
11.3 具体实现
本项目将使用TensorFlow.js设计一个网页,在网页中有一篇文章。然后利用SQuAD2.0数据集,和神经模型MobileBERT学习文章中的知识,然后在表单中提问和文章内容有关的问题,系统会自动回答这个问题。
11.3.1 编写HTML文件
编写HTML文件index.html,在上方文本框中显示介绍尼古拉·特斯拉的一篇文章信息,在下方文本框输入一个和文章内容相关的问题,单击“search”按钮后会自动输出显示这个问题的答案。文件index.html的具体实现代码如下:
<!doctype html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<script src="./index.js"></script>
</head>
<body>
<div>
<h3>Context (you can paste your own content in the text area)</h3>
<textarea id='context' rows="30" cols="120">Nikola Tesla (/ˈtɛslə/;[2] Serbo-Croatian: [nǐkola têsla]; Serbian Cyrillic: Никола Тесла;[a] 10
July 1856 – 7 January 1943) was a Serbian-American[4][5][6] inventor, electrical engineer, mechanical engineer,
and futurist who is best known for his contributions to the design of the modern alternating current (AC)
electricity supply system.[7] <br/>
Born and raised in the Austrian Empire, Tesla studied engineering and physics in the 1870s without receiving a
degree, and gained practical experience in the early 1880s working in telephony and at Continental Edison in the
new electric power industry. He emigrated in 1884 to the United States, where he would become a naturalized
citizen. He worked for a short time at the Edison Machine Works in New York City before he struck out on his own.
With the help of partners to finance and market his ideas, Tesla set up laboratories and companies in New York to
develop a range of electrical and mechanical devices. His alternating current (AC) induction motor and related
polyphase AC patents, licensed by Westinghouse Electric in 1888, earned him a considerable amount of money and
became the cornerstone of the polyphase system which that company would eventually market.<br/>
Attempting to develop inventions he could patent and market, Tesla conducted a range of experiments with
mechanical oscillators/generators, electrical discharge tubes, and early X-ray imaging. He also built a
wireless-controlled boat, one of the first ever exhibited. Tesla became well known as an inventor and would
demonstrate his achievements to celebrities and wealthy patrons at his lab, and was noted for his showmanship at
public lectures. Throughout the 1890s, Tesla pursued his ideas for wireless lighting and worldwide wireless
electric power distribution in his high-voltage, high-frequency power experiments in New York and Colorado
Springs. In 1893, he made pronouncements on the possibility of wireless communication with his devices. Tesla
tried to put these ideas to practical use in his unfinished Wardenclyffe Tower project, an intercontinental
wireless communication and power transmitter, but ran out of funding before he could complete it.[8]<br/>
After Wardenclyffe, Tesla experimented with a series of inventions in the 1910s and 1920s with varying degrees of
success. Having spent most of his money, Tesla lived in a series of New York hotels, leaving behind unpaid bills.
He died in New York City in January 1943.[9] Tesla's work fell into relative obscurity following his death, until
1960, when the General Conference on Weights and Measures named the SI unit of magnetic flux density the tesla in
his honor.[10] There has been a resurgence in popular interest in Tesla since the 1990s.[11]</textarea>
<h3>Question</h3>
<input type=text id="question"> <button id="search">Search</button>
<h3>Answers</h3>
<div id='answer'></div>
</div>
</body>
</html>
11.3.2 脚本处理
当用户单击“search”按钮后会调用脚本文件index.js,此文件的功能是获取用户在文本框中输入的问题,然后调用神经网络模型回答这个问题。文件index.js的具体实现代码如下所示。
import * as qna from '@tensorflow-models/qna';
import '@tensorflow/tfjs-core';
import '@tensorflow/tfjs-backend-cpu';
import '@tensorflow/tfjs-backend-webgl';
let modelPromise = {};
let search;
let input;
let contextDiv;
let answerDiv;
const process = async () => {
const model = await modelPromise;
const answers = await model.findAnswers(input.value, contextDiv.value);
console.log(answers);
answerDiv.innerHTML =
answers.map(answer => answer.text + ' (score =' + answer.score + ')')
.join('<br>');
};
window.onload = () => {
modelPromise = qna.load();
input = document.getElementById('question');
search = document.getElementById('search');
contextDiv = document.getElementById('context');
answerDiv = document.getElementById('answer');
search.onclick = process;
input.addEventListener('keyup', async (event) => {
if (event.key === 'Enter') {
process();
}
});
};
在上述代码中,使用addEventListener监听用户输入的问题,然后调用函数model.findAnswers()回答问题。
11.3.3 加载训练模型
在文件question_and_answer.ts中加载神经网络模型MobileBERT,具体实现流程如下:
(1)首先设置输入参数和最大扫描长度,代码如下:
const MODEL_URL = 'https://tfhub.dev/tensorflow/tfjs-model/mobilebert/1';
const INPUT_SIZE = 384;
const MAX_ANSWER_LEN = 32;
const MAX_QUERY_LEN = 64;
const MAX_SEQ_LEN = 384;
const PREDICT_ANSWER_NUM = 5;
const OUTPUT_OFFSET = 1;
const NO_ANSWER_THRESHOLD = 4.3980759382247925;
在上述代码中,NO_ANSWER_THRESHOLD是确定问题是否与上下文无关的阈值,该值是由训练SQuAD2.02.0数据集的数据生成的。
(2)创建加载模型MobileBert的接口ModelConfig,代码如下:
export interface ModelConfig {
/**
*指定模型的自定义url的可选字符串,这对无法访问托管在上的模型的地区/国家/地区很有用
.
*/
modelUrl: string;
/**
* 是否是来自tfhub的URL
*/
fromTFHub?: boolean;
}
11.3.4 查询处理
编写函数process()实现检索处理,获取用户在表单中输入的问题,然后检索文章中的所有内容。为了确保问题的完整性,如果用户没有在问题最后输入问号,会自动添加一个问号。代码如下:
private process(
query: string, context: string, maxQueryLen: number, maxSeqLen: number,
docStride = 128): Feature[] {
// 始终在查询末尾添加问号.
query = query.replace(/\?/g, '');
query = query.trim();
query = query + '?';
const queryTokens = this.tokenizer.tokenize(query);
if (queryTokens.length > maxQueryLen) {
throw new Error(
`The length of question token exceeds the limit (${maxQueryLen}).`);
}
const origTokens = this.tokenizer.processInput(context.trim());
const tokenToOrigIndex: number[] = [];
const allDocTokens: number[] = [];
for (let i = 0; i < origTokens.length; i++) {
const token = origTokens[i].text;
const subTokens = this.tokenizer.tokenize(token);
for (let j = 0; j < subTokens.length; j++) {
const subToken = subTokens[j];
tokenToOrigIndex.push(i);
allDocTokens.push(subToken);
}
}
// 3个选项: [CLS], [SEP] and [SEP]
const maxContextLen = maxSeqLen - queryTokens.length - 3;
// 我们可以有超过最大序列长度的文档。为了解决这个问题,我们采用了滑动窗口的方法,
// 在这种方法中,我们以“doc\u-stride”的步幅将大块的数据移动到最大长度。
const docSpans: Array<{start: number, length: number}> = [];
let startOffset = 0;
while (startOffset < allDocTokens.length) {
let length = allDocTokens.length - startOffset;
if (length > maxContextLen) {
length = maxContextLen;
}
docSpans.push({start: startOffset, length});
if (startOffset + length === allDocTokens.length) {
break;
}
startOffset += Math.min(length, docStride);
}
const features = docSpans.map(docSpan => {
const tokens = [];
const segmentIds = [];
const tokenToOrigMap: {[index: number]: number} = {};
tokens.push(CLS_INDEX);
segmentIds.push(0);
for (let i = 0; i < queryTokens.length; i++) {
const queryToken = queryTokens[i];
tokens.push(queryToken);
segmentIds.push(0);
}
tokens.push(SEP_INDEX);
segmentIds.push(0);
for (let i = 0; i < docSpan.length; i++) {
const splitTokenIndex = i + docSpan.start;
const docToken = allDocTokens[splitTokenIndex];
tokens.push(docToken);
segmentIds.push(1);
tokenToOrigMap[tokens.length] = tokenToOrigIndex[splitTokenIndex];
}
tokens.push(SEP_INDEX);
segmentIds.push(1);
const inputIds = tokens;
const inputMask = inputIds.map(id => 1);
while ((inputIds.length < maxSeqLen)) {
inputIds.push(0);
inputMask.push(0);
segmentIds.push(0);
}
return {inputIds, inputMask, segmentIds, origTokens, tokenToOrigMap};
});
return features;
}
11.3.5 文章处理
(1)编写函数cleanText(),功能是删除文章中文本中的无效字符和空白。代码如下:
tokenize(text: string): number[] {
let outputTokens: number[] = [];
const words = this.processInput(text);
words.forEach(word => {
if (word.text !== CLS_TOKEN && word.text !== SEP_TOKEN) {
word.text = `${SEPERATOR}${word.text.normalize(NFKC_TOKEN)}`;
}
});
for (let i = 0; i < words.length; i++) {
const chars = [];
for (const symbol of words[i].text) {
chars.push(symbol);
}
let isUnknown = false;
let start = 0;
const subTokens: number[] = [];
const charsLength = chars.length;
while (start < charsLength) {
let end = charsLength;
let currIndex;
while (start < end) {
const substr = chars.slice(start, end).join('');
const match = this.trie.find(substr);
if (match != null && match.end != null) {
currIndex = match.getWord()[2];
break;
}
end = end - 1;
}
if (currIndex == null) {
isUnknown = true;
break;
}
subTokens.push(currIndex);
start = end;
}
if (isUnknown) {
outputTokens.push(UNK_INDEX);
} else {
outputTokens = outputTokens.concat(subTokens);
}
}
return outputTokens;
}
}
tokenize(text: string): number[] {
let outputTokens: number[] = [];
const words = this.processInput(text);
words.forEach(word => {
if (word.text !== CLS_TOKEN && word.text !== SEP_TOKEN) {
word.text = `${SEPERATOR}${word.text.normalize(NFKC_TOKEN)}`;
}
});
for (let i = 0; i < words.length; i++) {
const chars = [];
for (const symbol of words[i].text) {
chars.push(symbol);
}
let isUnknown = false;
let start = 0;
const subTokens: number[] = [];
const charsLength = chars.length;
while (start < charsLength) {
let end = charsLength;
let currIndex;
while (start < end) {
const substr = chars.slice(start, end).join('');
const match = this.trie.find(substr);
if (match != null && match.end != null) {
currIndex = match.getWord()[2];
break;
}
end = end - 1;
}
if (currIndex == null) {
isUnknown = true;
break;
}
subTokens.push(currIndex);
start = end;
}
if (isUnknown) {
outputTokens.push(UNK_INDEX);
} else {
outputTokens = outputTokens.concat(subTokens);
}
}
return outputTokens;
}
}
(3)编写函数tokenize(),功能是为指定的词汇库生成标记。本函数使用谷歌提供的全词屏蔽模型实现,这种新技术也被称为全词掩码。在这种情况下,总是一次屏蔽与一个单词对应的所有标记。对应Python实现请参阅谷歌提供的开源代码:https://github.com/google-research/bert/blob/88a817c37f788702a363ff935fd173b6dc6ac0d6/tokenization.py。
tokenize(text: string): number[] {
let outputTokens: number[] = [];
const words = this.processInput(text);
words.forEach(word => {
if (word.text !== CLS_TOKEN && word.text !== SEP_TOKEN) {
word.text = `${SEPERATOR}${word.text.normalize(NFKC_TOKEN)}`;
}
});
for (let i = 0; i < words.length; i++) {
const chars = [];
for (const symbol of words[i].text) {
chars.push(symbol);
}
let isUnknown = false;
let start = 0;
const subTokens: number[] = [];
const charsLength = chars.length;
while (start < charsLength) {
let end = charsLength;
let currIndex;
while (start < end) {
const substr = chars.slice(start, end).join('');
const match = this.trie.find(substr);
if (match != null && match.end != null) {
currIndex = match.getWord()[2];
break;
}
end = end - 1;
}
if (currIndex == null) {
isUnknown = true;
break;
}
subTokens.push(currIndex);
start = end;
}
if (isUnknown) {
outputTokens.push(UNK_INDEX);
} else {
outputTokens = outputTokens.concat(subTokens);
}
}
return outputTokens;
}
}
11.3.6 加载处理
编写函数load()加载数据和网页信息,首先使用函数loadGraphModel()加载模型文件,然后使用函数execute()执行根据用户输入的操作。代码如下:
async load() {
this.model = await tfconv.loadGraphModel(
this.modelConfig.modelUrl, {fromTFHub: this.modelConfig.fromTFHub});
//预热后端
const batchSize = 1;
const inputIds = tf.ones([batchSize, INPUT_SIZE], 'int32');
const segmentIds = tf.ones([1, INPUT_SIZE], 'int32');
const inputMask = tf.ones([1, INPUT_SIZE], 'int32');
this.model.execute({
input_ids: inputIds,
segment_ids: segmentIds,
input_mask: inputMask,
global_step: tf.scalar(1, 'int32')
});
this.tokenizer = await loadTokenizer();
}
11.3.7 寻找答案
编写函数model.findAnswers(),功能是根据用户在表单中输入的问题寻找对应的答案。此函数包含如下3个参数:
- question:要找答案的问题。
- context:从这里面查找答案。
- 返回值是一个数组,每个选项是一种可能的答案。
函数model.findAnswers()的具体实现代码如下所示。
async findAnswers(question: string, context: string): Promise<Answer[]> {
if (question == null || context == null) {
throw new Error(
'The input to findAnswers call is null, ' +
'please pass a string as input.');
}
const features =
this.process(question, context, MAX_QUERY_LEN, MAX_SEQ_LEN);
const inputIdArray = features.map(f => f.inputIds);
const segmentIdArray = features.map(f => f.segmentIds);
const inputMaskArray = features.map(f => f.inputMask);
const globalStep = tf.scalar(1, 'int32');
const batchSize = features.length;
const result = tf.tidy(() => {
const inputIds =
tf.tensor2d(inputIdArray, [batchSize, INPUT_SIZE], 'int32');
const segmentIds =
tf.tensor2d(segmentIdArray, [batchSize, INPUT_SIZE], 'int32');
const inputMask =
tf.tensor2d(inputMaskArray, [batchSize, INPUT_SIZE], 'int32');
return this.model.execute(
{
input_ids: inputIds,
segment_ids: segmentIds,
input_mask: inputMask,
global_step: globalStep
},
['start_logits', 'end_logits']) as [tf.Tensor2D, tf.Tensor2D];
});
const logits = await Promise.all([result[0].array(), result[1].array()]);
//处理所有中间张量
globalStep.dispose();
result[0].dispose();
result[1].dispose();
const answers = [];
for (let i = 0; i < batchSize; i++) {
answers.push(this.getBestAnswers(
logits[0][i], logits[1][i], features[i].origTokens,
features[i].tokenToOrigMap, context, i));
}
return answers.reduce((flatten, array) => flatten.concat(array), [])
.sort((logitA, logitB) => logitB.score - logitA.score)
.slice(0, PREDICT_ANSWER_NUM);
}
11.3.8 提取最佳答案
(1)通过如下代码从logits数组和输入中查找最佳的N个答案和logits。其中参数startologits表示开始索引答案,参数endLogits表示结束答案索引,参数origTokens表示通道的原始标记,参数tokenToOrigMap表示令牌到索引的映射。
QuestionAndAnswerImpl.prototype.getBestAnswers = function (startLogits, endLogits, origTokens, tokenToOrigMap, context, docIndex) {
var _a;
if (docIndex === void 0) { docIndex = 0; }
//模型使用封闭区间[开始,结束]作为索引
var startIndexes = this.getBestIndex(startLogits);
var endIndexes = this.getBestIndex(endLogits);
var origResults = [];
startIndexes.forEach(function (start) {
endIndexes.forEach(function (end) {
if (tokenToOrigMap[start] && tokenToOrigMap[end] && end >= start) {
var length_2 = end - start + 1;
if (length_2 < MAX_ANSWER_LEN) {
origResults.push({ start: start, end: end, score: startLogits[start] + endLogits[end] });
}
}
});
});
origResults.sort(function (a, b) { return b.score - a.score; });
var answers = [];
for (var i = 0; i < origResults.length; i++) {
if (i >= PREDICT_ANSWER_NUM ||
origResults[i].score < NO_ANSWER_THRESHOLD) {
break;
}
var convertedText = '';
var startIndex = 0;
var endIndex = 0;
if (origResults[i].start > 0) {
_a = this.convertBack(origTokens, tokenToOrigMap, origResults[i].start, origResults[i].end, context), convertedText = _a[0], startIndex = _a[1], endIndex = _a[2];
}
else {
convertedText = '';
}
answers.push({
text: convertedText,
score: origResults[i].score,
startIndex: startIndex,
endIndex: endIndex
});
}
return answers;
};
(2)编写函数getBestIndex(),功能是通过神经网络模型检索文章后,会找到多个答案,根据比率高低选出其中的5个最佳答案。代码如下:
getBestIndex(logits: number[]): number[] {
const tmpList = [];
for (let i = 0; i < MAX_SEQ_LEN; i++) {
tmpList.push([i, i, logits[i]]);
}
tmpList.sort((a, b) => b[2] - a[2]);
const indexes = [];
for (let i = 0; i < PREDICT_ANSWER_NUM; i++) {
indexes.push(tmpList[i][0]);
}
return indexes;
}
11.3.9 将答案转换回为文本
接下来使用convertBack()将问题的答案转换回原始文本形式,代码如下:
convertBack(
origTokens: Token[], tokenToOrigMap: {[key: string]: number},
start: number, end: number, context: string): [string, number, number] {
// 移位索引是:logits + offset.
const shiftedStart = start + OUTPUT_OFFSET;
const shiftedEnd = end + OUTPUT_OFFSET;
const startIndex = tokenToOrigMap[shiftedStart];
const endIndex = tokenToOrigMap[shiftedEnd];
const startCharIndex = origTokens[startIndex].index;
const endCharIndex = endIndex < origTokens.length - 1 ?
origTokens[endIndex + 1].index - 1 :
origTokens[endIndex].index + origTokens[endIndex].text.length;
return [
context.slice(startCharIndex, endCharIndex + 1).trim(), startCharIndex,
endCharIndex
];
}
}
11.4 调试运行
到此为止,整个实例介绍完毕,接下来开始运行调试本项目。本项目基于Yarn 和Npm进行架构调试,其中Yarn对代码来说是一个包管理器,可以让我们使用并分享 全世界开发者的(例如 JavaScript)代码。运行调试本项目的基本流程如下:
(1)安装Node.js,然后打开Node.js命令行界面,输入如下命令来到项目的“qna”目录:
cd qna
(2)输入如下命令在“qna”目录中安装Npm:
npm install
(3)输入如下命令来到子目录“demo”:
cd qna/demo
(4)输入如下命令安装本项目需要的依赖项:
yarn
(5)输入如下命令编译依赖项:
yarn build-deps
(6)输入如下命令启动测试服务器,并监视文件的更改变化情况。
yarn watch
到目前为止,所有的编译运行工作全部完成,在笔者电脑中的整个编译过程如下:
E:\123\lv\TensorFlow\daima\tfjs-models-master\qna>cd demo
E:\123\lv\TensorFlow\daima\tfjs-models-master\qna\demo>yarn
yarn install v1.22.10
[1/5] Validating package.json...
[2/5] Resolving packages...
warning Resolution field "[email protected]" is incompatible with requested version "is-svg@^3.0.0"
success Already up-to-date.
Done in 5.09s.
E:\123\lv\TensorFlow\daima\tfjs-models-master\qna\demo>yarn build-deps
yarn run v1.22.10
$ yarn build-qna
$ cd .. && yarn && yarn build-npm
warning package-lock.json found. Your project contains lock files generated by tools other than Yarn. It is advised not to mix package managers in order to avoid resolution i
nconsistencies caused by unsynchronized lock files. To clear this warning, remove package-lock.json.
[1/4] Resolving packages...
success Already up-to-date.
$ yarn build && rollup -c
$ rimraf dist && tsc
src/index.ts → dist/qna.js...
created dist/qna.js in 1m 18.9s
src/index.ts → dist/qna.min.js...
created dist/qna.min.js in 1m 1.3s
src/index.ts → dist/qna.esm.js...
created dist/qna.esm.js in 45.8s
Done in 251.88s.
E:\123\lv\TensorFlow\daima\tfjs-models-master\qna\demo>yarn watch
yarn run v1.22.10
$ cross-env NODE_ENV=development parcel index.html --no-hmr --open
√ Built in 1.81s.
运行上述命令成功后自动打开一个网页http://localhost:1234/,在网页显示本项目的执行效果。执行后在表单中输入一个问题,这个问题的答案可以在表单上方的文章中找到。例如输入“Where was Tesla born”,然后单击“search”按钮,会自动输出显示这个问题的答案。如图11-2所示。
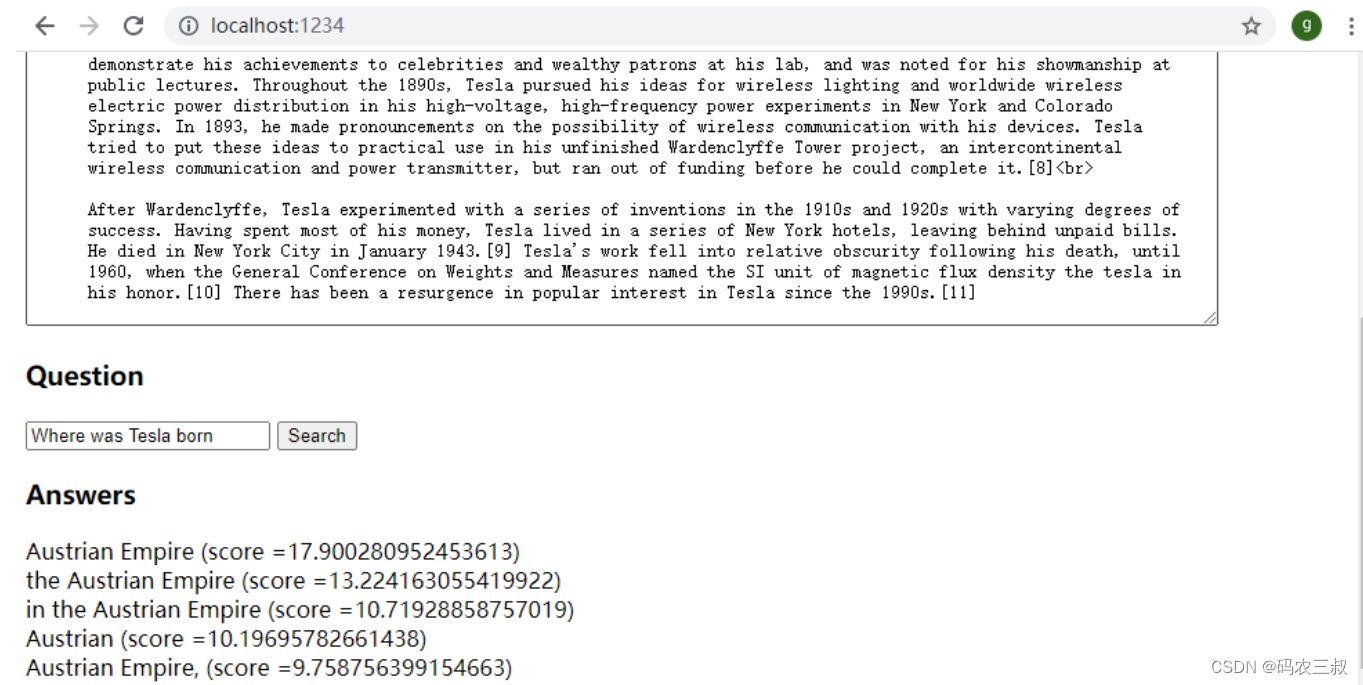
图11-2 执行效果
版权归原作者 码农三叔 所有, 如有侵权,请联系我们删除。