
EfficicentNet网络简介
EfficientNet:Rethinking Model Scaling for Convolutional Neural Networks,这篇论文是Google在2019年发表的文章。
EfficientNet这篇论文,作者同时关于
输入分辨率,网络深度,宽度
对准确率的影响,在之前的文章中是
单独增加图像分辨率或增加网络深度或单独增加网络的宽度
,来试着提升网络的准确率。在EfficientNet这篇论文中,作者使用了
网络搜索技术NAS
去同时探索输入分辨率,网络深度、宽度的影响。
EfficientNet的效果究竟如何呢?
这幅图是原论文作者给出的关于Efficient以及当时主流的一系列分类网络的
Top-1
的准确率,我们发现
EfficientNet不仅在参数数量上比很多主流模型要小以外,准确率明显也要更好
。
- 论文中提到,本文提出的
EfficientNet-B7在ImageNet top-1达到了当年最高的准确率84.3%,与之前准确率最高的GPipe相比,参数数量仅为其1/8.4,推理速度提升了6.1倍
网络对比(宽度、深度、分辨率)
 - 图a 传统的卷积神经网络
- 图a 传统的卷积神经网络
- 图b,在图a的基础上单独增加了网络的
宽度(宽度代表的是特征层的channel) - 图c,在图a的基础上单独增加了网络的
深度,明显可以看到相对于图a,它的layers明显更多了,网络会变得更加深 - 图d,在图a基准网络的基础上对图像的
分辨率进行了增加,提升图像的分辨率我们得到的每个特征矩阵高和宽会相应的增加 - 图e, 对网络同时增加网络的宽度、深度以及输入图像的分辨率

- 根据以往的经验,增加网络的深度depth能够得到更加丰富、复杂的特征并且能够很好的应用到其他任务中。
但网络的深度过深会面临梯度消失,训练困难的问题。 - 增加网络的
width能够获得更细粒度的特征并且也更容易训练,但对于width很大而且深度较浅的网络往往很难学习到更深层次的特征。 - 增加输入网络的
图像分辨率能够潜在得获得更高细粒度的特征模板,但对于非常高的输入分辨率,准确度的增益也会减少。并且大分辨率图像会增加计算量。
从上图可以看出,
scale by width
,
scale by depth
,
scale by resolution
,发现这三条虚线基本上在准确率达到
80%以后基本上就饱和了不在增加了
。对于红色的线,我们同时增加网络的
宽度、深度、分辨率
,我们发现它达到了
80%的准确率后并没有出现饱和的现象,并且还可以继续增长上去
。这就说明了我们同时增加网络的
深度、宽度、分辨率
的话,我们是可以得到一个更好的结果的.

并且当理论的计算量相同时,我们同时增加网络的深度、宽度、分辨率的话,网络的效果会更好。
EfficientNet-B0 Network
EfficientNet-B0网络,也是作者通过
网络搜索技术
得到的,它的详细网络参数如下表
EfficientNet-B0 网络结构
- 我们发现在
Efficient中stage一共有1~9个stage。stage 1是一个3x3的卷积层。对于stage2~stage8我们能够发现,它是在重复堆叠MBConv,这里的MBConv就是MobienetConv,后续会讲到。Stage 9是由3部分构成:Conv 1x1和Pooling和FC`层。 - 这里的分辨率(
Resolution),对应的是输入每个Stage的高度和宽度 Channels,对应我们每个Stage输出特征矩阵的channel个数,Layers: 将我们对应的Operator重复多少次,比如stage3对应的Layers为2,就会对MBConv6重复两次- 这里的
stride对应的Layers对应的第一层的stride,其他的步距都等于1的。
EfficientNet-B0 Network
MBConv 模块
论文中其实也说了,MBConv其实和MobileNet v3使用的Block是一样的。我们来简单看下在
Efficient
中我们使用的MBConv它的结构。
- 首先对我们的主分支而言,是一个
1x1的卷积一般是用来升维的,然后通过BN以及Swish激活函数 - 紧接着通过一个
DW卷积,它的卷积核是k x k,k可能是3也可能是5,这里的步距可能是1也可能是2. - 紧接着将
DW卷积的输出通过BN和Swish激活函数之后,在通过一个SE模块。 - 紧接着在通过一个
1x1的卷积,这里的1x1卷积启动一个降维的作用,注意这里只有一个BN,没有swish激活函数。 - 紧接着在通过一个
dropout操作 - 然后将我们输入特征矩阵,从我们
捷径分支引过来,直接与我们主分支得到的输出特征矩阵进行相加得到我们对应的输出。
这里需要注意几个点:
- 第一个升维的卷积层,它的卷积核个数是输入特征矩阵
channel的n倍,这里的n对应的是多少呢,就是我们Operator对应的MBCov对应的数字,就是我们的倍率因子n
- 对于MBConv最后一个降维的卷积层,它的卷积核个数等于多少呢,它就是对应我们上图表格中对应的
Channels来进行设置的。这里Channels等于多少,我们这里1x1卷积核个数就等于多少。 - 第2个注意点就是当MBConv1时,即此时n=1的时候,我们是不需要
1x1的卷积层的,因为我们知道第一个1x1卷积主要起到升维作用,那么当n=1的时候相当于并没有升维。对应的就是表格中的Stage2中对应的operator是MBConv1,它这里的MBConv是没有1x1的卷积层的 - 关于
shortcut连接,仅当输入MBConv结构特征矩阵与输出的特征矩阵shape相同的时才存在
SE模块
- 首先对输入特征矩阵的
feature map的每一个channel进行平均池化操作 ,然后在分别通过两个全连接层。 - 注意的是第一个全连接层的激活函数是
Swish激活函数,第二个全连接层的激活函数使sigmoid激活函数。 -第一个全连接层的节点个数是输入该MBConv特征矩阵channels的1/4,第二个全连接层的节点个数等于feature_map的channels个数,这里的feature_map就MBConv中DW输出的特征矩阵。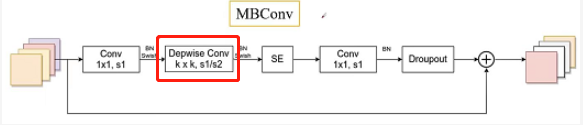
EfficientNet-B0~ EfficientNet-B7网络参数

EfficientNet-B0~ EfficientNet-B7网络的结构都是一样的,就是网络的input_size,width_coefficient,depth_coefficient等参数设置存在差异。width_coefficient代表channel维度上的倍率因子,比如在EfficientNetB0中的Stage1的3x3卷积层所使用的卷积核个数是32,那么在B6中就是32 x 1.8=57.6接着取整到离它最近的8倍整数即56,其他stage同理。depth_coefficient代表depth维度上的倍率因子(仅针对Stage2到Stage8),比如在EfficientNetB0中Stage7的L=4,那么在B6中就是4 x 2.6 =10.4,接着向上取整即11drop_connect_rate它对应的就是MBConv当中的dropout层的随机失活比例,注意并不是所有MBConv层的dropout都等于0.2.在源码实现中,将所有的MBConv结构中dropout层的随机失活比率从0一直慢慢增长到所给定的drop_connect_rate,- 最后一个
dropout_rate对应的是EfficientNet最后全连接层之前对应的dropout失活比率
性能对比
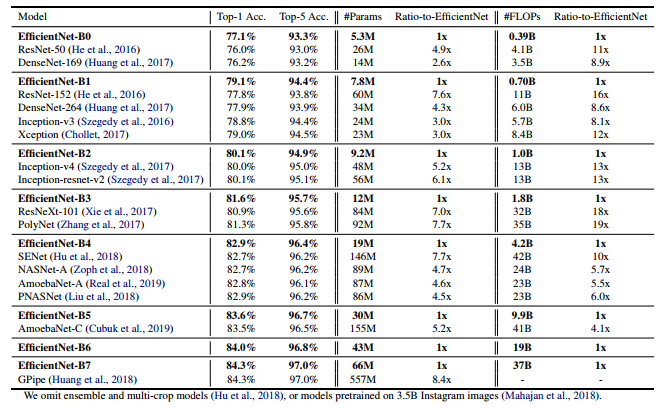
- EfficientNet-B0对比的是我们ResNet-50以及我们DenseNet-169,我们可以看到它的准确率是最高的,参数量是最少的,它的理论上的计算量是最低的。同样B1~B7都对一系列网络进行了对比
- 不过在实际使用过程中,
首先它的准确率确实是挺高的,然后它的参数个数确实也很少,这是毋庸置疑的。但是有个问题网络训练时非常占GPU的显存,因为在我们EfficientNet中像B4,B5,B6,B7这些模型,它的输入图片的分辨率非常大导致我们每一个层结构输出特征矩阵的高和宽都要相应的增加。所以对于我们显存的占用也会增加。 - 而且对于速度直接对比
Flops是不完全对的,真实情况下我们所关注的速度其实是在设备上的推理的速度;真实的推理速度和Flops其实不是直接相关的,它还有很多其他因素的影响,所以如果你能给出在某些设备上它的推理时间的话会更加有意义
本文转载自: https://blog.csdn.net/weixin_38346042/article/details/125813186
版权归原作者 @BangBang 所有, 如有侵权,请联系我们删除。
版权归原作者 @BangBang 所有, 如有侵权,请联系我们删除。