
协同过滤算法是一种推荐系统算法,它利用用户对物品的评价数据来预测用户对未评价物品的喜好程度。该算法基于一个简单的思想:**如果两个用户在过去对某些物品的评价很相似,那么在未来他们对这些物品的评价也很可能相似**。因此,协同过滤算法将用户之间的**相似度作为预测用户对物品的评价的依据,从而实现对用户兴趣的预测**。该算法分为基于用户的协同过滤和基于物品的协同过滤两种类型。
一、基于用户的协同过滤
基于用户的协同过滤算法是一种推荐系统算法,其基本思想是根据用户历史行为数据,找到和当前用户兴趣相似的其他用户,然后利用这些用户的行为数据来预测当前用户的兴趣,从而向其推荐物品。
具体来说,基于用户的协同过滤算法包括以下步骤:
- 确定目标用户,即需要为其推荐物品的用户。
- 找到和目标用户相似的其他用户,可以通过计算用户之间的相似度来实现。常用的相似度计算方法包括余弦相似度、皮尔逊相关系数等。
- 选取一定数量的相似用户作为邻居集合,可以根据相似度进行排名,选取前k个相似用户作为邻居。
- 预测目标用户对未评价过的物品的评分,可以通过加权平均或加权和等方法来计算。具体来说,可以将目标用户对邻居用户已评价过的物品的评分作为权重,进行加权平均或加权和运算。
- 为目标用户推荐未评价过的物品,可以根据预测的评分进行排序,选取前n个物品作为推荐结果。
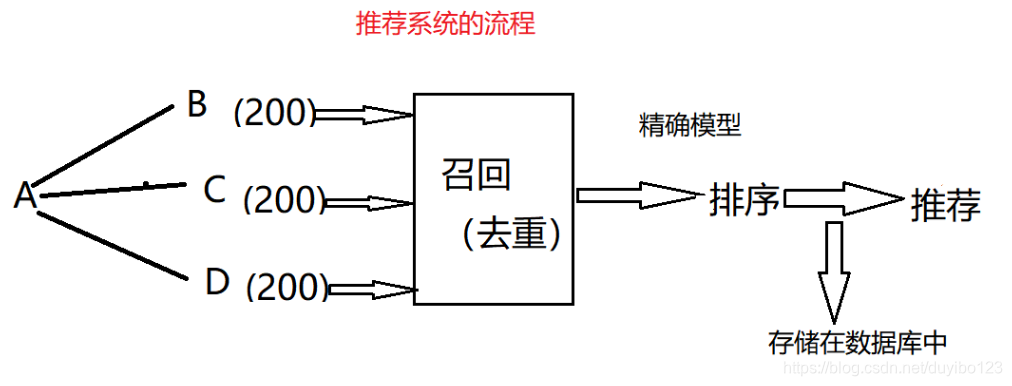
基于用户的协同过滤算法的优点是能够利用用户的历史行为数据进行推荐,具有较好的个性化效果。但是也存在一些缺点,比如对于新用户,无法准确预测其兴趣,需要等待其产生足够的历史行为数据;同时也存在冷启动问题,即对于新加入的物品,无法在初始阶段进行有效的推荐。
二、基于物品的协同过滤算法
基于物品的协同过滤算法是一种推荐算法,它利用用户对物品的评分数据来发现物品之间的相似度,从而给用户推荐与其历史兴趣相似的物品。该算法的核心思想是基于物品的相似度,预测用户对物品的评分。
具体而言,基于物品的协同过滤算法的过程如下:
1、计算每对物品之间的相似度。常用的计算方法包括余弦相似度和皮尔逊相关系数等。
2、找到用户历史评分过的物品,对于给定的目标用户,需要找到其历史评分过的物品集合。
3、计算每个物品的加权评分
4、给用户推荐物品
基于物品的协同过滤算法相比于基于用户的协同过滤算法,其优点在于可以在物品数量较多的情况下快速计算出相似度矩阵,且推荐结果更为稳定和准确。
三、关键公式
皮尔逊相关系数:

余弦相似度:

皮尔逊相关系数和余弦相似度是用于衡量向量之间相似性的两种常用方法。它们在计算方式和应用场景上存在一些区别。1、计算方式:
皮尔逊相关系数是通过计算两个向量的协方差除以它们的标准差的乘积来度量它们之间的相似性。其取值范围为[-1,1],其中1表示完全正相关,-1表示完全负相关,0表示不相关。 余弦相似度是通过计算两个向量的夹角余弦值来度量它们之间的相似性。其取值范围为[-1,1],其中1表示完全相似,-1表示完全相反,0表示无相似性。2、应用场景:
皮尔逊相关系数常用于处理具有数值属性的数据,如评分数据,以及在时间序列分析中。它可以**度量两个变量之间的线性相关性,适用于连续变量**。 余弦相似度**常用于处理文本数据和其他稀疏数据**,如推荐系统中的物品推荐。它可以度量两个向量之间的角度和方向,适用于处理大规模稀疏数据。
计算预测分值:
分子是对n个不同用户对同一商品的分析,而分母则是把每个用户单独的拿出来,分析不同商品

同现相似度:
其中,分母是喜欢物品i的用户数,而分子则是同时喜欢物品i和物品j的用户数。因此,下述公式可用理解为喜欢物品i的用户有多少比例的用户也喜欢j (和关联规则类似)
分母|N(i)|是喜欢物品 i 的用户数,而分子|N(i)∩N(j)|是同时喜欢物品 i 和j 的用户,但是如果物品 j 很热门,就会导致 Wij 很大接近于 1。因此避免推荐出热门的物品,我们使用下面的公式:


用户 u 对于物品 j 的兴趣:

四、实例
4-1 基于用户的协同过滤----余弦相似度
用户间相似度计算:
用户A与用户B的相似度=(5*0+1*0+0*4.5+0*3)/(SQRT(5^2+1^2+0^2+0^2)*SQRT(0^2+0^2+4.5^2+3^2)) =0 用户A与用户C的相似度=(5*1+1*4+0*0+0*4)/(SQRT(5^2+1^2+0^2+0^2)*SQRT(1^2+4^2+0^2+4^2)) =0.307254934 用户B与用户C的相似度=(0*1+0*4+4.5*0+3*4)/(SQRT(0^2+0^2+4.5^2+3^2)*SQRT(1^2+4^2+0^2+4^2)) =0.38624364计算喜爱度:
用户A对商品3的喜爱度=用户A与用户B的相似度用户B对商品3的评分+用户A与用户C的相似度用户C对商品3的评分=04.5+0.3072549340=0
用户A对商品4的喜爱度=用户A与用户B的相似度用户B对商品4的评分+用户A与用户C的相似度用户C对商品4的评分=03+0.3072549344=1.22901974
用户B对商品1的喜爱度=用户B与用户A的相似度用户A对商品1的评分+用户B与用户C的相似度用户C对商品1的评分=05+0.386243641=0.38624364


4-2 基于用户的协同过滤----皮尔逊系数
** 计算相似度:(用户C 商品4 为例)**
只有用户 A 和用户 D 对商品 4 评过分,因此候选邻居只有 2 个,分别为用户 A 和用户 D。
** 计算预测分值:**
** 其它手写推导:**
用户A:
** 用户B:**
** 用户D:**
** 用户E:**








4-3 基于物品的协同过滤----余弦相似度
商品余弦相似度计算结果如下:
商品1与商品2的相似度=(51+00+1*4)/(SQRT(5^2+0^2+1^2)*SQRT(1^2+0^2+4^2))=0.428086345
商品1与商品3的相似度=(50+04.5+1*0)/(SQRT(5^2+0^2+1^2)*SQRT(0^2+4.5^2+0^2))=0
....
计算喜爱度:
用户A对商品3的喜爱度=商品1与商品3的相似度用户A对商品1的评分+商品2与商品3的相似度用户A对商品2的评分+商品4与商品3的相似度用户A对商品4的评分=05+01+0.60=0
用户A对商品4的喜爱度=商品1与商品4的相似度用户A对商品1的评分+商品2与商品4的相似度用户A对商品2的评分+商品3与商品4的相似度用户A对商品4的评分=0.1568929085+0.7761141+0.60=1.560578541
用户B对商品1的喜爱度=商品1和商品2的相似度用户B对商品2的评分+商品1和商品3的相似度用户B对商品3的评分+商品1与商品4的相似度*用户B对商品4的评分=0.47067872


另一个例子:
共现矩阵C表示同时喜欢两个物品的用户数,是根据用户物品对应关系表计算出来的。
相似矩阵




补充:
1、共现矩阵(同时喜欢两个物品用户的人数)
** 2、相似度算法改进**
从前面的讨论可以看到,在协同过滤中两个物品产生相似度是因为它们共同出现在很多用户的兴趣列表中。换句话说,每个用户的兴趣列表都对物品的相似度产生贡献。**那么是不是每个用户的贡献都相同呢?**假设有这么一个用户,他是开书店的,并且买了当当网上80%的书准备用来自己卖。那么他的购物车里包含当当网80%的书。假设当当网有100万本书,也就是说他买了80万本。从前面对ItemCF的讨论可以看到,这意味着因为存在这么一个用户,有80万本书两两之间就产生了相似度,也就是说,内存里即将诞生一个80万乘80万的稠密矩阵。
John S. Breese在论文1中提出了一个称为IUF(Inverse User Frequence),即**用户活跃度对数的倒数**的参数,他也认为**活跃用户对物品相似度的贡献应该小于不活跃的用户**,他提出应该增加IUF参数来修正物品相似度的计算公式:
上述公式对活跃用户做了一种软性的惩罚,但是对于很多过于活跃的用户,比如上面那位买了当当网80%图书的用户,为了避免相似度矩阵过于稠密,我们在实际计算中一般直接忽略他的兴趣列表,而不将其纳入到相似度计算的数据集中。
3、相似度矩阵归一化处理
Karypis在研究中发现如果将ItemCF的**相似度矩阵按最大值归一化,可以提高推荐的准确率**。其研究表明,如果已经得到了物品相似度矩阵w,那么可以用如下公式得到归一化之后的相似度矩阵w':
实验表明,归一化的好处不仅仅在于增强推荐的准确度,还可以提高推荐的覆盖率和多样性。




(2条消息) 基于用户的协同过滤算法(userCF)_overlordmax的博客-CSDN博客
https://blog.csdn.net/qq_52358403/article/details/112768902
协同过滤算法 | JIANG-HS
「Hive」协同过滤推荐系统-余弦相似度 - 知乎 (zhihu.com)
基于物品的协同过滤算法(ItemCF)原理以及代码实践 - 简书 (jianshu.com)
版权归原作者 WoneDai 所有, 如有侵权,请联系我们删除。