
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
在本章中,我们将从头开始构建 RoBERTa 模型。该模型将使用 BERT 模型所需的变压器构建套件的砖块。此外,不会使用预训练的标记器或模型。RoBERTa 模型将按照本章描述的十五步过程构建。
我们将使用在前面章节中获得的转换器知识,逐步构建一个可以对掩码标记进行语言建模的模型。在第 2 章“ Transformer 模型架构入门”中,我们介绍了原始 Transformer 的构建块。在第 3 章,微调 BERT 模型中,我们微调了预训练的 BERT 模型。
本章将重点介绍使用基于 Hugging Face 无缝模块的 Jupyter 笔记本从头开始构建预训练的 Transformer 模型。该模型被命名为 KantaiBERT。
KantaiBERT 首先加载为本章创建的伊曼纽尔·康德 (Immanuel Kant) 书籍的汇编。您将看到数据是如何获得的。您还将了解如何为此笔记本创建自己的数据集。
KantaiBERT 从头开始训练自己的标记器。它将构建它的合并和词汇文件,这些文件将在预训练过程中使用。
KantaiBERT 然后处理数据集,初始化一个训练器,并训练模型。
最后,KantaiBERT 使用经过训练的模型执行实验性下游语言建模任务,并使用 Immanuel Kant 的逻辑填充掩码。
在本章结束时,您将了解如何从头开始构建变压器模型。您将有足够的变压器知识来面对工业 4.0 的挑战,即使用强大的预训练变压器(例如 GPT-3 引擎),这需要的不仅仅是开发技能来实现它们。本章为您准备第 7 章,使用 GPT-3 引擎的超人变形金刚的崛起。
本章涵盖以下主题:
- RoBERTa 和 DistilBERT 类模型
- 如何从头开始训练分词器
- 字节级字节对编码
- 将训练好的分词器保存到文件中
- 为预训练过程重新创建标记器
- 从头开始初始化 RoBERTa 模型
- 探索模型的配置
- 探索模型的 8000 万个参数
- 为训练器构建数据集
- 初始化训练器
- 预训练模型
- 保存模型
- 将模型应用于Masked Language Modeling ( MLM )的下游任务
我们的第一步将是描述我们将要构建的变压器模型。
训练分词器和预训练转换器
在本章中,我们将训练使用构建块的名为 KantaiBERT 的变压器模型由 Hugging Face 为类 BERT 模型提供。我们介绍了将在第 3 章微调BERT 模型中使用的模型构建块的理论。
我们将在前面章节中获得的知识的基础上描述 KantaiBERT。
KantaiBERT 是一种基于架构的鲁棒优化的 BERT 预训练方法( RoBERTa ) 模型BERT。
正如我们在第 3 章中看到的那样,最初的 BERT 模型为最初的 Transformer 模型带来了创新功能。RoBERTa 增加通过改进预训练过程的机制来提高转换器在下游任务中的性能。
例如,它不使用
WordPiece
标记化但归结为字节级字节对编码(BPE)。这种方法为各种 BERT 铺平了道路和类似 BERT 的模型。
在本章中,KantaiBERT 与 BERT 一样,将使用Masked Language Modeling ( MLM ) 进行训练。MLM 是一种语言建模技术掩码序列中的一个单词。Transformer 模型必须训练来预测被屏蔽的单词。
KantaiBERT 将被训练为一个具有 6 层、12 个头和 84,095,008 个参数的小型模型。8400 万个参数似乎很多。但是,参数分布在 12 个磁头上,这使其成为一个相对较小的模型。一个小模型将使预训练体验变得流畅,从而可以实时查看每个步骤,而无需等待数小时才能看到结果。
KantaiBERT 是一个类似 DistilBERT 的模型,因为它具有相同的 6 层和 12 个头的架构。DistilBERT 是 BERT 的提炼版本。顾名思义,DistilBERT 包含的参数比 RoBERTa 模型少。因此,它的运行速度要快得多,但结果的准确性略低于 RoBERTa 模型。
我们知道大型模型可以实现出色的性能。但是,如果您想在智能手机上运行模型怎么办?小型化一直是技术发展的关键。在实施过程中,Transformers 有时必须遵循相同的路径。因此,使用 BERT 的精炼版本的拥抱脸方法是向前迈出的一大步。将来使用更少的参数或其他类似方法进行蒸馏是一种巧妙的方式,可以充分利用预训练并使其高效地满足许多下游任务的需求。
展示所有可能的架构很重要,包括在智能手机上运行一个小型模型。然而,变形金刚的未来也将是即用型 API,正如我们将在第 7 章“使用 GPT-3 引擎的超人变形金刚的崛起”中看到的那样。
KantaiBERT 将实现一个字节级的字节对编码标记器,就像 GPT-2 使用的那样。特殊代币将是 RoBERTa 使用的代币。BERT 模型最常使用 WordPiece 分词器。
没有令牌类型 ID 来指示令牌属于段的哪一部分。段将用分隔标记分隔
</s>
。
KantaiBERT 将使用自定义数据集,训练分词器,训练转换器模型,保存并运行它传销的例子。
让我们从头开始构建一个变压器。
从头开始构建 KantaiBERT
我们将从头开始用 15 个步骤构建 KantaiBERT,并在 MLM 示例上运行它。
打开谷歌Colaboratory(您需要一个 Gmail 帐户)。然后上传
KantaiBERT.ipynb
,在 GitHub 上在本章的目录中。
本节 15 个步骤的标题与笔记本单元格的标题相似,便于理解。
让我们从加载数据集开始。
第 1 步:加载数据集
即用型数据集提供了一种训练和比较变压器的客观方法。在第 5 章,带有 Transformer 的下游 NLP 任务中,我们将探索几个数据集。然而这一章旨在了解带有笔记本单元的变压器的训练过程,可以实时运行而无需等待数小时即可获得结果。
我选择使用启蒙时代的缩影德国哲学家伊曼纽尔·康德(Immanuel Kant,1724-1804)的作品。这个想法是为下游推理任务引入类人逻辑和预训练推理。
Project Gutenberg, https://www.gutenberg.org提供了广泛的免费电子书,可以以文本格式下载。如果您想根据书籍创建自己的自定义数据集,可以使用其他书籍。
我将伊曼纽尔·康德 (Immanuel Kant) 的以下三本书编译成一个名为的文本文件
kant.txt
:
- 纯粹理性批判
- 实践理性批判
- 道德形而上学的基本原理
kant.txt
提供了一个小的训练数据集来训练本章的transformer模型。获得的结果仍然是实验性的。例如,对于现实生活中的项目,我会添加伊曼纽尔·康德、勒内·笛卡尔、帕斯卡和莱布尼茨的全集。
文本文件包含书籍的原始文本:
…For it is in reality vain to profess _indifference_ in regard to such
inquiries, the object of which cannot be indifferent to humanity.
数据集会自动从 GitHub 下载到
KantaiBERT.ipynb
笔记本的第一个单元格中。
您还可以
kant.txt
使用 Colab 的文件管理器加载 GitHub 上本章目录中的 . 在这种情况下,
curl
用于从 GitHub 检索它:
#@title Step 1: Loading the Dataset
#1.Load kant.txt using the Colab file manager
#2.Downloading the file from GitHub
!curl -L https://raw.githubusercontent.com/Denis2054/Transformers-for-NLP-2nd-Edition/master/Chapter04/kant.txt --output "kant.txt"
加载或下载后,您可以看到它出现在 Colab 文件管理器窗格中:

图 4.1:Colab 文件管理器
请注意,当您重新启动 VM 时,Google Colab 会删除这些文件。
数据集已定义并加载。
不要运行没有
kant.txt. 训练数据是先决条件。
现在,节目将安装 Hugging Face 变压器。
第 2 步:安装 Hugging Face 变压器
我们需要安装 Hugging Face转换器和标记器,但我们不需要 TensorFlow在此 Google Colab VM 实例中:
#@title Step 2:Installing Hugging Face Transformers
# We won't need TensorFlow here
!pip uninstall -y tensorflow
# Install 'transformers' from master
!pip install git+https://github.com/huggingface/transformers
!pip list | grep -E 'transformers|tokenizers'
# transformers version at notebook update --- 2.9.1
# tokenizers version at notebook update --- 0.7.0
输出显示安装的版本:
Successfully built transformers
tokenizers 0.7.0
transformers 2.10.0
变压器版本正在以相当快的速度发展。您运行的版本可能不同,显示方式也不同。
该程序现在将从训练分词器开始。
第 3 步:训练分词器
在本节中,程序不使用预训练的分词器。例如,可以使用预训练的 GPT-2 标记器。但是,本章中的训练过程包括从头开始训练分词器。
Hugging Face
ByteLevelBPETokenizer()
将使用
kant.txt
. BPE 分词器会将字符串或单词分解为子字符串或子词。有两个主要优点对此,其中好多其它的:
- 分词器可以将单词分解成最小的组件。然后它将这些小组件合并成统计上有趣的组件。例如,“
smaller" and smallest”可以变成“small,”“er,”和“est.” 分词器可以走得更远。例如,我们可以得到“sm”和“all,”。在任何情况下,单词都被分解为子词标记和更小的子词部分单元,例如“sm”和“all”,而不是简单的“small.”。 unk_token使用级别编码,分类为未知的字符串块WordPiece实际上会消失。
在这个模型中,我们将训练分词器具有以下参数:
files=paths是数据集的路径vocab_size=52_000是我们的分词器模型长度的大小min_frequency=2是最小频率阈值special_tokens=[]是特殊标记的列表
在这种情况下,特殊标记的列表是:
<s>: 一个开始令牌<pad>: 填充标记</s>: 结束标记<unk>: 一个未知的令牌<mask>:语言建模的掩码标记
标记器将被训练以生成合并的子字符串标记并分析它们的频率。
让我们把这两个词放在一个句子的中间:
...the tokenizer...
第一步是对字符串进行标记:
'Ġthe', 'Ġtoken', 'izer',
该字符串现在被标记为带有
Ġ
(空白)信息的标记。
下一步是用它们的索引替换它们:
'Gthe’
'Ġtoken’
‘izer’
150
5430
4712
表 4.1:三个代币的指数
该程序运行分词器正如预期的那样:
#@title Step 3: Training a Tokenizer
%%time
from pathlib import Path
from tokenizers import ByteLevelBPETokenizer
paths = [str(x) for x in Path(".").glob("**/*.txt")]
# Initialize a tokenizer
tokenizer = ByteLevelBPETokenizer()
# Customize training
tokenizer.train(files=paths, vocab_size=52_000, min_frequency=2, special_tokens=[
"<s>",
"<pad>",
"</s>",
"<unk>",
"<mask>",
])
标记器输出训练所花费的时间:
CPU times: user 14.8 s, sys: 14.2 s, total: 29 s
Wall time: 7.72 s
标记器经过训练并准备好保存。
第 4 步:将文件保存到磁盘
标记器将生成两个文件时受过训练:
merges.txt,其中包含合并的标记化子字符串vocab.json,其中包含标记化子字符串的索引
程序首先创建
KantaiBERT
目录,然后保存两个文件:
#@title Step 4: Saving the files to disk
import os
token_dir = '/content/KantaiBERT'
if not os.path.exists(token_dir):
os.makedirs(token_dir)
tokenizer.save_model('KantaiBERT')
程序输出显示两个文件已保存:
['KantaiBERT/vocab.json', 'KantaiBERT/merges.txt']
这两个文件应该出现在文件管理器中有:
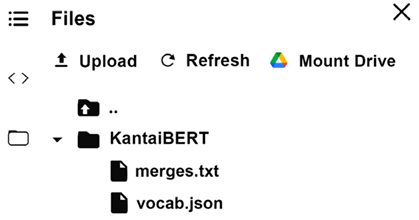
图 4.2:Colab 文件管理器
此示例中的文件很小。您可以双击它们以查看其内容。
merges.txt
按计划包含标记化的子字符串:
#version: 0.2 - Trained by 'huggingface/tokenizers'
Ġ t
h e
Ġ a
o n
i n
Ġ o
Ġt he
r e
i t
Ġo f
vocab.json
包含索引:
[…,"Ġthink":955,"preme":956,"ĠE":957,"Ġout":958,"Ġdut":959,"aly":960,"Ġexp":961,…]
经过训练的标记化数据集文件已准备就绪待处理。
第 5 步:加载经过训练的分词器文件
我们可以加载预训练的标记器文件。然而,我们训练我们自己的标记器,现在可以加载文件了:
#@title Step 5 Loading the Trained Tokenizer Files
from tokenizers.implementations import ByteLevelBPETokenizer
from tokenizers.processors import BertProcessing
tokenizer = ByteLevelBPETokenizer(
"./KantaiBERT/vocab.json",
"./KantaiBERT/merges.txt",
)
分词器可以编码一个序列:
tokenizer.encode("The Critique of Pure Reason.").tokens
"The Critique of Pure Reason"
会变成:
['The', 'ĠCritique', 'Ġof', 'ĠPure', 'ĠReason', '.']
我们还可以要求查看此序列中的token数量:
tokenizer.encode("The Critique of Pure Reason.")
输出将显示序列中有 6 个标记:
Encoding(num_tokens=6, attributes=[ids, type_ids, tokens, offsets, attention_mask, special_tokens_mask, overflowing])
标记器现在处理标记以适合此笔记本中使用的 BERT 模型变体。后处理器将添加一个开始和结束标记;例如:
tokenizer._tokenizer.post_processor = BertProcessing(
("</s>", tokenizer.token_to_id("</s>")),
("<s>", tokenizer.token_to_id("<s>")),
)
tokenizer.enable_truncation(max_length=512)
让我们编码后处理序列:
tokenizer.encode("The Critique of Pure Reason.")
输出显示我们现在有 8 个令牌:
Encoding(num_tokens=8, attributes=[ids, type_ids, tokens, offsets, attention_mask, special_tokens_mask, overflowing])
如果我们想查看添加了什么,我们可以要求分词器通过运行以下单元对后处理序列进行编码:
tokenizer.encode("The Critique of Pure Reason.").tokens
输出显示已经添加了开始和结束标记,这使标记的数量达到了 8 个,包括开始和结束标记:
['<s>', 'The', 'ĠCritique', 'Ġof', 'ĠPure', 'ĠReason', '.', '</s>']
训练模型的数据现在可以进行训练了。我们现在将检查我们正在运行笔记本的机器的系统信息。
第 6 步:检查资源限制:GPU 和 CUDA
KantaiBERT 运行以最佳速度带有图形处理单元( GPU )。
我们将首先运行一个命令来查看是否存在 NVIDIA GPU 卡:
#@title Step 6: Checking Resource Constraints: GPU and NVIDIA
!nvidia-smi
输出显示卡上的信息和版本:
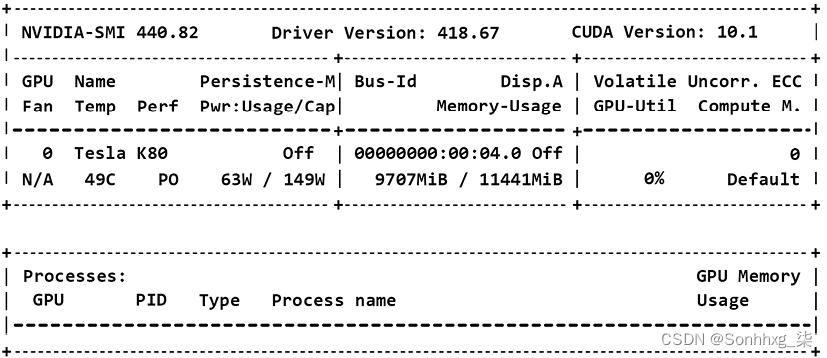 图 4.3:NVIDIA 卡上的信息
图 4.3:NVIDIA 卡上的信息
输出可能会有所不同每个 Google Colab VM 配置。
我们现在将检查以确保
PyTorch
看到 CUDA:
#@title Checking that PyTorch Sees CUDA
import torch
torch.cuda.is_available()
结果应该是
True
:
True
计算统一设备架构( CUDA ) 由 NVIDIA 开发使用其 GPU 的并行计算能力。
有关 NVIDIA GPU 和 CUDA 的更多信息,请参阅附录 II,Transformer 模型的硬件约束。
我们现在准备好定义模型的配置。
第 7 步:定义模型的配置
我们将使用相同数量的层和头来预训练 RoBERTa 型变压器模型作为 DistilBERT 变压器。该模型将词汇量设置为 52,000、12 个注意力头和 6 层:
#@title Step 7: Defining the configuration of the Model
from transformers import RobertaConfig
config = RobertaConfig(
vocab_size=52_000,
max_position_embeddings=514,
num_attention_heads=12,
num_hidden_layers=6,
type_vocab_size=1,
)
我们将在第 9 步:从头开始初始化模型中更详细地探讨配置。
让我们首先重新创建分词器在我们的模型中。
第 8 步:在转换器中重新加载标记器
我们现在准备加载我们训练有素的分词器,这是我们预训练的标记器在
RobertaTokenizer.from_pretained()
:
#@title Step 8: Re-creating the Tokenizer in Transformers
from transformers import RobertaTokenizer
tokenizer = RobertaTokenizer.from_pretrained("./KantaiBERT", max_length=512)
现在我们已经加载了我们训练有素的分词器,让我们从头开始初始化一个 RoBERTa 模型。
第 9 步:从头开始初始化模型
在本节中,我们将从头开始初始化模型并检查模型的大小。
该程序首先导入一个 RoBERTa 掩码模型用于语言建模:
#@title Step 9: Initializing a Model From Scratch
from transformers import RobertaForMaskedLM
使用步骤 7中定义的配置初始化模型:
model = RobertaForMaskedLM(config=config)
如果我们打印模型,我们可以看到它是一个有 6 层和 12 个头的 BERT 模型:
print(model)
原始 Transformer 模型的编码器的构建块具有不同的维度,如以下输出摘录所示:
RobertaForMaskedLM(
(roberta): RobertaModel(
(embeddings): RobertaEmbeddings(
(word_embeddings): Embedding(52000, 768, padding_idx=1)
(position_embeddings): Embedding(514, 768, padding_idx=1)
(token_type_embeddings): Embedding(1, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
…/…
在继续之前,请花一些时间了解配置输出的详细信息。您将从内部了解模型。
LEGO ®型积木变压器使分析变得有趣。例如,您会注意到 dropout 正则化存在于整个子层中。
现在,让我们探索参数。
探索参数
模型很小并包含 84,095,008 个参数。
我们可以检查它的大小:
print(model.num_parameters())
输出显示近似值参数数量,可能因一个变压器版本而异:
84095008
现在让我们看看参数。我们先把参数存进去
LP
,计算参数列表的长度:
#@title Exploring the Parameters
LP=list(model.parameters())
lp=len(LP)
print(lp)
输出显示存在近似
108
矩阵和向量,它们可能因一种变压器模型而异:
108
现在,让我们显示
108
矩阵和张量中的向量包含它们:
for p in range(0,lp):
print(LP[p])
输出显示所有参数,如以下输出摘录所示:
Parameter containing:
tensor([[-0.0175, -0.0210, -0.0334, ..., 0.0054, -0.0113, 0.0183],
[ 0.0020, -0.0354, -0.0221, ..., 0.0220, -0.0060, -0.0032],
[ 0.0001, -0.0002, 0.0036, ..., -0.0265, -0.0057, -0.0352],
...,
[-0.0125, -0.0418, 0.0190, ..., -0.0069, 0.0175, -0.0308],
[ 0.0072, -0.0131, 0.0069, ..., 0.0002, -0.0234, 0.0042],
[ 0.0008, 0.0281, 0.0168, ..., -0.0113, -0.0075, 0.0014]],
requires_grad=True)
花几分钟时间了解一下参数,以了解变压器是如何构建的。
参数个数是通过将模型中的所有参数相加来计算的;例如:
- 词汇 (52,000) x 维度 (768)
- 向量的大小是
1 x 768 - 发现的许多其他维度
您会注意到*d model = 768。模型中有 12 个磁头。因此,每个头的d *k的维度将是
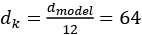
。
这再次显示了变压器积木的优化 LEGO ®概念。
我们现在将看到如何计算模型的参数数量以及如何达到 84,095,008 的数字。
如果我们将鼠标悬停在笔记本中的LP上,我们会看到一些火炬的形状张量:
 图 4.4:LP
图 4.4:LP
请注意,这些数字可能会因您使用的变压器模块的版本而异。
我们将进一步计算每个张量的参数数量。首先,程序初始化一个名为
np
(number of parameters) 的参数计数器,并遍历参数列表中的
lp
(
108
) 个元素:
#@title Counting the parameters
np=0
for p in range(0,lp):#number of tensors
参数是不同大小的矩阵和向量;例如:
- 768 x 768
- 768×1
- 768
我们可以看到有些参数是二维的,有些是一维的。
p
查看列表中的参数是否具有两个维度的一种简单方法
LP[p]
是执行以下操作:
PL2=True
try:
L2=len(LP[p][0]) #check if 2D
except:
L2=1 #not 2D but 1D
PL2=False
如果参数有两个维度,它的第二个维度将是
L2>0
和
PL2=True (2 dimensions=True)
。如果参数只有一个维度,它的第二个维度将是
L2=1
和
PL2=False (2 dimensions=False)
。
L1
是参数的第一维的大小。
L3
是由以下定义的参数的大小:
L1=len(LP[p])
L3=L1*L2
我们现在可以在循环的每个步骤中添加参数:
np+=L3 # number of parameters per tensor
我们将获得参数的总和,但我们还想确切了解如何计算变压器模型的参数数量:
if PL2==True:
print(p,L1,L2,L3) # displaying the sizes of the parameters
if PL2==False:
print(p,L1,L3) # displaying the sizes of the parameters
print(np) # total number of parameters
请注意,如果一个参数只有一个维度
PL2=False
,那么我们只显示第一个维度。
输出是如何计算模型中所有张量的参数数量的列表,如以下摘录所示:
0 52000 768 39936000
1 514 768 394752
2 1 768 768
3 768 768
4 768 768
5 768 768 589824
6 768 768
7 768 768 589824
8 768 768
9 768 768 589824
10 768 768
RoBERTa 模型的参数总数显示在列表末尾:
84,095,008
参数的数量可能会因使用的库版本而异。
我们现在准确地知道参数的数量在变压器模型中代表什么。花几分钟回去看看配置的输出,参数的内容,大小的参数。此时,你将有一个精确的心理表征模型的构建块。
该程序现在构建数据集。
第 10 步:构建数据集
该程序现在将加载数据集逐行生成批次样本
block_size=128
限制示例长度的训练:
#@title Step 10: Building the Dataset
%%time
from transformers import LineByLineTextDataset
dataset = LineByLineTextDataset(
tokenizer=tokenizer,
file_path="./kant.txt",
block_size=128,
)
输出显示 Hugging Face 投入了大量资源来优化处理数据所需的时间:
CPU times: user 8.48 s, sys: 234 ms, total: 8.71 s
Wall time: 3.88 s
挂墙时间(处理器处于活动状态的实际时间)得到了优化。
该程序现在将定义一个数据整理器来创建一个用于反向传播的对象。
第 11 步:定义数据整理器
我们需要运行数据收集器在初始化训练器之前。数据收集者将取样从数据集中将它们整理成批次。结果是类似字典的对象。
我们正在通过设置为 MLM 准备一个批处理示例过程
mlm=True
。
我们还设置了要训练的掩码标记的数量
mlm_probability=0.15
。这将确定在预训练过程中被屏蔽的令牌的百分比。
我们现在使用我们的标记器进行初始化
data_collator
,激活 MLM,并将掩码标记的比例设置为
0.15
:
#@title Step 11: Defining a Data Collator
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=True, mlm_probability=0.15
)
我们现在准备初始化训练器。
第 12 步:初始化训练器
前面的步骤已经准备好了初始化训练器所需的信息。数据集已被标记并加载。我们的模型已经建立。数据整理器已创建。
程序现在可以初始化训练器。出于教育目的,该程序会快速训练模型。epoch 的数量限制为一个。GPU 派上用场,因为我们可以共享批次和多处理训练任务:
#@title Step 12: Initializing the Trainer
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="./KantaiBERT",
overwrite_output_dir=True,
num_train_epochs=1,
per_device_train_batch_size=64,
save_steps=10_000,
save_total_limit=2,
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=dataset,
)
该模型现在已准备好进行培训。
第 13 步:预训练模型
一切都准备好了。教练员用一行代码启动:
#@title Step 13: Pre-training the Model
%%time
trainer.train()
输出实时显示训练过程,显示
loss
、
learning rate
、
epoch
和步骤:
Epoch: 100%
1/1 [17:59<00:00, 1079.91s/it]
Iteration: 100%
2672/2672 [17:59<00:00, 2.47it/s]
{"loss": 5.6455852394104005, "learning_rate": 4.06437125748503e-05, "epoch": 0.18712574850299402, "step": 500}
{"loss": 4.940259679794312, "learning_rate": 3.12874251497006e-05, "epoch": 0.37425149700598803, "step": 1000}
{"loss": 4.639936000347137, "learning_rate": 2.1931137724550898e-05, "epoch": 0.561377245508982, "step": 1500}
{"loss": 4.361462069988251, "learning_rate": 1.2574850299401197e-05, "epoch": 0.7485029940119761, "step": 2000}
{"loss": 4.228510192394257, "learning_rate": 3.218562874251497e-06, "epoch": 0.9356287425149701, "step": 2500}
CPU times: user 11min 36s, sys: 6min 25s, total: 18min 2s
Wall time: 17min 59s
TrainOutput(global_step=2672, training_loss=4.7226536670130885)
该模型已被训练。是时候拯救我们的工作了。
第 14 步:将最终模型(+tokenizer + config)保存到磁盘
我们现在将保存型号及配置:
#@title Step 14: Saving the Final Model(+tokenizer + config) to disk
trainer.save_model("./KantaiBERT")
单击文件管理器中的刷新,文件应出现:
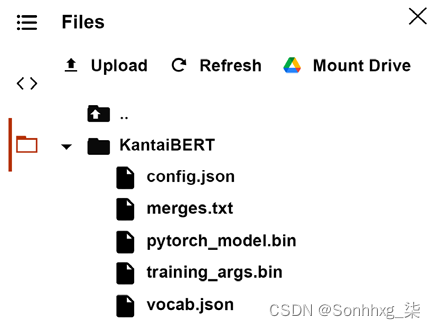
图 4.5:Colab 文件管理器
config.json
,
pytorh_model.bin
, 并且
training_args.bin
现在应该出现在文件管理器中。
merges.txt
并
vocab.json
包含数据集的预训练标记化。
我们从头开始建立了一个模型。让我们导入管道以使用我们的预训练模型和标记器执行语言建模任务。
第 15 步:使用 FillMaskPipeline 进行语言建模
我们现在将导入语言建模
fill-mask
任务。我们将使用我们经过训练的模型和经过训练的分词器来执行 MLM:
#@title Step 15: Language Modeling with the FillMaskPipeline
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="./KantaiBERT",
tokenizer="./KantaiBERT"
)
我们现在可以要求我们的模型像伊曼纽尔康德一样思考:
fill_mask("Human thinking involves human <mask>.")
每次运行后输出可能会发生变化,因为我们使用有限的数据量从头开始预训练模型。但是,在此运行中获得的输出很有趣,因为它引入了概念语言建模:
[{'score': 0.022831793874502182,
'sequence': '<s> Human thinking involves human reason.</s>',
'token': 393},
{'score': 0.011635891161859035,
'sequence': '<s> Human thinking involves human object.</s>',
'token': 394},
{'score': 0.010641072876751423,
'sequence': '<s> Human thinking involves human priori.</s>',
'token': 575},
{'score': 0.009517930448055267,
'sequence': '<s> Human thinking involves human conception.</s>',
'token': 418},
{'score': 0.00923212617635727,
'sequence': '<s> Human thinking involves human experience.</s>',
'token': 531}]
每次运行和 Hugging Face 更新其模型时,预测可能会有所不同。
但是,经常会出现以下输出:
Human thinking involves human reason
这里的目标是了解如何训练变压器模型。我们可以看到可以做出有趣的类人预测。
这些结果是实验性的并且在训练过程中会发生变化。每次我们再次训练模型时,它们都会改变。
该模型需要来自其他启蒙时代思想家的更多数据。
然而,这个模型的目标是表明我们可以创建数据集来训练一个特定类型的复杂语言建模任务的转换器。
多亏了变形金刚,我们才刚刚进入人工智能新时代!
下一步
你已经从零开始训练了一个变形金刚。花一些时间想象一下您可以在个人或公司环境中做什么。您可以为特定任务创建数据集并从头开始对其进行训练。使用您感兴趣的领域或公司项目来试验变压器构造套件的迷人世界!
一旦你制作了一个你喜欢的模型,你就可以与拥抱脸社区分享它。您的模型将出现在拥抱脸模型页面上:https ://huggingface.co/models
你可以上传你的模型在几个步骤中使用此页面上描述的说明:https ://huggingface.co/transformers/model_sharing.html
您还可以下载 Hugging Face 社区共享的模型,为您的个人和专业项目获取新想法。
概括
在本章中,我们
KantaiBERT
使用 Hugging Face 提供的构建块从头开始构建了一个类似于 RoBERTa 的模型转换器。
我们首先加载与伊曼纽尔康德作品相关的特定主题的自定义数据集。您可以加载现有数据集或创建自己的数据集,具体取决于您的目标。我们看到,使用自定义数据集可以深入了解 Transformer 模型的思维方式。然而,这种实验方法有其局限性。训练一个超出教育目的的模型需要更大的数据集。
KantaiBERT 项目用于在
kant.txt
数据集上训练分词器。训练的
merges.txt
和
vocab.json
文件被保存了。使用我们预训练的文件重新创建了标记器。KantaiBERT 构建了自定义数据集并定义了一个数据整理器来处理训练批次以进行反向传播。初始化训练器,我们详细探索了 RoBERTa 模型的参数。该模型被训练并保存。
最后,为下游语言建模任务加载保存的模型。目标是使用伊曼纽尔康德的逻辑来填充面具。
现在,您可以在现有或自定义的数据集上进行试验,看看您会得到什么结果。您可以与 Hugging Face 社区分享您的模型。Transformer 是数据驱动的。您可以利用它来发现使用变压器的新方法。
您现在已准备好学习如何使用无需预训练或微调的 API 运行即用型转换器引擎。第 7 章,使用 GPT-3 引擎的超人变形金刚的崛起,将带您进入 AI 的未来。有了本章和前几章的知识,你就准备好了!
在下一章,使用 Transformer 的下游 NLP 任务中,我们将继续准备实现 Transformer。
版权归原作者 Sonhhxg_柒 所有, 如有侵权,请联系我们删除。