
声明:笔者翻译论文仅为学习研究,如有侵权请联系作者删除博文,谢谢!
源论文地址:[2210.06551] MotionBERT: Unified Pretraining for Human Motion Analysis (arxiv.org)
项目:MotionBERT
摘要
我们提出了一个统一的训练前框架MotionBERT,以解决人体运动分析的不同子任务,包括3D姿势估计、基于骨骼的动作识别和网格恢复。该框架能够利用各种人体运动数据资源,包括运动捕捉数据和野外视频。在预训练中,托词任务要求运动编码器从有噪声的部分2D观测中恢复潜在的3D运动。预先训练的运动表示因此获得关于人体运动的几何、运动学和物理知识,因此可以很容易地转移到多个下游任务。我们用一种新的双流时空转换神经网络实现了该运动编码器。它可以全面和自适应地捕捉骨骼关节之间的远程时空关系,从零训练得到的3D姿态估计误差最
1介绍:
感知和理解人类活动一直是机器智能的核心追求。为此,研究人员定义了各种子任务来从视频中抽象语义表示,例如骨架关键点[13,31]、动作标签[53,107]和表面网格[41,59]。虽然现有的研究在每个子任务上都取得了显著的进展,但它们往往以不连贯的方式限制和模拟问题。
例如,图卷积网络(Graph Convolutional Networks, GCN)已被应用于建模spatio-1Project page: https://motionbert.github.io/temporal中的人体关节在三维姿态估计[12,25,101]和动作识别[83,107]中的关系,但它们之间的联系很少被探索。直观地说,这些模型都应该学会捕捉典型的人类运动模式,尽管它们是针对不同的问题设计的。尽管如此,目前的方法无法在子任务中挖掘和利用这些共性。
统一人体运动分析的子任务的一个主要障碍是数据资源的异质性。动作捕捉系统[34,63]提供了带有标记和传感器的高保真3D运动,但捕获的视频的外观通常局限于简单的室内场景。动作识别数据集提供了动作语义的注释,但它们要么不包含人体姿势标签[15,82],要么特征为日常活动的有限动作[52,53,81]。野外(wild,有遮挡等,可以看in the wild这篇人体姿态估计文章)人类视频可以通过不同的外观和动作大规模访问,但获得精确的2D姿势注释需要付出巨大的努力,而获得正确标记的数据(GT) 3D关节位置几乎是不可能的。因此,现有的研究基本上集中在一个特定的子任务使用孤立类型的运动数据。

图1。框架概述。拟议的框架包括两个阶段。在预训练阶段,我们从各种运动数据源中提取二维骨骼序列。然后,我们通过应用随机掩模和噪声来破坏2D骨架,然后训练运动编码器来恢复3D运动。在微调阶段,我们通过联合优化预训练的运动编码器和几个线性层,使学习到的运动表示适应不同的下游任务。
在本文中,我们引入了一个名为MotionBERT的新框架,用于跨各种子任务的人体运动分析,如图1所示。它由统一的预训练阶段和特定任务的优化阶段组成,其动机来自于近期在自然语言处理[11,26,78]和计算机视觉[7,32]方面的成功实践。在预训练过程中,训练一个运动编码器从损坏(不可靠的)的2D骨骼序列中恢复三维人体运动,该骨骼序列可以包含不同类型的人体运动数据源。这个具有挑战性的前置任务(为完成特定训练任务而设计的间接任务)本质上要求运动编码器i)从它的时间运动推断出潜在的3D人体结构;Ii)恢复错误和遗漏的观察结果。通过这种方式,运动编码器捕捉人体运动常识,如关节连接、解剖学约束和时间动力学。在实践中,我们提出双流时空转换器(DSTformer)作为运动编码器来捕获骨架关键点之间的远程关系。我们假设从大规模和多样化的数据资源中学习到的运动表示可以被所有相关的下游任务共享,并提高它们的性能。因此,对于每个下游任务,我们使用任务特定的训练数据和监督信号,用一个简单的回归头调整预先训练的运动表示。
综上所述,本工作的贡献有三个方面:1)我们提出了一种统一的预训练方法,以利用大规模而异质的人体运动源并学习可泛化的运动表示。我们的方法可以同时利用3D动作捕捉数据的准确性和野生RGB视频的多样性。2)我们设计了一个具有级联时空自我注意块的双流Transformer网络,作为人体运动建模的一般主干。3)提出的统一预训练方法提供了一种多功能的人体运动表示,即使在标记数据稀缺的情况下,也可以将其转移到多个下游任务。在没有铃铛和口哨的情况下,MotionBERT在3D姿势估计、基于骨骼的动作识别和网格恢复方面分别优于最先进的方法
2 相关工作
Learning Human Motion Representations.
早期的作品用隐马尔可夫模型[46,94]和图形模型[44,86]来描述人体运动。Kanazawa等人[38]设计了一个时间编码器和一个幻觉器来学习三维人体动力学的表示。Zhang等人[114]以自监督的方式预测了未来的3D动态。Sun等人[89]进一步将动作标签与动作记忆库结合起来。从动作识别的角度来看,设计了各种借口任务,以自我监督的方式学习运动表示,包括未来预测[87]、拼图游戏[49]、骨骼对比[93]、速度变化[88]、交叉视图一致性[51]和对比重建[102]。在诸如运动评估[29,72]和运动重定向[110,121]等任务中也探索了类似的技术。这些方法利用均匀运动数据,设计相应的借口任务(前置任务,后面的借口任务都是前置任务),并将其应用于特定的下游任务。在这项工作中,我们提出了一个统一的训练前优化框架来整合异构数据资源,并展示了其在各种下游任务中的通用性。
3D Human Pose Estimation.
三维人体姿态估计方法可分为两类。第一种是直接从图像中估计CNN的3D姿势[69,91,118]。这些方法的一个局限性是,在当前的数据收集技术下,3D姿势精度和外观多样性之间需要权衡。第二类是先提取二维姿态,然后用单独的神经网络将估计的二维姿态提升到三维。提升可通过全连接网络[65]、时间卷积网络(TCN)[21,77]、GCN[12,25,101]和变压器[48,116,117]实现。我们的框架是建立在第二类,因为我们使用拟议的DSTformer来完成2D-to-3D前置任务(为了达到特定训练任务而设计的间接任务
Skeleton-based Action Recognition.
早期的研究[62,100,111]指出了人体姿态估计与动作识别之间的内在关系。对于人体关节之间的时空关系建模,前人的研究采用了LSTM[85,120]和GCN[20,47,57,83,107]。最近,PoseConv3D[28]提出将3D-CNN应用于叠加的二维关节热图,并取得了改进的结果。除了完全监督的动作识别任务,NTU-RGB+D-120[53]引起了人们对具有挑战性的一次性动作识别问题的关注。为此,SL-DML[68]将深度度量学习应用于多模态信号。Sabater等人[80]探讨了TCN治疗场景中的一次性识别。我们证明了预训练的运动表示可以很好地推广到动作识别任务,预训练-微调框架是一个适合的解决一次性挑战的方案。
Human Mesh Recovery
基于SMPL[59]等参数化人体模型,许多研究工作[37,70,106,115]关注从单幅图像回归人体网格。尽管它们的每帧结果都很有前景,但当应用于视频时,这些方法产生抖动和不稳定的结果[41]。一些作品[22,38,41,92]以视频片段作为输入,利用时间线索产生更流畅的结果。另一个常见的问题是成对图像和GT网格大多是在受限场景下捕获的,这限制了上述方法的泛化能力。为此,Pose2Mesh[23]建议首先使用现有的姿态估计器提取2D骨架,然后将它们提升到3D网格顶点。我们采用2D骨架作为中间表示,并将其进一步扩展到视频输入,这减少了模糊性,并可以进一步受益于我们预先训练的运动表示。
3 方法
3.1概述
正如第1节所讨论的,我们的方法包括两个阶段,即统一的预训练和特定任务的微调。在第一阶段,我们训练一个运动编码器来完成2d到3d的提升任务,其中我们使用所提出的DSTformer作为骨干。在第二阶段,我们对预训练的运动编码器和下游任务的一些线性层进行微调。我们使用2D骨架序列作为预训练和微调的输入,因为它们可以可靠地从各种运动源中提取[3,9,63,73,90],而且对变化的鲁棒性更强[18,28]。已有研究表明,对于不同的下游任务(用于预训练的任务被称为前置/代理任务(pretext task),用于微调的任务被称为下游任务(downstream task)),使用2D骨架序列是有效的[23,28,77,95]。我们将首先介绍DSTformer的体系结构,然后详细描述训练方案。
图2显示了2D-to-3D吊装的网络架构。给定输入的二维骨架序列x∈RT ×J×Cin,我们首先将其投影到高维特征F0∈RT ×J×Cf上,然后将可学习的空间位置编码ps pos∈R1×J×Cf和时间位置编码PT pos∈RT ×1×Cf加入其中。然后利用序列对序列模型DSTformer计算Fi∈RT ×J×Cf (i = 1,…, N)其中N为网络深度。我们对FN应用具有tanh激活的线性层来计算运动表示one∈RT ×J×Ce。最后,我们应用线性变换toE来估计3D运动的X∈RT ×J×Cout。这里,T表示序列长度,J表示身体关节的数量。Cin、Cf、Ce、Cout分别为输入通道号、特征通道号、嵌入通道号、输出通道号。首先介绍了DSTformer的基本构建模块,即具有多头自注意的时空模块(MHSA),然后阐述了DSTformer的结构设计。
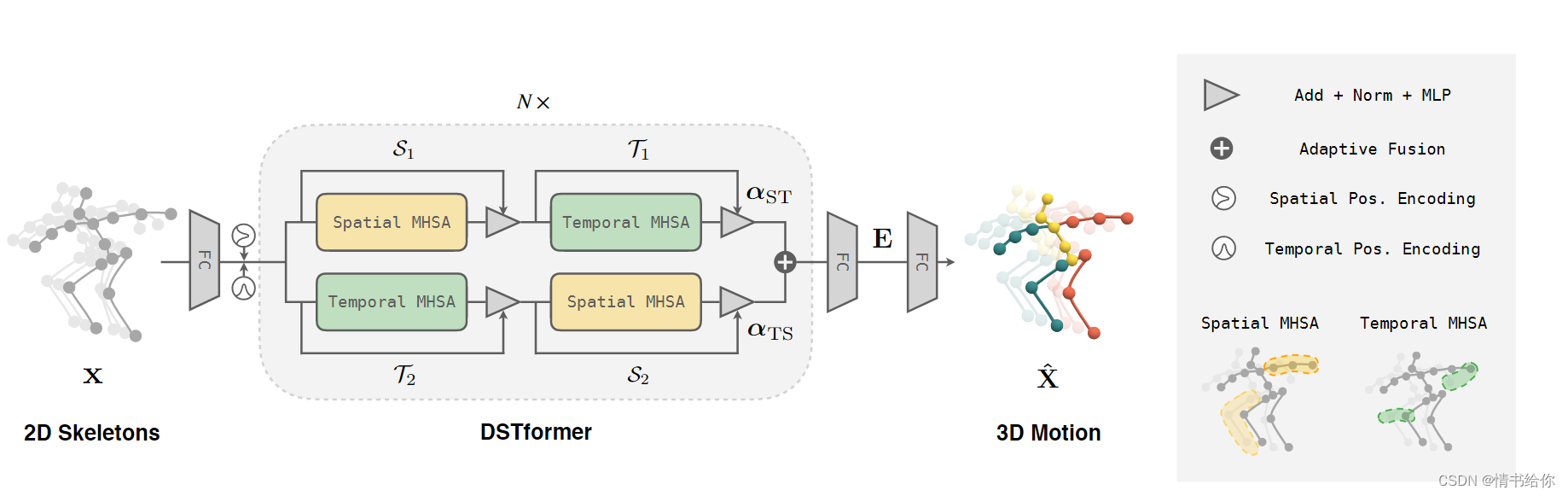
图2。模型架构。我们提出双流时空转换器(DSTformer)作为人体运动分析的一般主干。DSTformer由N个双流融合模块组成。每个模块包含两个时空分支MHSA和MLP。空间MHSA模拟不同关节在一个时间步长的连接,而时间MHSA模拟一个关节的运动。
3.2网络结构
空间快
空间MHSA (S-MHSA)旨在建模同一时间步长的关节之间的关系。它被定义为
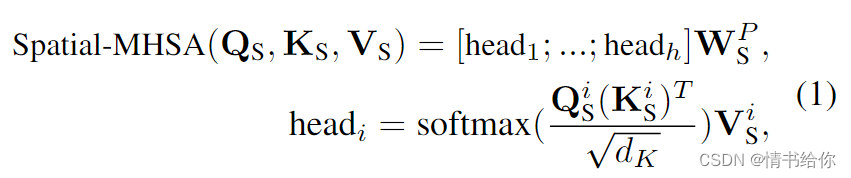
其中WPS为投影参数矩阵,h为正面个数,i∈1,…h.我们利用自注意,从每个headi的输入每帧空间特征FS∈RJ×Ce中得到查询QS、键KS和值VS,

其中W(Q,i)S, W(K,i)S, W(V,i)S为投影矩阵,dk为KS的维数。我们将S-MHSA并行应用于不同时间步长的特征。S-MHSA结果采用残差连接和层归一化(LayerNorm),再将其馈入多层感知器(MLP),然后进行残差连接和LayerNorm跟踪[98]。我们用MHSA、LayerNorm、MLP和S表示整个空间块
时间块
时间MHSA (T-MHSA)旨在为身体关节建模跨时间步的关系。其计算过程与S-MHSA相似,不同之处是MHSA应用于每个关节的时间特征FT∈RT ×Ce,并在空间维度上并行化

其中I∈1,…, h, QT, KT, VT的计算方法与公式2相似。我们用T来表示整个时间块。
双流时空转换器
给定分别捕获帧内和帧间身体关节相互作用的空间和时间MHSA,我们组装基本构建块以融合流中的空间和时间信息。我们设计了一个双流体系结构,其指导原则如下:1)两种流都可以模拟综合时空上下文。2)两种流分别针对不同的时空方面。3)将两种流融合在一起,并根据输入时空特征动态平衡融合权重
因此,我们将空间和时间的MHSA块按不同的顺序堆叠,形成两个并行计算分支。利用注意回归器预测的自适应权值融合两个分支的输出特征。然后双流融合模块重复n次

其中Fi表示功能嵌入深度i,◦表示元素明智的生产。S块和T块的顺序如图2所示,不同块不共享权重。自适应融合权值αST, αTS∈RN ×T ×J为
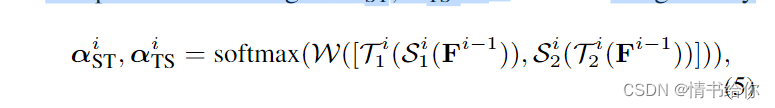
其中W是一个可学习的线性变换。[,]表示连接
3.3Unified Pretraining
在设计统一预训练框架时,我们解决了两个关键问题:1)如何学习具有通用借口任务的强大运动表示 2)如何利用各种格式的大规模、异构的人体运动数据。
对于第一个挑战,我们遵循语言[11,26,78]和视觉[7,32]建模中预先训练的模型来构建监督信号,即掩码部分输入,并使用编码后的表示来重构整个输入。需要注意的是,人体运动分析中自然存在这样的“完形”任务,即从二维视觉观察中恢复丢失的深度信息,即三维人体姿态估计。受此启发,我们利用大规模3D动作捕捉数据[63],设计了一个2D-to-3D托举任务。我们首先通过投影三维运动正字法提取二维骨架序列x。然后,我们通过随机遮蔽和添加噪声来破坏x,生成破坏的2D骨架序列,它也类似于2D检测结果,因为它包含遮挡、检测失败和错误。联合级和帧级掩码都以一定的概率应用。我们使用前面提到的运动编码器来获得运动表示E,并重建3D运动dxx。然后我们计算出了在putty X和GT 3D运动X之间的关节损失L3D。我们还在之前的工作[77,116]基础上添加了速度损失LO。三维重建损失由
Ot = ˆXt − ˆXt−1, Ot = Xt − Xt−1.
对于第二个挑战,我们注意到2D骨骼可以作为一种通用媒介,因为它们可以从各种运动数据源中提取出来。我们进一步将野外RGB视频整合到2D-to-3D吊装框架中,进行统一的预训练。对于RGB视频,2D骨架可以通过手动注释[3]或2D姿态估计器[13,90]给出,提取的2D骨架深度通道在本质上是“被屏蔽的”。类似地,我们添加额外的掩码和噪声来降低x(如果x已经包含检测噪声,则只应用掩码)。由于3D运动GTX无法用于这些数据,我们应用加权的二维重投影损失计算通过
其中,ˆx 为估计的3D运动ˆX的二维正交投影,δ∈RT ×J由可见性标注或二维检测置信度给出。总训练前损失计算为 
其中λO是一个常数系数,以平衡训练损耗
3.4 特定任务整合
学习到的特征嵌入E作为三维感知和时间感知的运动表示。对于下游任务,我们采用极简设计原则,即实现浅层的下游网络和无花哨的培训。在实践中,我们使用额外的线性层或带有一个隐藏层的MLP。然后我们对整个网络端到端进行微调。
3D Pose Estimation.
由于我们使用2D-to-3D提升作为借口任务,我们简单地重用整个预训练网络(运动编码器+线性)。在微调过程中,输入的2D骨架是根据视频估计的,没有额外的掩模或噪声。
Skeleton-based Action Recognition.
我们只需对不同的人员和时间步骤执行全球平均池。然后将结果输入带有一个隐藏层的MLP。该网络采用交叉熵分类损失训练。对于一次性学习,我们在汇集特征后应用线性层提取剪辑级动作表示。我们将在第4.4节详细介绍一次性学习的设置
Human Mesh Recovery
我们用SMPL[59]模型来表示人体网格,并对其参数进行回归。SMPL模型由位姿参数θ∈R72和形状参数β∈R10组成,计算出三维网格asM(θ, β)∈R6890×3。为了对每一帧的姿态参数进行回归,我们将运动嵌入E输入到具有一个隐藏层的MLP中,得到π θ∈RT ×72。为了估计形状参数,考虑到视频序列上的人体形状应该是一致的,我们首先在时间维上对E进行平均池化,然后将其输入另一个MLP中,来回归单个的ˆβ,然后将其展开到整个序列ˆβ ∈ RT ×10。形状MLP与姿态回归具有相同的体系结构,它们分别用平均形状和姿态初始化,如[41]所示。总损失计算为 
其中每一项计算为
注意,帧t处运动中的每个3D位姿Xm由网格顶点由Xmt = JM(θt, βt)回归,其中j∈RJ×6890是一个预定义的矩阵[9]。λm 3D、λθ和λβ为常系数,以平衡训练损耗。
4 实验
4.1实现
我们实现了该运动编码器DSTformer,深度N = 5,头数h = 8,特征大小ecf = 256,嵌入大小Ce = 512。对于预训练,我们使用序列长度T = 243。由于基于transformer的主干,预训练的模型可以处理不同的输入长度。在调优过程中,我们将主干学习率设为新层学习率的0.1×。我们将在接下来的章节中分别介绍实验数据集。更多实验细节请参考附录A.1。
4.2 预训练
我们从Human3.6M[34]和AMASS[63]两个数据集中收集了不同的、真实的3D人体运动。Human3.6M[34]是一个常用的用于三维人体姿态估计的室内数据集,它包含360万专业演员进行日常动作的视频帧。在之前的工作[65,77]的基础上,我们使用主题1、5、6、7、8进行训练,使用主题9、11进行测试。AMASS[63]集成了大多数现有的基于标记的动作捕捉数据集[1,2,5,10,14,17,30,33,45,58,60,64,71,84,96,97],并使用通用表示对其进行参数化。我们在训练前不使用两个数据集的视频或二维检测结果;相反,我们使用正投影来获得未损坏的2D骨架。我们进一步合并了两个野生RGB视频数据集PoseTrack3和instvarety38,以获得更高的运动多样性。我们将人体关键点定义与Human3.6M对齐,并将摄像机坐标校准为[24]后的像素坐标。我们将15%的关节随机归零,并从高斯分布和均匀分布[16]的混合中采样噪声。我们首先只对3D数据进行30课时的训练,然后根据课程学习实践对3D数据和2D数据进行50课时的训练[8,103]
4.3 3D姿态估计
我们评估了Human3.6M[34]上的三维姿态估计性能,并报告了平均每个关节位置误差(MPJPE),单位为毫米,它测量的是在对准根关节后,预测关节位置与GT之间的平均距离。我们使用堆叠沙漏(stacking Hourglass, SH)网络[73]从视频中提取2D骨架,并在Human3.6M[34]训练集上微调整个网络。此外,我们训练相同架构的独立模型,但使用随机初始化而不是预先训练的权重。我们的两个模型都优于最先进的方法,如表1所示。从零开始训练的模型证明了所提出的DSTformer在学习三维几何结构和时间动力学方面的有效性。提出的预训练阶段进一步降低了误差,证明了统一归属框架的优势。
4.4基于骨骼的动作识别
我们进一步探讨了使用预先训练的动作表示学习动作语义的可能性。我们使用包含60个动作类57K视频的人体动作数据集NTU-RGB+D[81],并跟踪数据分割Cross-subject (X-Sub)和Cross-view (X-View)。该数据集有一个扩展版本,NTU-RGB+D-120[53],包含120个动作类的114K视频。我们遵循NTU-RGB+D-120上建议的一次性动作识别协议。对于这两个数据集,我们使用HRNet[90]提取[28]之后的2D骨架。同样,我们用随机初始化训练一个scratch模型进行比较。所有的模型都是无集成的。如表2所示,我们的方法可与最先进的方法相媲美或优于它们。值得注意的是,训练前阶段会带来很大的性能提升。
此外,我们还研究了具有实际意义的一次性设置。在实际部署中,对某些场景(例如教育、体育、医疗保健)的动作识别有很高的要求。然而,对于在公共数据集中看不到的新动作类,只有很少的注释可用。正如[53]中提出的,我们报告了20个新类的评估集的结果,每个类只使用一个标记的视频。辅助集包含其他100个类,这些类的所有样本都可以用于学习。我们使用监督对比学习技术[39]在辅助集上训练模型。对于一批辅助数据,同一类的样本被拉到一起,而不同类的样本被推到动作嵌入空间中。在评估过程中,我们计算测试例与范例之间的余弦距离,并使用1-最近邻来确定类。表2说明了提出的模型在相当大的差距上优于最先进的模型。同样值得注意的是,预训练的模型只需要1-2个阶段的微调就能达到最佳性能。结果表明,预训练阶段确实有助于学习良好的运动表示,这可以推广到新的下游任务,即使只有有限的数据注释。
4.5Human Mesh Recovery
我们在Human3.6M[34]和3DPW[99]数据集上进行了实验。对于Human3.6M,我们遵循传统的训练和测试分割[65],如第4.2节所示。对于3DPW,我们添加COCO[50]数据集用于[23]之后的训练。如[22,41]所示,我们报告了使用和不使用3DPW训练集的结果。按照惯例[37,41,43],我们报道了JM(θ, β)得到的14个关节的MPJPE (mm)和PA-MPJPE (mm)。PA-MPJPE在平移、旋转和缩放与GT对齐后计算MPJPE。我们进一步报告了网格M(θ, β)的平均每顶点误差(MPVE) (mm),它测量了对齐根节点后估计顶点与GT顶点之间的平均距离。
如表3所示,我们预先训练的版本在Human3.6M数据集上的所有指标都优于之前的所有方法。我们进一步评估了我们的方法在3DPW数据集上的泛化能力,3DPW数据集是一个具有挑战性的野外基准。在不使用3DPW训练集的情况下,我们的预训练运动表示方法显著超过了所有之前的工作,特别是在MPVE和MPJPE(改进了约10mm)。当使用额外的3DPW训练数据时,我们的方法进一步减少了估计误差,并不断优于以往的方法。性能优势表明了统一的预训练框架和学习的运动表示的好处。请注意,以前的大多数工作[22,37,41,42,61]使用更多的数据集而不是COCO[50]进行训练,如LSP [35], mpi - info - 3dhp[66]等。

4.6. Ablation Studies
模型架构
我们首先研究了DSTformer的设计选择,并在表6中报告了结果。从(a)到(f),我们比较了基本Transformer模块的不同结构。(a)和(b)是单流版本,顺序不同。(c)在融合前将每个流限制为时间或空间建模。(d)直接连接S-MHSA和T-MHSA,中间没有MLP。(e)用两个流的平均池化代替自适应融合。(f)是拟议的DSTformer设计。对于所有的变量,我们控制自我注意块的总数是相同的,所以网络容量不会是决定性的因素。结果证实了我们的设计原则,即两个流应该是有能力的,同时是互补的,如3.2节所介绍的。另外,我们发现将每个自我注意块与MLP配对是至关重要的,因为它可以投射学习到的特征相互作用,并带来非线性。从(g)到(k),我们尝试不同的模型尺寸。一般情况下,我们根据它们从零开始训练时的三维人体姿态估计任务的性能优化模型架构设计,并将该设计应用于所有任务,而无需进行额外的调整。
预训练策略
我们评估了不同的训练前策略如何影响下游任务的绩效。从零基线开始,我们一个一个地应用提出的策略。如表4所示,普通的2D-to-3D预训练阶段为所有下游任务带来好处。引入腐蚀还提高了学习到的运动嵌入。统一的预训练与野生视频享有更高的运动多样性,这进一步有助于若干下游任务
部分整合
除了端到端微调之外,我们还尝试冻结运动编码器主干,只为每个子任务训练下游网络。为了验证预训练的运动表示的有效性,我们比较了预训练的运动编码器和一个随机初始化的运动编码器。结果如表5所示。可以看出,基于冻结的预训练运动表示,我们的方法仍然可以在多个下游任务上获得竞争性能。相对于随机初始化方法的性能优势表明,泛化运动表示是通过预训练学习的。在实际应用中,通常需要同时获得多个子任务(例如动作+网格)的预测。现有的方法需要单独的模型来处理特定的子任务。预训练和部分微调使所有下游任务共享相同的骨干成为可能,这大大减少了计算开销。
5结论
在本文中,我们提出了MotionBERT,以统一与人体运动相关的各种子任务与训练前-精细模式。针对大规模人体运动数据,设计了二维到三维的起重托举任务进行预训练。我们还提出DSTformer作为一种通用的人体动作编码器。在多个基准上的实验结果证明了该方法的有效性。至于局限性,到目前为止,这项工作主要集中在从一个人的骨架中学习。未来的工作可能会探索将学习到的运动表示与图像特征融合,并明确地模拟人类互动。
版权归原作者 情书给你 所有, 如有侵权,请联系我们删除。