
核函数是我们处理数据时使用的一种方式。对于给的一些特征数据我们通过核函数的方式来对其进行处理。我们经常在SVM中提到核函数,就是因为通过核函数来将原本的数据进行各种方式的组合计算,从而从低维数据到高维数据。比如原来数据下样本点1是x向量,样本点2是y向量,我们把它变成e的x+y次方,就到高维中去了。
把数据映射到高维在我们直观上理解起来是很难的,其实也并不用深刻理解,因为做这些的目的只是为了让机器去理解,帮助机器通过自己的模型去更好的挖掘一些语义信息。所以对于我们人来说,“样本点1是x向量,样本点2是y向量”就完全足够了;只是为了照顾到机器和模型,我们需要帮它处理成高维,以便机器更好地使用。
核函数一般表示成 ,意思就是对向量xi和xj进行一些变换操作。
,意思就是对向量xi和xj进行一些变换操作。
梳理几种常见的核函数:
线性核函数

其实就是对两个向量做内积。其中有个转置操作,举个例子你就明白了:
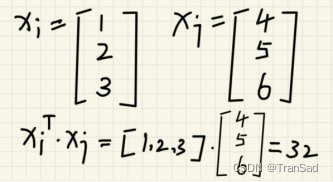
所以看起来线性核函数不对数据做任何变化,就拿过来乘起来就好了。虽然没有把数据怎么映射到高维,但在很多情况下“最简单的往往就是最好的”,就像奥卡姆剃刀原理所说:如无必要,勿增实体”,即“简单有效原理”。
线性核函数操作起来十分简单,计算也很方便,尤其是在样本数据量巨大的情况下,想用别的核函数也不好计算,直接用线性核就可以起到不错的效果了。
多项式核函数 (Polynomial kernel function)

乍一看,多项式核函数好像就是在线性核函数基础上增加了ζ,γ和Q这几个参数。这些参数是可以由我们自己指定的,比如我们把它写成二次的(Q=2),也就变成了常见的二次形式:

多项式核函数根据公式也很好理解,其中γ就是用来对内积进行缩放的,而ζ就是一个常数项,来进行加减上的调整,Q则是控制次数的。
我们另ζ为0,γ为1,Q为1,就会得到线性核函数即 。
。
说到底这种变换是在xi和xj的内积的基础上进行额外的变换。因为核函数的其中一个妙处就在于:我们发现“先求次项到高维再内积”等于“先低维空间内积再求次项”。既然有这么一个现象,肯定是先在低维做容易些。核函数也是这种计算思路的体现,减少了计算量。
高斯核函数
提到高斯我们知道有高斯分布(正态分布),后面在其他文章对于各种分布应该会有总结。
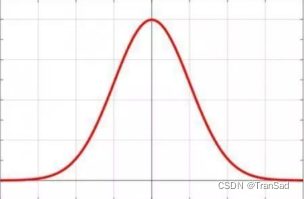
一维高斯分布公式是这样:
图像是这样:
二维的高斯函数则是这样:
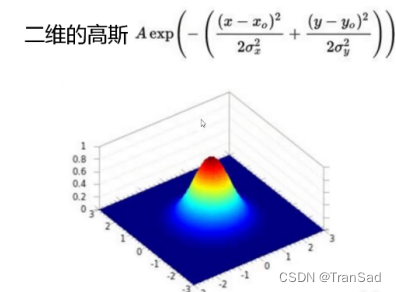
我们对高斯分布的图形样子有大概了解了,接下来引出高斯核函数:
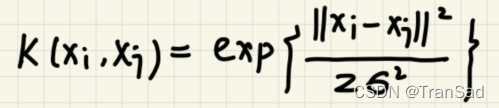
看起来和高斯分布的格式差不多,有一个差,有平方,有除以σ的平方等。
高斯核这样做的意义是什么呢?我们来分析这个公式:
1.首先抛开σ
我们对高斯核函数进行展开,首先我们忽略掉分母2σ的平方。
可以得到:
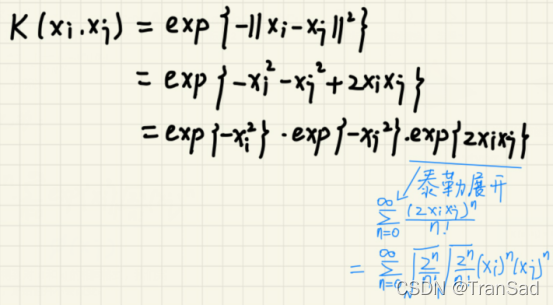
所以:

上面式子本来是只有一个累加符的,不过为了得到对xi和xj的相同格式,我们在后半段再添一个了累加符号,使其彻底分开,原始值并不会改变。
所以:
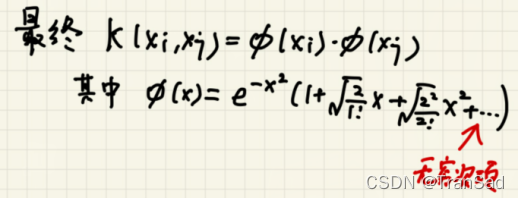
可以发现,我们通过高斯核函数这么一个看似简单的公式,却对于传入的xi和xj都可以扩展到无穷次的维度上,相比于线性核与高斯核,高斯核这个特征维度就对比出来了——纬度越高,模型越复杂,功能就会越强(如果不考虑过拟合的话~)。
2.单独分析σ
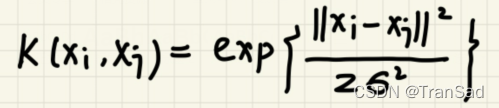
我们知道高斯核函数长上面这样,将它可视化出来,形状和前面的高斯分布也差不太多。
观察高斯核函数公式,发现里面有对样本向量求差的操作:xi-xj。假设xi和xj的距离不变,则xi-xj也不变吧?我们把这两个样本摆在底部平面上,向上投影,我们发现假如σ越小,曲面越陡,则投影出来的高度差也就越大;而假如σ越大,则曲面趋于平缓,则得到的K(xi,xj)也就越小。
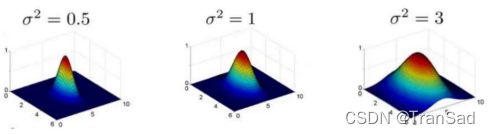
高斯核函数基本上是最常用的核函数了,对σ参数的调整也是非常常见的了,具体它是怎么影响最终结果的呢,我们举个例子从头到尾梳理一下高斯函数的应用场景:
现在我有N个样本点,每个样本点自己有一个特征向量,假设向量是5维的吧,比如第一个样本x1的特征为(2,3,1,2,4)。我们现在需要把这N个样本点进行分类,首先就通过高斯核函数来对这样的样本数据进行处理。
如何处理呢?我们拿出N个样本点中的第一个样本点x1,我们拿它与所有的样本点进行高斯核函数的计算,x1与每一个样本点都可以得到一个结果K(x1,xn),一共有N个样本点,我们可以得到N个计算结果。那么此时对于样本点x1的特征,就由原来5维的(2,3,1,2,4)变成了N维的****(K(x1,x1),K(x1,x2),K(x1,x3)……K(x1,xN))。同理,对于样本点x2和其他所有样本点都可以得到新的特征向量。不管原来每一个样本点的特征是多少维,经过这样的高斯核函数处理,每个样本都变成了“总样本数量”维****。
这样一来,我们就扩充了数据的维度和多样性了。而参数σ的作用如何体现呢?我们采用不同的σ大小对数据处理后,投入模型训练,最终得到的模型分类效果如下:
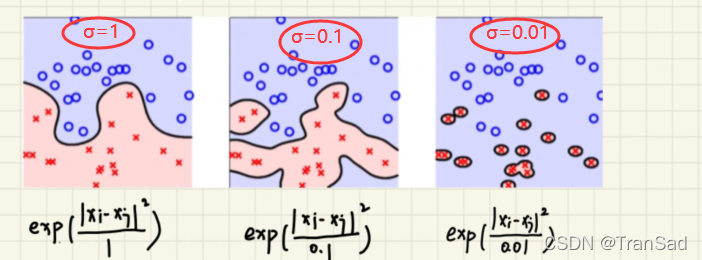
可以发现σ越小,对数据划分越细致,也越容易倒置过拟合。这是为什么呢?我自己的理解是这样的:我们σ越小,对于每一对样本点之间得出的高斯核函数值就越大,也就是把各个样本之间的距离算的越远了,那么模型就越偏向于把这些不同的样本点归位不同的类;如果σ很大,则算出来样本点之间的距离就很近,模型会偏向于把这些归位同一类。
这篇我主要是梳理了三种常见的核函数,尤其是对高斯核函数的原理、用法与参数调整等方面进行了描述。
版权归原作者 TranSad 所有, 如有侵权,请联系我们删除。