
一、图像分类介绍
什么是图像分类,核心是从给定的分类集合中给图像分配一个标签的任务。实际上,这意味着我们的任务是分析一个输入图像并返回一个将图像分类的标签。标签来自预定义的可能类别集。
示例:我们假定一个可能的类别集categories = {dog, cat, eagle},之后我们提供一张图1给分类系统:

这里的目标是根据输入图像,从类别集中分配一个类别,这里为dog,我们的分类系统也可以根据概率给图像分配多个标签,如dog:95%,cat:4%,eagle:1%。
图像分类的任务就是给定一个图像,正确给出该图像所属的类别。对于超级强大的人类视觉系统来说,判别出一个图像的类别是件很容易的事,但是对于计算机来说,并不能像人眼那样一下获得图像的语义信息。
计算机能看到的只是一个个像素的数值,对于一个RGB图像来说,假设图像的尺寸是3232,那么机器看到的就是一个形状为332*32的矩阵,或者更正式地称其为“张量”(“张量”简单来说就是高维的矩阵),那么机器的任务其实也就是寻找一个函数关系,这个函数关系能够将这些像素的数值映射到一个具体的类别(类别可以用某个数值表示)。
二、应用场景
图像分类更适用于图像中待分类的物体是单一的,如上图1中待分类物体是单一的,如果图像中包含多个目标物,如下图3,可以使用多标签分类或者目标检测算法。

三、传统图像分类算法
通常完整建立图像识别模型一般包括底层特征学习、特征编码、空间约束、分类器设计、模型融合等几个阶段,如图4所示。
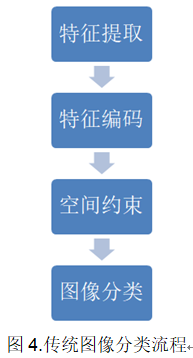
** 1). **底层特征提取: 通常从图像中按照固定步长、尺度提取大量局部特征描述。常用的局部特征包括SIFT(Scale-Invariant Feature Transform, 尺度不变特征转换) 、HOG(Histogram of Oriented Gradient, 方向梯度直方图) 、LBP(Local Bianray Pattern, 局部二值模式)等,一般也采用多种特征描述,防止丢失过多的有用信息。
** 2). **特征编码: 底层特征中包含了大量冗余与噪声,为了提高特征表达的鲁棒性,需要使用一种特征变换算法对底层特征进行编码,称作特征编码。常用的特征编码方法包括向量量化编码、稀疏编码、局部线性约束编码、Fisher向量编码等。
** 3). **空间特征约束: 特征编码之后一般会经过空间特征约束,也称作特征汇聚。特征汇聚是指在一个空间范围内,对每一维特征取最大值或者平均值,可以获得一定特征不变形的特征表达。金字塔特征匹配是一种常用的特征汇聚方法,这种方法提出将图像均匀分块,在分块内做特征汇聚。
** 4). **通过分类器分类: 经过前面步骤之后一张图像可以用一个固定维度的向量进行描述,接下来就是经过分类器对图像进行分类。通常使用的分类器包括SVM(Support Vector Machine, 支持向量机)、随机森林等。而使用核方法的SVM是最为广泛的分类器,在传统图像分类任务上性能很好。
这种传统的图像分类方法在PASCAL VOC竞赛中的图像分类算法中被广泛使用 。
四、深度学习算法
Alex Krizhevsky在2012年ILSVRC提出的CNN模型取得了历史性的突破,效果大幅度超越传统方法,获得了ILSVRC2012冠军,该模型被称作AlexNet。这也是首次将深度学习用于大规模图像分类中。
从AlexNet之后,涌现了一系列CNN模型,不断地在ImageNet上刷新成绩,如图5展示。随着模型变得越来越深以及精妙的结构设计,Top-5的错误率也越来越低,降到了3.5%附近。而在同样的ImageNet数据集上,人眼的辨识错误率大概在5.1%,也就是目前的深度学习模型的识别能力已经超过了人眼。

1、CNN
传统CNN包含卷积层、全连接层等组件,并采用softmax多类别分类器和多类交叉熵损失函数,一个典型的卷积神经网络如图6所示,我们先介绍用来构造CNN的常见组件。
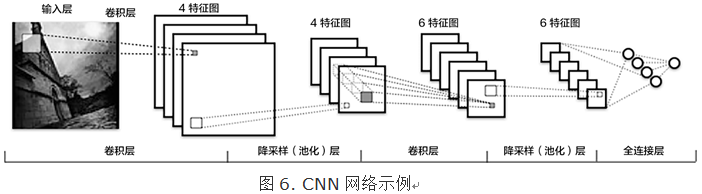
l 卷积层(convolution layer): 执行卷积操作提取底层到高层的特征,发掘出图片局部关联性质和空间不变性质。
l 池化层(pooling layer): 执行降采样操作。通过取卷积输出特征图中局部区块的最大值(max-pooling)或者均值(avg-pooling)。降采样也是图像处理中常见的一种操作,可以过滤掉一些不重要的高频信息。
l 全连接层(fully-connected layer,或者fc layer): 输入层到隐藏层的神经元是全部连接的。
l 非线性变化: 卷积层、全连接层后面一般都会接非线性变化函数,例如Sigmoid、Tanh、ReLu等来增强网络的表达能力,在CNN里最常使用的为ReLu激活函数。
l Dropout: 在模型训练阶段随机让一些隐层节点权重不工作,提高网络的泛化能力,一定程度上防止过拟合。
另外,在训练过程中由于每层参数不断更新,会导致下一次输入分布发生变化,这样导致训练过程需要精心设计超参数。如2015年Sergey Ioffe和Christian Szegedy提出了Batch Normalization (BN)算法 中,每个batch对网络中的每一层特征都做归一化,使得每层分布相对稳定。BN算法不仅起到一定的正则作用,而且弱化了一些超参数的设计。
经过实验证明,BN算法加速了模型收敛过程,在后来较深的模型中被广泛使用。
2、VGG
牛津大学VGG(Visual Geometry Group)组在2014年ILSVRC提出的模型被称作VGG模型。该模型相比以往模型进一步加宽和加深了网络结构,它的核心是五组卷积操作,每两组之间做Max-Pooling空间降维。同一组内采用多次连续的3X3卷积,卷积核的数目由较浅组的64增多到最深组的512,同一组内的卷积核数目是一样的。卷积之后接两层全连接层,之后是分类层。
由于每组内卷积层的不同,有11、13、16、19层这几种模型,下图展示一个16层的网络结构。VGG模型结构相对简洁,提出之后也有很多文章基于此模型进行研究,如在ImageNet上首次公开超过人眼识别的模型就是借鉴VGG模型的结构。

3、GoogLeNet
GoogLeNet 在2014年ILSVRC的获得了冠军,在介绍该模型之前我们先来了解NIN(Network in Network)模型和Inception模块,因为GoogLeNet模型由多组Inception模块组成,模型设计借鉴了NIN的一些思想。
NIN模型主要有两个特点:
1.引入了多层感知卷积网络(Multi-Layer Perceptron Convolution, MLPconv)代替一层线性卷积网络。MLPconv是一个微小的多层卷积网络,即在线性卷积后面增加若干层1x1的卷积,这样可以提取出高度非线性特征。
2.传统的CNN最后几层一般都是全连接层,参数较多。而NIN模型设计最后一层卷积层包含类别维度大小的特征图,然后采用全局均值池化(Avg-Pooling)替代全连接层,得到类别维度大小的向量,再进行分类。这种替代全连接层的方式有利于减少参数。
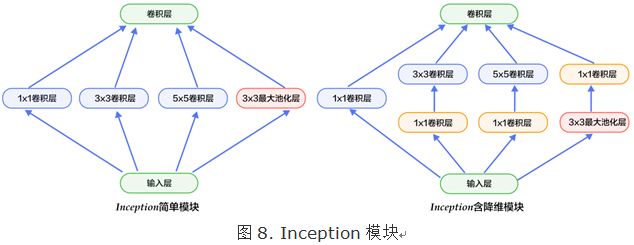
Inception模块如下图8所示,下图左是最简单的设计,输出是3个卷积层和一个池化层的特征拼接。这种设计的缺点是池化层不会改变特征通道数,拼接后会导致特征的通道数较大,经过几层这样的模块堆积后,通道数会越来越大,导致参数和计算量也随之增大。
为了改善这个缺点,下图右引入3个1x1卷积层进行降维,所谓的降维就是减少通道数,同时如NIN模型中提到的1x1卷积也可以修正线性特征。
GoogLeNet由多组Inception模块堆积而成。另外,在网络最后也没有采用传统的多层全连接层,而是像NIN网络一样采用了均值池化层;但与NIN不同的是,GoogLeNet在池化层后加了一个全连接层来映射类别数。
除了这两个特点之外,由于网络中间层特征也很有判别性,GoogLeNet在中间层添加了两个辅助分类器,在后向传播中增强梯度并且增强正则化,而整个网络的损失函数是这个三个分类器的损失加权求和。
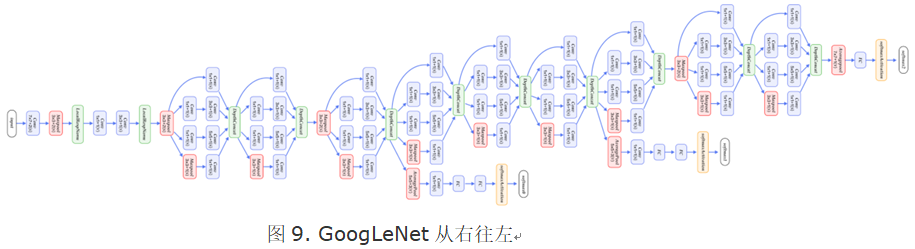
GoogLeNet整体网络结构如图9所示,总共22层网络:开始由3层普通的卷积组成;接下来由三组子网络组成,第一组子网络包含2个Inception模块,第二组包含5个Inception模块,第三组包含2个Inception模块;然后接均值池化层、全连接层。
上面介绍的是GoogLeNet第一版模型(称作GoogLeNet-v1)。GoogLeNet-v2引入BN层;GoogLeNet-v3 对一些卷积层做了分解,进一步提高网络非线性能力和加深网络;GoogLeNet-v4引入下面要讲的ResNet设计思路。从v1到v4每一版的改进都会带来准确度的提升,介于篇幅,这里不再详细介绍v2到v4的结构。
4、ResNet
ResNet(Residual Network) 是2015年ImageNet图像分类、图像物体定位和图像物体检测比赛的冠军。针对随着网络训练加深导致准确度下降的问题,ResNet提出了残差学习方法来减轻训练深层网络的困难。
在已有设计思路(BN, 小卷积核,全卷积网络)的基础上,引入了残差模块。每个残差模块包含两条路径,其中一条路径是输入特征的直连通路,另一条路径对该特征做两到三次卷积操作得到该特征的残差,最后再将两条路径上的特征相加。
残差模块如图10所示,左边是基本模块连接方式,由两个输出通道数相同的3x3卷积组成。右边是瓶颈模块(Bottleneck)连接方式,之所以称为瓶颈,是因为上面的1x1卷积用来降维(图示例即256->64),下面的1x1卷积用来升维(图示例即64->256),这样中间3x3卷积的输入和输出通道数都较小(图示例即64->64)。
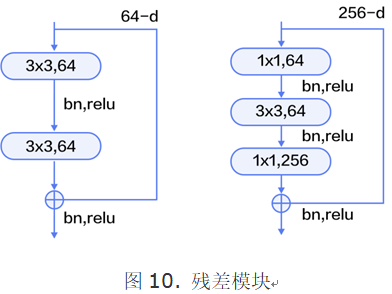
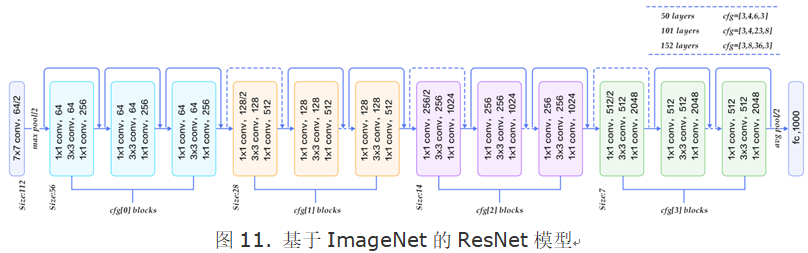
图11展示了50、101、152层网络连接示意图,使用的是瓶颈模块。这三个模型的区别在于每组中残差模块的重复次数不同(见图右上角)。ResNet训练收敛较快,成功的训练了上百乃至近千层的卷积神经网络。
五、GitHub资源
下面列举了搜集的开源的一些基于深度学习的图像分类的小项目,读者感兴趣可自行尝试。
l 使用tensorflow和cnn做的图像识别,对四种花进行了分类。: https://github.com/waitingfordark/four_flower
l 使用vgg16,vgg19对cifar数据集中的图像进行分类:https://github.com/caozhang1996/VGG-cifar10
l 基于Keras实现Kaggle2013--Dogs vs. Cats12500张猫狗图像的精准分类: GitHub - MaisyZhang/kaggle-dogs-vs-cats: 基于Keras实现Kaggle2013--Dogs vs. Cats12500张猫狗图像的精准分类
l keras使用迁移学习实现医学图像二分类(AK、SK):GitHub - jinghaiting/binary_classification_keras: keras使用迁移学习实现医学图像二分类(AK、SK)
版权归原作者 |旧市拾荒| 所有, 如有侵权,请联系我们删除。