
在图像处理领域,想要更高效、准确的解决方法,我们可以考虑多模态图像融合。
多模态图像融合是一种创新的方法,有关它的研究是当下的热门,每年的顶会论文数量也比较多。这是因为它可以结合多个来源的图像数据,为我们提供更全面的信息,以此来提高图像处理任务的准确性和效率。
这种技术的核心在于捕捉并整合各种图像数据中的互补信息,因此它不仅限于提升图像质量,还能在实际应用中解决复杂问题,适配多种场景。
目前已有多个最新成果在各项关键性能指标上都实现了SOTA结果。为帮助有论文需求的同学了解这种技术的最新动态,我这次整理了9个多模态图像融合创新方案,都是今年最新且有代码。
论文原文+开源代码需要的同学看文末
TSJNet: A Multi-modality Target and Semantic Awareness Joint-driven Image Fusion Network
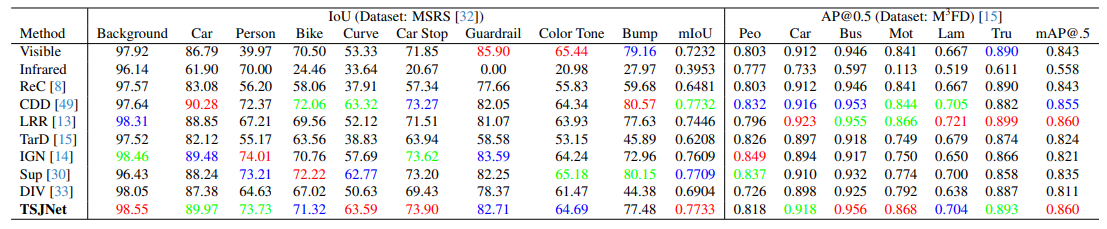
方法:论文介绍了TSJNet多模态图像融合网络。该网络旨在通过整合来自不同模态的互补信息到单一图像中,以增强图像的细节和语义信息。在目标检测和语义分割方面,相比于现有最先进的方法,分别实现了平均2.84%和7.47%的性能提升。
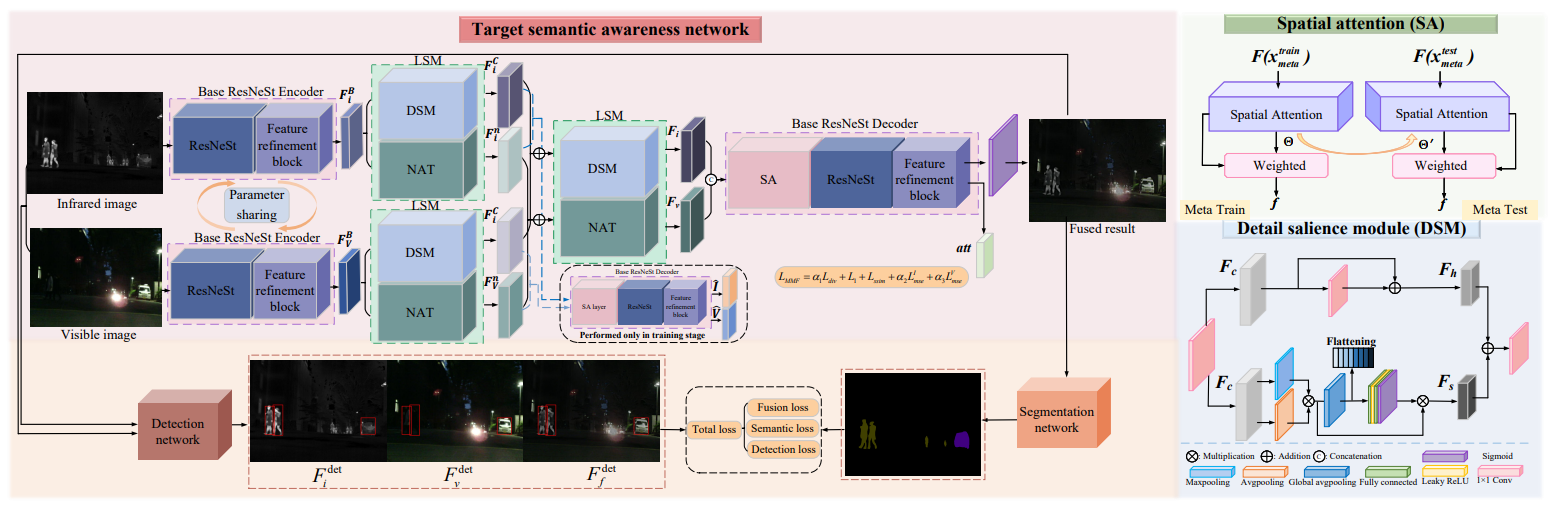
创新点:
- 提出了一种目标和语义感知的联合驱动融合网络,通过自编码器结构和设计良好的DSM,完全提取了跨模态的独立模态特征,并将检测损失和分割损失融合到融合网络中。
- 首次在融合网络中同时引入了检测和分割任务,通过开发具有并行双分支的LSM来充分提取局部细节,从而提高融合网络的灵活性和整合互补属性特征的能力。
- 提出了一种以语义和目标相关信息为基础的融合模型,实现对实际场景中高级语义和目标信息的捕捉。
Coconet: Coupled contrastive learning network with multi-level feature ensemble for multi-modality image fusion
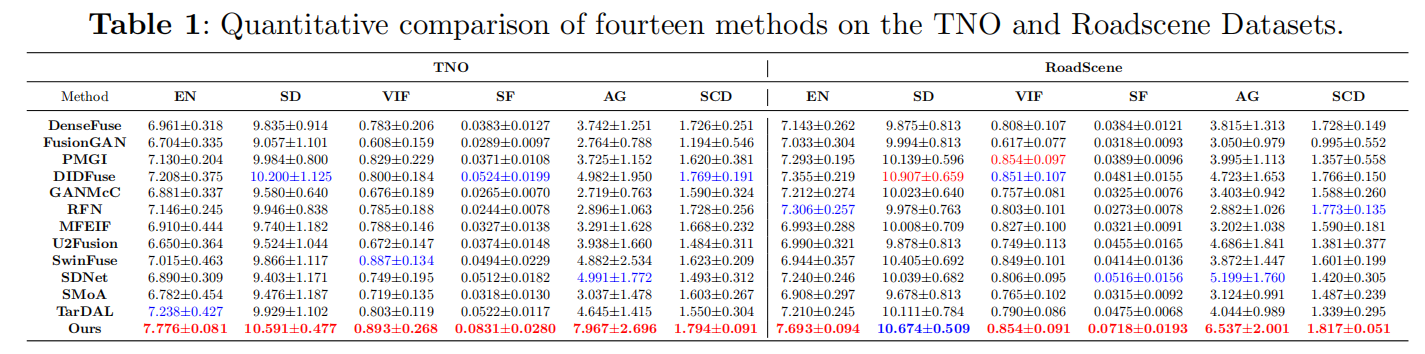
方法:论文提出了一种名为CoCoNet的网络,用于实现多模态图像融合。这种方法旨在通过结合不同传感器的互补信息来生成一个信息丰富的图像。在多个数据集上通过定性和定量实验证明了其优越性,尤其是在红外和可见光图像融合任务中,实现了在保留显著目标和恢复重要纹理细节方面的最先进(SOTA)性能。
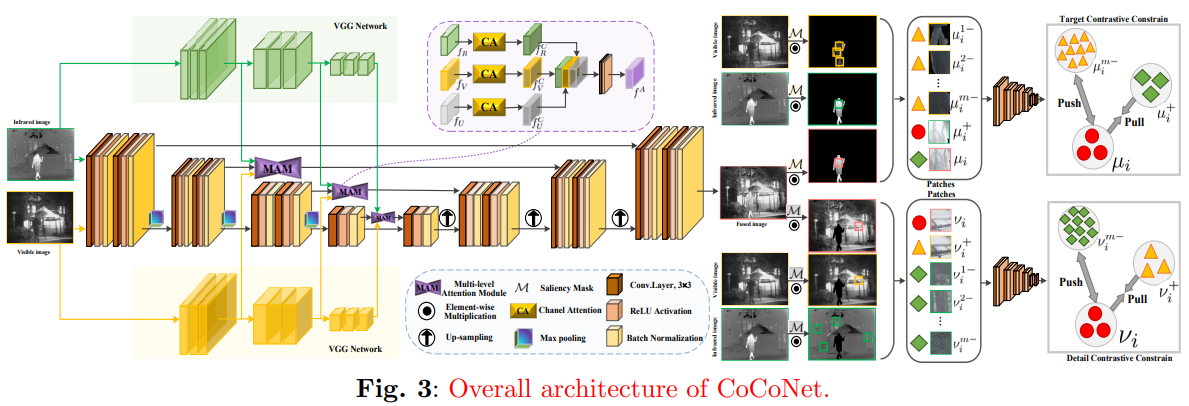
创新点:
- 针对红外和可见光图像融合的问题,提出了一种耦合对比学习网络CoCoNet。
- 引入了耦合对比学习约束,用于引导模型区分显著目标和纹理细节,从而提取和融合各模态中的理想特征。
- 使用数据驱动的权重计算机制替代手动调整的参数,提升了源图像和融合结果之间的强度和细节一致性。
Bridging the Gap between Multi-focus and Multi-modal: A Focused Integration Framework for Multi-modal Image Fusion
方法:本研究提出了一种用于多模态图像融合的焦点信息整合框架。该方法首先利用SSF将源图像分解为结构和纹理成分,然后通过金字塔引导的多尺度特征检测来融合纹理层,同时利用基于熵的有效融合策略提取结构层中的能量信息。
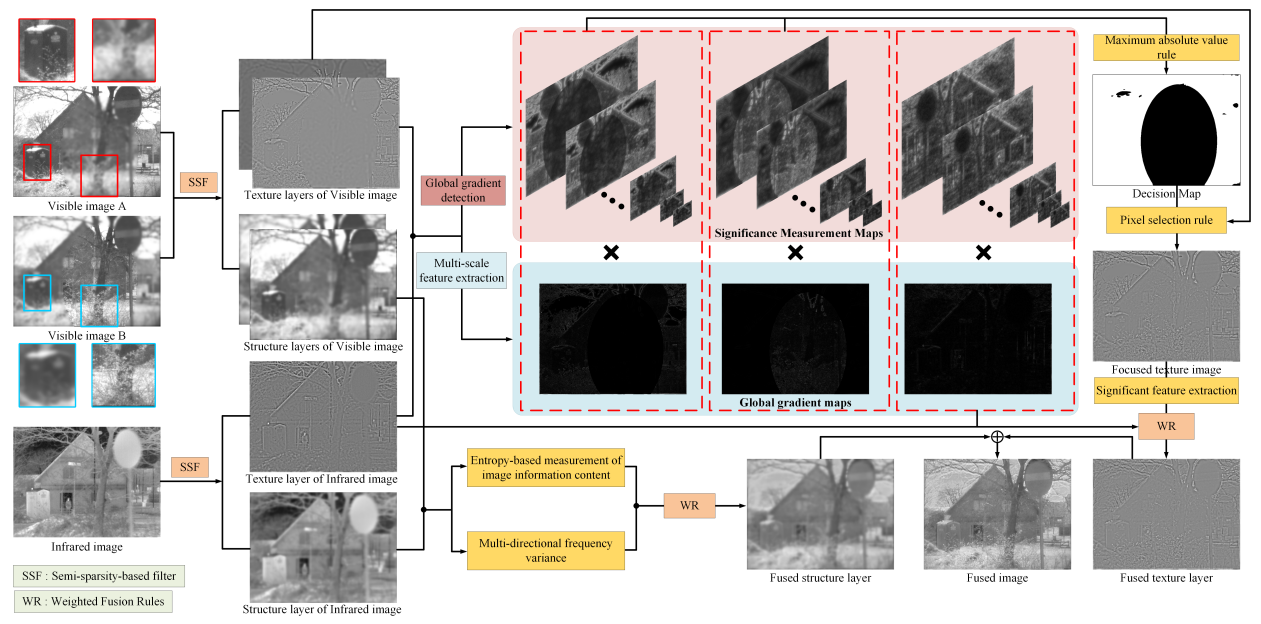
创新点:
- 提出了一种用于多模态图像融合(MMIF)的聚焦信息集成框架,解决了图像焦点区域不完整和同时捕获特定于不同模态的显著信息的困难。
- 提出了一种用于MMIF的聚焦信息集成框架,能够同时集成来自不同焦点区域的清晰像素信息和来自不同模态的显著像素信息。
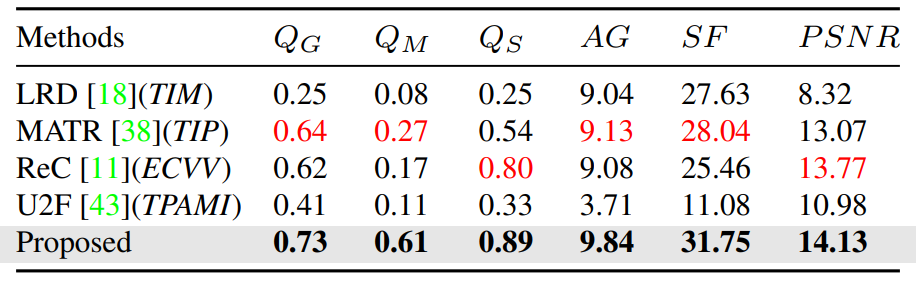
Improving Misaligned Multi-modality Image Fusion with One-stage Progressive Dense Registration
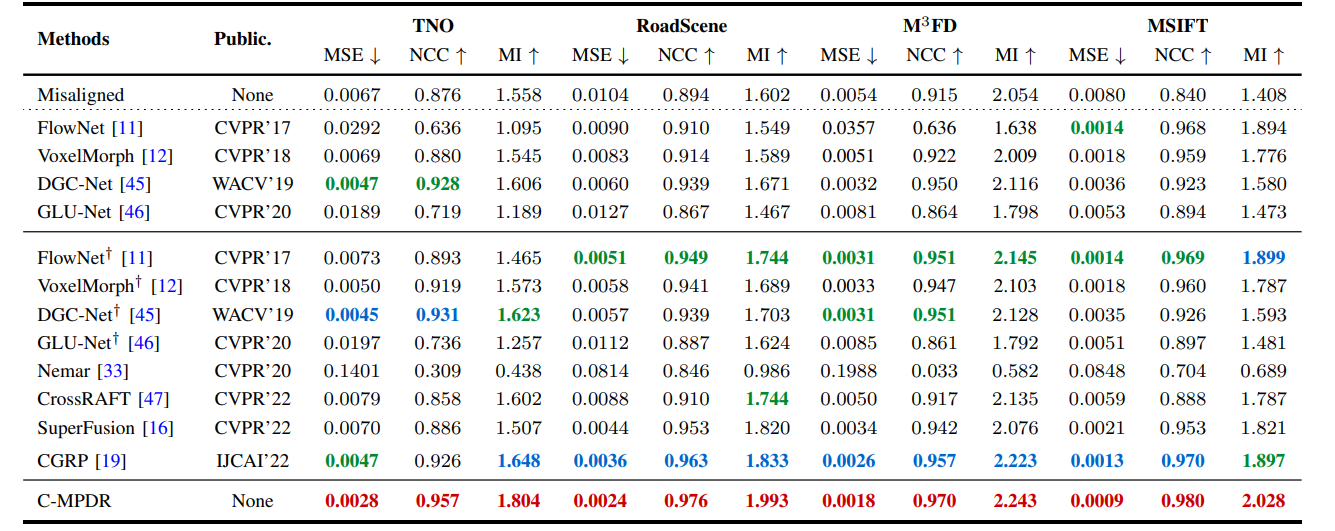
方法:论文解决多模态图像融合中的配准问题,提出了一种名为IMF的改进方法,通过交叉模态多尺度渐进密集配准和基于Transformer-Conv的融合子网络来有效减轻结构失真和边缘幽灵,并提出了两个模块DFF和PFF来进一步提高配准效果和保持图像质量。
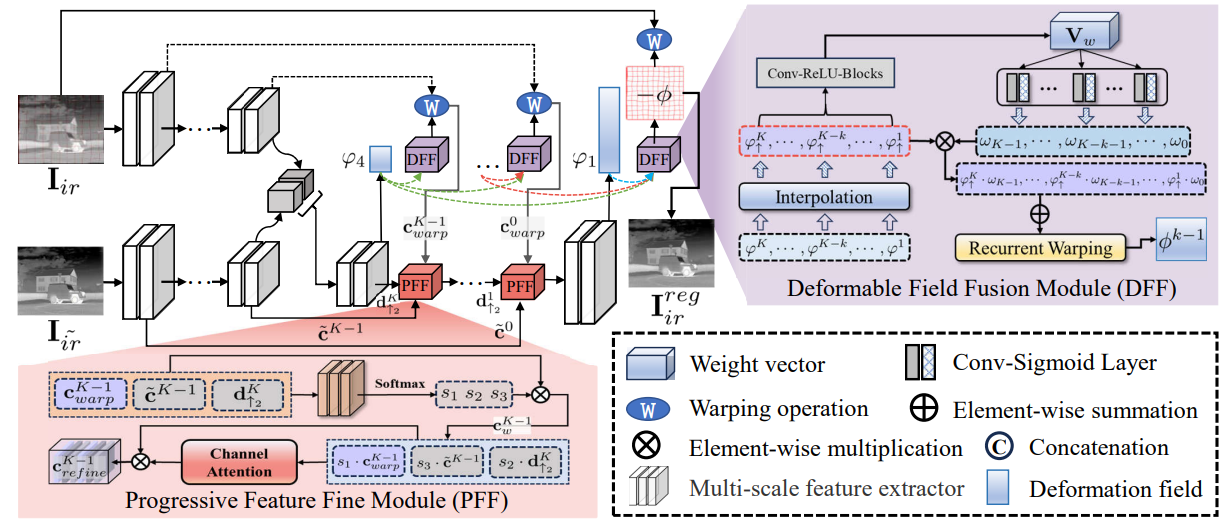
创新点:
- 作者引入了一种名为C-MPDR的多尺度渐进稠密注册子网络,用于实现异态图像的交叉模态图像注册。
- 作者引入了一种基于Transformer-Conv的融合子网络TCF,用于融合经过注册的红外图像和可见光图像。该网络利用Transformer-Conv块提取局部和全局的多模态特征,并将它们融合成具有显著和有意义信息的图像。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“融合新9”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏
版权归原作者 深度之眼 所有, 如有侵权,请联系我们删除。