
1.Mask RCNN网络结构
Mask R-CNN是对Faster R-CNN的直观扩展,网络的主干有RPN转换为主干网络为ResNet的**特征金字塔网络(FPN),同时**添加了一个分支用于预测每个感兴趣区域(RoI)上的分割掩模,与现有的用于分类和边界盒回归的分支并行(图1)。**掩模分支是一个应用于每个RoI的小FCN,以像素-顶像素的方式预测分割掩模。但是,Faster RCNN并不是为网络输入和输出之间的像素对像素对齐而设计的。这一点最明显的是RoIPool[18,12],事实上的处理实例的核心操作,如何执行特征提取的粗空间量化。为了解决这种错位,网络使用了一个简单的、无量化的层,称为RoI Align,它忠实地保留了精确的空间位置。**
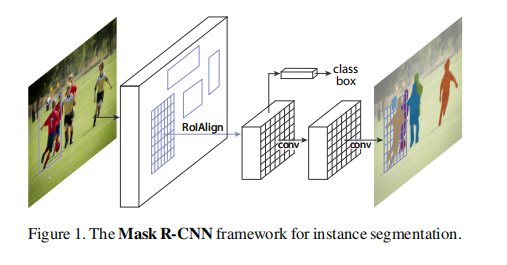
1.backbone
Backbone采用的是主干网络为ResNet-50或者ResNet-101的RPN,作为特征提取器提取特征, 特征金字塔(Feature Pyramid Networks, FPN)的基本思想是通过构造一系列不同尺度的图像或特征图进行模型训练和测试,目的是提升检测算法对于不同尺寸检测目标的鲁棒性。FPN构造特征包括自下而上(bottom-up)、自上而下(top-down)以及同层连接3个过程,自下而上的过程实质上是卷积网络前向传播的过程。 自上而下的过程实质上是通过把上层的特征图进行尺度变换,来构造新的特征图,新的特征图需要和下层的特征图保持一致的尺度,从而保证特征图可以融合在一起。在长、宽方向上,采用向上采样(upsample)的方法,和下层特征图的宽、高拉成一样大小;在深度方向上,通过一个1×1的卷积,把上层特征图的深度压缩到和下层特征图的深度相同。 经过自上而下的过程,基于上层特征图构建的新特征图和原始的下层特征图具有了同样的尺度。如图2所示,先把新的特征图和原始的下层特征图中每个对应元素相加(element-wise add),就实现了上层特征和下层特征的融合,再把融合后的每层特征图都输出为一个深度为d(比如d=256)的新特征图。这样就把深层特征融合到浅层特征中,就兼顾了细节和整体,融合后的特征会具有更为丰富的表达能力。 2.RPN(Region Proposal Network)
与faster rcnn一样,网络使用区域建议网络(RPN)获得建议框,RPN对先验框进行回归,同时预测先验框中是否存在物体获得建议框,再将建议框馈送至分类和回归模块,获取物体的预测框与分类。
3.ROI Align
现在我们得到了图一所示的proposals后,我们需要清楚一个问题,那就是框的大小是不一样的,而不同大小的框代表了特征图上不同大小的区域,而全连接层的使用意味着我们得将框所代表的特征图区域统一为一个尺寸。这也就是ROI Align的作用。
我们需要把所有的ROI都pooling成相同大小的feature map后,才能将它reshape 成一个一维的向量,从而完成后面的分类与回归任务。
与Faster rcnn中的ROI pooling不同,使用ROI pooling会造成较大的量化误差,这对于分割任务来说会造成较大的误差,因此maskrcnn中对ROI pooling进行了改进,提出了ROI Align。
假如现在有一个8×8的feature map,如下图所示,现在希望得到2x2的输出,有一个bbox坐标为[0,3,7,8]。
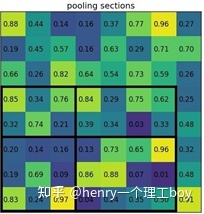
这个bbox的w=7,h=5,如果要等分成四块是做不到的,因此在ROI Pooling中会进行取整。就有了上图看到的h被分割为2,3,w被分割成3,4。这样之后在每一块中做max pooling,可以得到下图的结果。
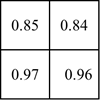
这样就可以将任意大小bbox转成2x2表示的feature。
但我们可以看见,ROI Pooling需要取整,这样的取整操作进行了两次,一次是得到bbox在feature map上的坐标时。
例如:原图上的bbox大小为665x665,经backbone后,spatial scale=1/32。因此bbox也相应应该缩小为665/32=20.78,但是这并不是一个真实的pixel所在的位置,因此这一步会取为20。0.78的差距反馈到原图就是0.78x32=25个像素的差距。如果是大目标这25的差距可能看不出来,但对于小目标而言差距就比较巨大了。
因此有人提出不需要进行取整操作,如果计算得到小数,也就是没有落到真实的pixel上,那么就用最近的pixel对这一点虚拟pixel进行双线性插值,得到这个“pixel”的值。
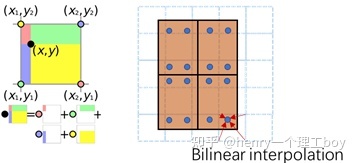
ROI Align操作步骤为:
1.将bbox区域按输出要求的size进行等分,很可能等分后各顶点落不到真实的像素点上
2.在每个块中再取固定的4个点,也就是图6右侧的蓝色点,针对每一个蓝点,距离它最近的4个真实像素点的值加权(双线性插值),求得这个蓝点的值
3.一个块内会算出4个新值,在这些新值中取max,作为这个块的输出值,最后就能得到2x2的输出。
根据maskrcnn论文所述,我们通过ROI Align可以把我们RPN生成并筛选后的框所对应的区域全部变成我们需要大小的特征图。而最后的任务就是对这些特征图来做进一步的分类、定位,分割了。
分类和定位和RPN里面的分类定位原理相同,这里主要说明一下分割。如图7所示,在得到ROI Align操作后的特征后,由于前面进行了多次卷积和池化,减小了对应的分辨率,mask分支开始利用反卷积进行分辨率的提升,同时减少通道的个数,maskrcnn使用到了FPN网络,通过输入单一尺度的图片,最后可以对应的特征金字塔,首先将ROI变化为14x14x256的feature,然后进行了5次相同的卷积操作,然后进行反卷积操作,最后输出28x28x80的mask,即输出了更大的mask。
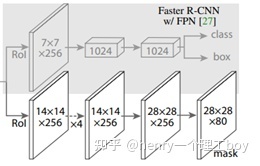
4.网络头部
** Faster R-CNN对每个候选对象有两个输出,一个类标签和一个边界框偏移量;Mask RCNN添加了第三个输出对象掩码的分支。**
每个采样RoI上的多任务损失定义为L=Lcls+Lbox+Lmask。分类损失Lcls和边界框损失Lbox与[12]中定义的相同。掩码分支为每个RoI有一个维度的输出,它编码K个分辨率为m×m的二进制掩码,每个K个类一个。为此,我们应用每像素s型,并将Lmask定义为平均二进制交叉熵损失。对于与地面真实类k相关联的RoI,Lmask只定义在第k个掩码上(其他掩码输出不会造成损失)。
对Lmask的定义允许网络为每个类生成掩码,而无需类之间的竞争;我们依赖于专用的分类分支来预测用于选择输出掩码的类标签。这可以解耦掩码和类预测。这与将FCNs[30]应用于语义分割时的常见做法不同,后者通常使用每像素的softmax和多项式交叉熵损失。在这种情况下,跨类的掩码相互竞争;在我们的例子中,对于每像素的s型和二进制损失,它们不会。实验结果表明,该公式是获得良好的实例分割结果的关键。
5.训练网络
就像在FastR-CNN中一样,如果一个 ROI有一个IoU至少为0.5的真实框,则被认为是正的,否则是负的。mask loss Lmask仅在正RoI上定义。掩码目标是RoI与其相关的地面真实掩模之间的交集。
训练采用以图像为中心的训练。图像的调整使其比例(较短的边缘)为800像素。每个批次每个GPU有2张图像,每张图像有N个采样roi,正[12]与负[12]的比例为1:3。C4主干N为64,FPN N为512。在8个gpu(有效小批量大小为16)上进行160k迭代训练,学习速率为0.02,在120k次迭代时学习率降低为原来的1/10。使用的权重衰减为0.0001,动量为0.9。使用ResNeXt[45],为每个GPU训练1张图像和相同次数的迭代,起始学习率为0.01。
版权归原作者 樱花的浪漫 所有, 如有侵权,请联系我们删除。