
在计算机视觉领域,注意力机制(Attention Mechanism)已成为提升模型性能的关键技术之一。注意力机制通过模拟人类视觉的选择性注意力,能够在海量数据中自动聚焦于最相关的信息,从而提高模型的效率和准确性。下面将介绍通道注意力、空间注意力、自注意力和交叉注意力四种类型。
通道注意力
通道注意力是一种专注于卷积神经网络(CNN)中特征图通道(feature map channels)的重要性分配的机制。其主要目的是通过为每个通道分配不同的权重,来强调对任务最有贡献的通道,抑制无关或冗余的通道,从而提升模型的表现。
以SE模块为例:

- Squeeze:通过全局平均池化(Global Average Pooling, GAP)将特征图HxWxC压缩成1x1xC,即得到每个通道的平均池化后的特征,该特征为一个值。
- Excitation:全局特征向量通过几个全连接(FC)层进行非线性变换,通常包括一个ReLU激活函数和一个sigmoid激活函数。将输出值压缩到0和1之间,生成一个与输入通道数相同长度的权重向量1x1xC。
- 将通道权重乘以原本的特征图即可得到通道注意力特征图。
再如以下的结构图:通过CAP(全局平均池化),再通过sigmoid得到每个通道的权重图,与原来的特征相乘即可得到经过通道注意力之后的特征图。

如下通道注意力:
- 全局池化:对输入特征图的每个通道进行全局平均池化,得到每个通道的全局空间特征。
- 特征重塑:将池化后的特征重塑为一维向量,为每个通道生成一个单一的数值。
- 1x1卷积:使用1x1卷积核对重塑后的特征向量进行卷积操作,生成每个通道的权重。
- 激活函数:可选地使用激活函数来引入非线性,增强模型的表达能力。

通道注意力的实现方法有很多,总的来说就是获得通道权重,再与原本特征相乘。
空间注意力
空间注意力是一种专注于特征图的空间维度的重要性分配的机制。它通过对特征图中的特定空间位置进行加权,从而突出对任务最有贡献的区域,抑制无关或冗余的区域,以提高模型的性能。
- 首先,对一个尺寸为 H×W×C的输入特征图F进行通道维度的全局最大池化和全局平均池化,得到两个 H×W×1 的特征图;(在通道维度进行池化,压缩通道大小,便于后面学习空间的特征)
- 然后,将全局最大池化和全局平均池化的结果,按照通道拼接(concat),得到特征图尺寸为HxWx2,
- 最后,对拼接的结果进行7x7的卷积操作,得到特征图尺寸为 HxWx1,接着通过Sigmoid激活函数 ,得到空间注意力权重矩阵
- 权重矩阵再与原来的特征图相乘即可得到空间注意力特征图

总得来说可看下图:
- 通过局部网络从空间维度缩减特征为H×W×1
- 通过激活函数得到权重矩阵
- 权重矩阵与原来特征相乘

混合注意力
在混合注意力机制中,通道注意力和空间注力可以通过串联、或者并联的方式进行组合。
以下为串联和并联的两种形式,一般来说,串联效果会好一点。


自注意力
自注意力是一种专注于输入数据的内部关系的重要性分配机制,广泛应用于自然语言处理和计算机视觉等领域。它通过计算输入数据中每个元素与其他所有元素之间的相似性,来动态地调整各元素的重要性,从而更好地捕捉全局依赖关系和上下文信息。
注意力的思想,类似于寻址。给定Query,去Source中计算Query和不同Key的相关性,即计算Source中不同Value值的权重系数;Value的加权平均结果可以作为注意力值。
以Transformer的自注意力为例:

- 特征映射:首先,将输入数据映射到查询(Query)、键(Key)和值(Value)三个向量表示中。这一步骤通常通过线性变换实现。
,
,
其中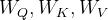是可训练的权重矩阵
- 相似性计算:计算查询向量和键向量之间的相似性得分,通常使用点积来实现。这些相似性得分表示了输入数据中每个元素与其他所有元素之间的关系。
其中S是相似性得分矩阵, 是缩放因子,防止点积值过大。
- 注意力权重计算:将相似性得分通过Softmax函数进行归一化,得到注意力权重。这些权重反映了每个元素对其他元素的重要性。
其中A是注意力权重。
- 加权求和:将注意力权重与值向量进行加权求和,得到经过自注意力调整后的输出表示。通过这种方式,每个元素的表示包含了与其他所有元素的关联信息。
交叉注意力
交叉注意力是一种专注于不同模态或不同序列之间关系的重要性分配机制,广泛应用于多模态任务和序列对序列的任务中。它通过计算一个模态(或序列)的查询(Query)向量与另一个模态(或序列)的键(Key)和值(Value)向量之间的相似性,来动态地调整每个模态(或序列)对其他模态(或序列)的关注,从而实现信息的综合利用。
即与自注意力不同的是Q来自一个模态(或序列),K和V来说另模态(或序列)。Q决定了哪个模态或序列将聚焦于哪个模态或序列的特征信息,从而实现信息的综合利用和融合。
- 特征映射:首先,将两个模态(或序列)的输入数据分别映射到查询(Query)、键(Key)和值(Value)向量表示中。这一步骤通常通过线性变换实现。
,
,
其中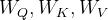是可训练的权重矩阵
- 相似性计算:计算一个模态(或序列)的查询向量和另一个模态(或序列)的键向量之间的相似性得分,通常使用点积来实现。这些相似性得分表示了一个模态(或序列)中每个元素与另一个模态(或序列)中所有元素之间的关系。
其中S是相似性得分矩阵, 是缩放因子,防止点积值过大。
- 注意力权重计算:将相似性得分通过Softmax函数进行归一化,得到注意力权重。这些权重反映了一个模态(或序列)的每个元素对另一个模态(或序列)中所有元素的重要性。
其中A是注意力权重。
- 加权求和:将注意力权重与值向量进行加权求和,得到经过交叉注意力调整后的输出表示。通过这种方式,每个模态(或序列)的表示包含了与另一个模态(或序列)的关联信息。
可看下图:Q来自一个序列,K和V来说另一个序列

再如下图:是Q来自文本模态,K和V来说视觉模态 。

总结
注意力机制(通道注意力、空间注意力、自注意力和交叉注意力)是现代神经网络模型中至关重要的技术。它们通过动态调整输入特征的权重,增强模型对重要信息的关注,从而显著提升了各种复杂任务(如图像处理、自然语言处理和多模态任务)的性能。这些机制的广泛应用和不断发展,促进了深度学习技术的进步和创新。
版权归原作者 夏日的盒盒 所有, 如有侵权,请联系我们删除。