
KernelSHAP 和 TreeSHAP 都用于近似 Shapley 值。TreeSHAP 的速度很快,但是它只能用于基于树的算法,如随机森林和 xgboost。而KernelSHAP 与模型无关。这意味着它可以与任何机器学习算法一起使用。我们将比较这两种近似方法。
本文中的实验,将展示 TreeSHAP 实际上有多快。另外还探索树算法的参数如何影响时间复杂度,这些包括树的数量、深度和特征的数量等。在使用 TreeSHAP 进行数据探索时,这些知识非常有用。最后我们还将讨论其他因素(如特性依赖关系)的一些影响。

本文假设你了解 SHAP,可以参考我们以前发布的其他文章。
每样本的时间
对于第一个实验,我们看看这些方法计算 SHAP 值需要多少时间。我们不会详细介绍用于代码,因为本文的最后会提供完整代码的GitHub 地址。从模拟回归数据开始。这有 10000 个样本、10 个特征和 1 个连续目标变量。使用这些数据,我们训练了一个随机森林,该模型有 100 棵树,最大深度为 4。
现在可以使用这个模型来计算 SHAP 值。同时使用 KernelSHAP 和 TreeSHAP 方法,对于每种方法计算 10、100、1000、2000、5000 和 10000 个 SHAP 值。记录每个值计算所花费的时间,并且我重复此过程 3 次,然后将平均值作为最终时间。
可以在图 1 中看到结果。TreeSHAP 明显更快。对于 10,000 个 SHAP 值,该方法耗时 1.44 秒。相比之下,KernelSHAP 耗时 13 分 40.56 秒。这是 570 倍的时间。当然这些计算的速度将取决于设备,但差异不会太大。
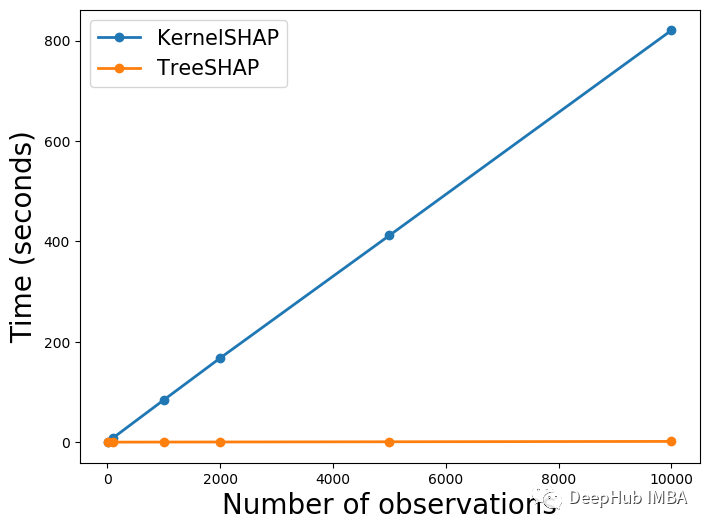
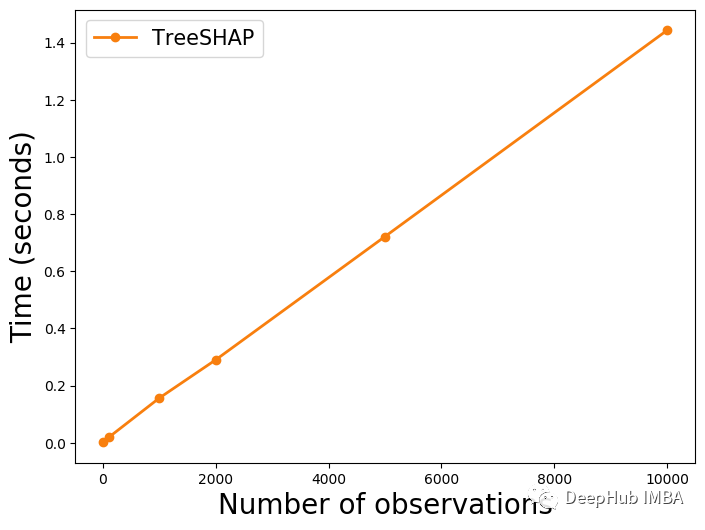
上面的 TreeSHAP 线看起来很平。这是因为 KernelSHAP的值太大了。在下图 2 中,我们单独绘制 TreeSHAP 。可以看到它也随着观察次数的增加而线性增加。这告诉我们每个 SHAP 值都需要相似的时间来计算。我们将在下一节探讨原因。
时间复杂度
两种方法的时间复杂度如下。这也是树算法中计算特征的SHAP值时的复杂度。T 是个体树的数量。L 是每棵树中的最大叶子数。D 是每棵树的最大深度。M 是每棵树中的最大特征数。对于这些方法,这些参数将以不同的方式影响逼近时间。
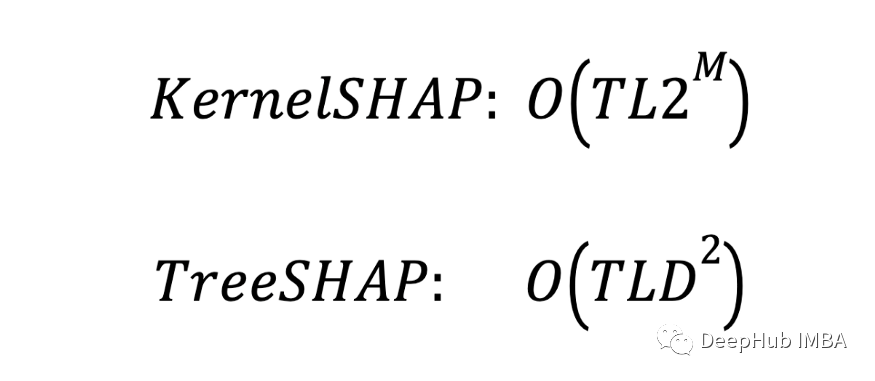
TreeSHAP 的复杂性只受深度 (D) 的影响。而KernelSHAP 受特征数量 (M) 的影响。不同之处在于 KernelSHAP 复杂度是指数 w.r.t M 而 TreeSHAP 是二次 w.r.t D。因为树深度(D=4)比特征(M = 10)小的多,所以KernelSHAP 会慢很多。
这是每个 SHAP 值的时间复杂度,一般情况下每个值都需要相似的时间来计算,所以我们看到时间和观察次数之间存在线性关系。现在将探讨时间与其他参数 T、L、D 和 M 之间的关系。然后将讨论结果对模型验证和数据探索的意义。
树的数量(T)
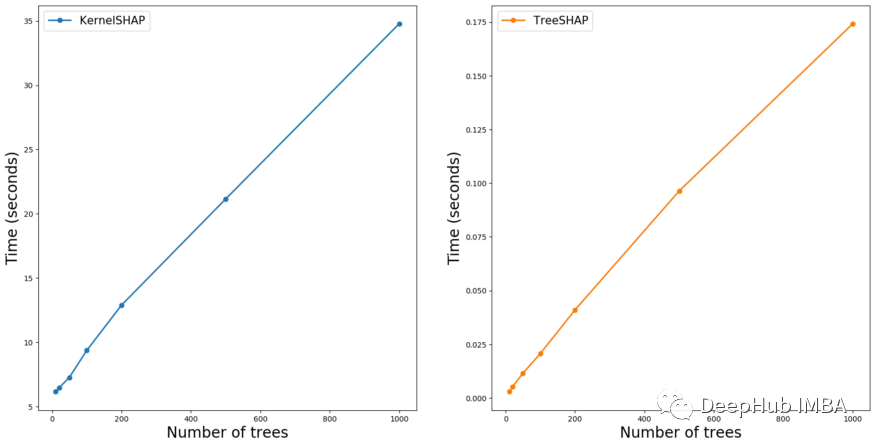
对于这两种方法,复杂度都是树的数量(T)的线性w.r.t.。为了验证这个参数会以类似的方式影响逼近时间。我们通过增加树的数量来训练不同的模型,使用每个模型计算100个SHAP值。
可以在图3中看到结果。对于这两种方法,时间随树的数量线性增加。这就是我们在查看时间复杂度时所期望的结果。这告诉我们,通过限制树的数量,我们可以减少计算SHAP值的时间。
特征数量(M)
只有KernelSHAP受到特征数量(M)的影响,这次我们在不同数量的特征上训练模型。而其他参数(T、L、D)保持不变。在下图4中,可以看到随着m的增加,KernelSHAP的时间呈指数增长。相比之下,TreeSHAP的时间受影响较小。
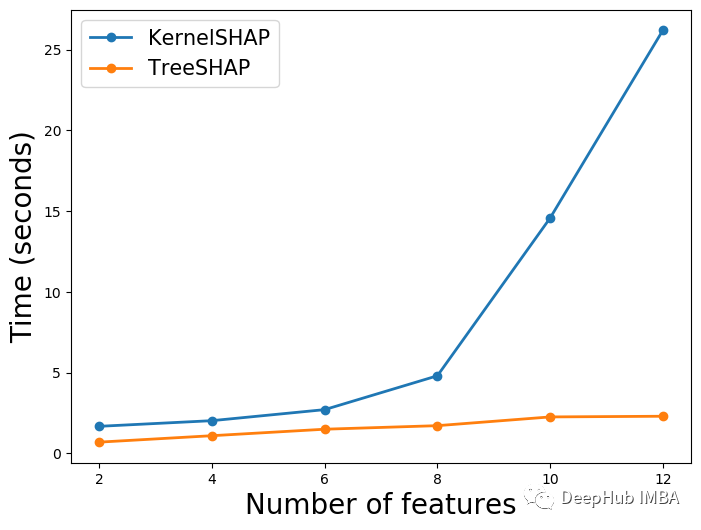
TreeSHAP的时间在逐渐增加(虽然不明显),因为我们看到复杂度与m无关。这是计算单个特征的SHAP值时的复杂度。随着M的增加,我们需要为每次观测计算更多的SHAP值,所以这部分增加应该是合理的。
树的深度(D)
最后,我们改变树的深度。我们将森林中每棵树的深度都设置成最大深度。在下图5中,可以看到当我们增加深度时使用TreeSHAP的时间大大增加了。在某些情况下,TreeSHAP的计算成本甚至比KernelSHAP高。因为TreeSHAP复杂度是D的函数时,这点也是毫无疑问的。
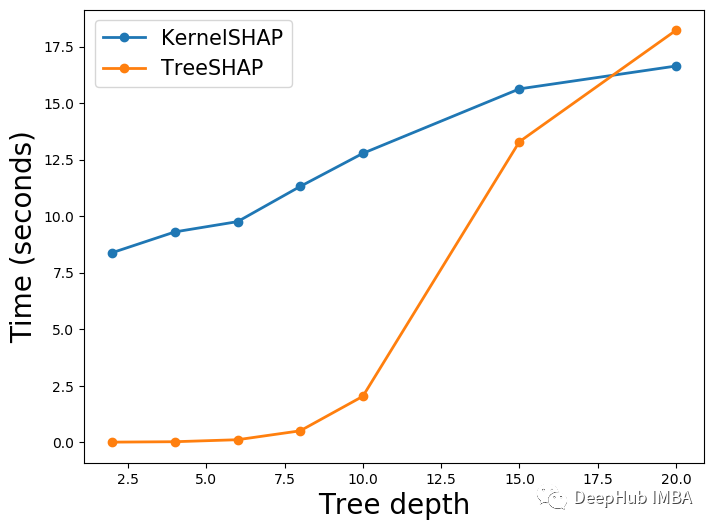
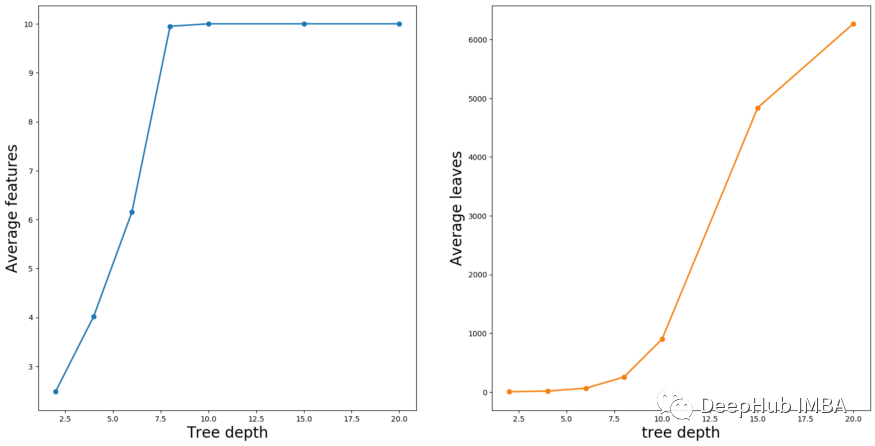
为什么KernelSHAP时间也会增加?这是因为特征(M)和叶(L)的数量是根据树的深度而变化的。随着深度的增加,会有更多的分裂,所以我们会有更多的叶子。更多的分叉也意味着树可以使用更多的特征。可以在下图6中看到这一点。在这里,我们计算了森林中所有树木的特征和叶子的平均数量。
模型验证和数据探索的建议
通过改变深度,我们看到在某些情况下 TreeSHAP 的计算成本更高。但是这些情况不太可能发生。只有当我们的树深度为 20 时才会发生这种情况。使用这么深的树并不常见,因为我们通常会拥有比树深度 (D) 更多的特征 (M)。
在使用 SHAP 验证树模型时,TreeSHAP 通常是更好的选择。我们能够更快地计算 SHAP 值。尤其是当您需要比较多个模型时。对于模型验证,我们对参数 T、L、D 和 M 没有太多选择。这是因为我们只想验证性能最好的模型。
对于数据探索,树算法可用于发现重要的非线性关系和交互。我们的模型只需要足够好就可以捕捉数据中的潜在趋势。所以通过减少树的数量 (T) 和深度 (D) 来使用 TreeSHAP 加快这个过程。并且可以在不大幅提高执行时间的情况下探索许多模型特征(M)。
一些注意事项
在选择方法时,时间复杂度是一个重要因素。在做出选择之前,可能需要考虑其他一些差异。其中包括 KernelSHAP 与模型无关,这些方法受特征依赖的影响,并且只有 TreeSHAP 可用于计算交互效果。
模型不可知
一开始我们就提到了 TreeSHAP 的最大限制是它不是模型无关的。如果使用的是非基于树的算法,将无法使用它。例如神经网络也有自己的逼近方法。这是就需要用到 DeepSHAP。但是KernelSHAP 是唯一可以与所有算法一起使用的方法。
特征依赖
特征依赖可能会扭曲 KernelSHAP 所做的近似。该算法通过随机采样特征值来估计SHAP值。如果当特征相关时,在使用 SHAP 值时,可能会过分重视不太可能的观察结果。
而TreeSHAP 没有问题。但是由于特征依赖性,该算法存在另外问题。即对预测没有影响的特征可以获得非零的 SHAP 值。当该特征与另一个影响预测的特征相关时,就会发生这种情况。在这种情况下会得出错误的结论:即某个特征对预测有贡献。
分析交互
SHAP交互值是SHAP值的扩展。它们通过将特征的贡献分解为其主要和交互影响。对于给定的特征,交互效应是它与其他特征的所有联合贡献。在突出显示和可视化数据中的交互时,这些可能很有用。如果有需要这方面的内容,我们可以单独文章介绍。
如果要使用 SHAP 交互值,则必须使用 TreeSHAP。这是因为它是唯一实现交互值的近似方法。这与 SHAP 交互值的复杂性有关。估计这些 KernelSHAP需要 更长的时间。
总结
应该尽可能使用 TreeSHAP。它速度更快,并且能够分析交互。对于数据探索。如果正在使用其他类型的模型算法,那么将不得不坚持使用 KernelSHAP。,因为它仍然是比蒙特卡罗采样等其他方法更快的近似方法。
作者:Conor O'Sullivan