特性。第一个就是soft prompt所需要的长度,如Fig 4. (a)所示,在10B模型下,20-100个soft token是一个比较合适的数量,20个token能提供最大的性价比。如何初始化这些新增的soft token embedding也是一个指的思考的问题,作者尝试了随机均匀初始化,从词表的embedding中采样,以及对于分类任务而言,用label的类别embedding进行初始化,如Fig 4. (b) 所示,随机初始化在模型参数量不够的时候(< 10B)表现,不如从词表采样和label初始化的方法,但当模型参数量足够大时,随机初始化的效果能够达到最好,优于从词表中采样的方法。考虑到本文采用的LLM是T5,而T5是一个encoder-decoder的结构,在设计预训练任务的时候采用的是
span corruption + 哨兵token
的形式,如:
Origin: Thank you for inviting me to your party last week
Corrupted: Thank you for [X] me to your party [Y] week
Target: [X] inviting [Y] last [Z]
这样设计预训练任务能实现encoder-decoder架构的T5高效预训练,但是这意味着模型没有见过自然语言的输入(因为输入总是有哨兵token,比如[X]/[Y]等),为了实现T5到LM的适配,在本文中作者尝试对T5进行了
LM Adaptation
的后训练:继续T5的少量预训练,给定自然文本作为输入,尝试预测自然语言的输出,而不是带有哨兵token的文本。 此外,作者还尝试了所谓的
Span Corruption + 哨兵
的方法,指的是在原T5模型基础上,在应用到下游任务预测时候,都给拼接上哨兵token,以减少下游任务和预训练任务的gap。如Fig 4. (C)所示,无论采用多大尺度的模型,采用了LM Adaptation能带来持续的增益,而Span Corruption或者Span Corruption+Sentinel的方法,则只在10B模型的尺度上能有比较好的效果(然而仍然无法超越前者)。那么LM Adaptation需要进行多少step的训练合适呢?在Fig 4. (d)中,作者进行了若干尝试,结果表明越多step将会带来越多的收益,最终作者选定在100k step。
Fig 4. 对prompt tuning不同设置的探索实验。
采用prompt tuning还有一个好处就是可以让多个下游任务复用同一个LLM模型。在模型微调中,对于每个下游任务都需要维护一套独立的模型,如Fig 5. 左图所示,而在prompt tuning中,则只需要维护一套静态的LLM模型,不同任务通过不同的soft prompt进行区分即可激发LLM的不同下游任务能力,如Fig 5. 右图所示,因为可以节省很多资源,这对于部署来说很友好。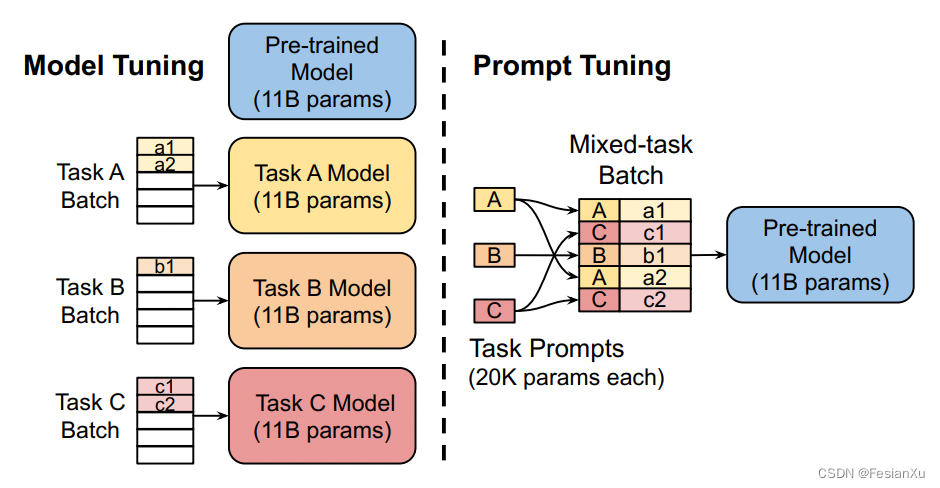
Fig 5. 采用prompt tuning的方式,可以很方便的用同一个模型覆盖多个下游任务,实现资源节省。
Reference
[1]. Lester, Brian, Rami Al-Rfou, and Noah Constant. “The power of scale for parameter-efficient prompt tuning.” arXiv preprint arXiv:2104.08691 (2021). aka Prompt Tuning.
[2]. https://blog.csdn.net/LoseInVain/article/details/130500648, 《增强型语言模型——走向通用智能的道路?!?》
[3]. Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. 2021. Gpt understands, too. arXiv:2103.10385. aka p-tuning
[4]. Li, Xiang Lisa, and Percy Liang. “Prefix-tuning: Optimizing continuous prompts for generation.” arXiv preprint arXiv:2101.00190 (2021). aka prefix tuning
[5]. Qin, Guanghui, and Jason Eisner. “Learning how to ask: Querying LMs with mixtures of soft prompts.” arXiv preprint arXiv:2104.06599 (2021). aka soft prompt
[6].
版权归原作者 FesianXu 所有, 如有侵权,请联系我们删除。