
文章目录
1、简介
1.1 whisper
https://github.com/openai/whisper
Whisper 是一种通用语音识别模型。它是在各种音频的大型数据集上训练的,也是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。
OpenAI 的开源模型 whisper,可以执行 99 种语言的语音识别和文字转写。但是 whisper 模型占用计算资源多,命令行使用门槛高。whisper 模型本身还存在一些问题,例如 模型幻听问题。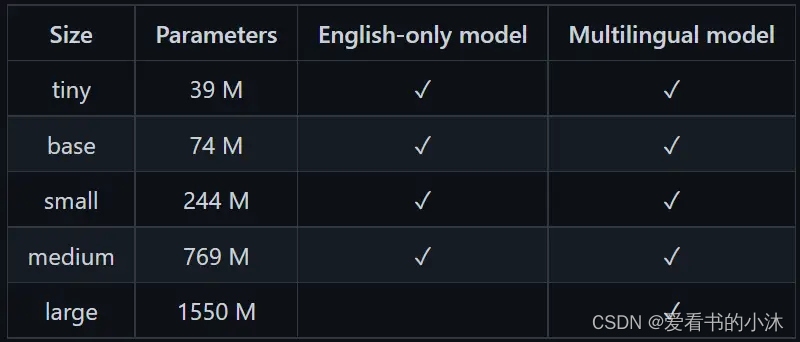
Whisper是可以理解多种语言的自动语音识别()系统。它已经接受了从网络收集的 680,000 小时监督数据的训练。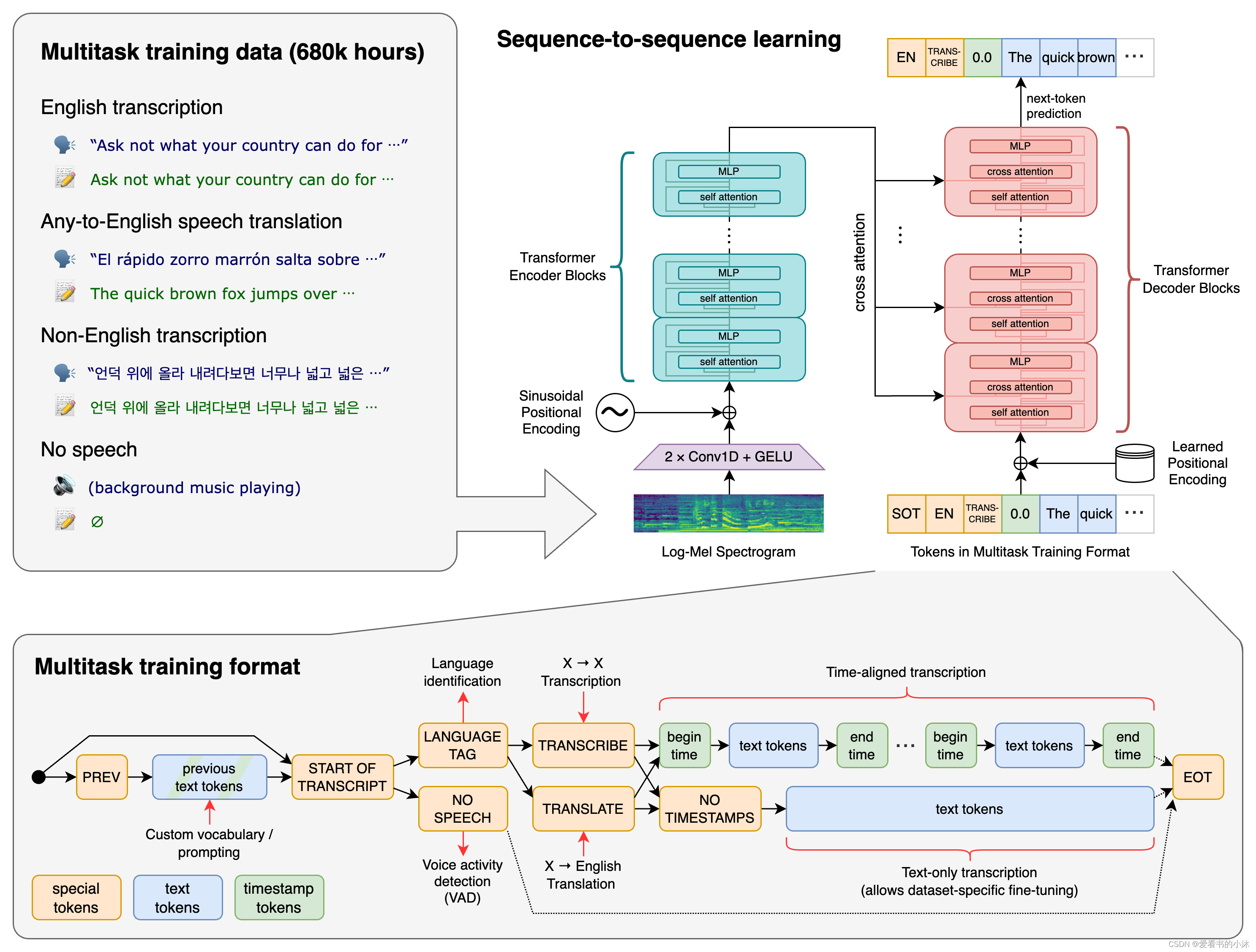
Transformer 序列到序列模型针对各种语音处理任务进行训练,包括多语言语音识别、语音翻译、口语识别和语音活动检测。这些任务共同表示为解码器要预测的一系列标记,从而允许单个模型取代传统语音处理管道的许多阶段。多任务训练格式使用一组特殊标记作为任务说明符或分类目标。
pip install-U openai-whisper
# pip install git+https://github.com/openai/whisper.git # pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git
1.2 faster-whisper
https://github.com/SYSTRAN/faster-whisper
faster-whisper是基于OpenAI的Whisper模型的高效实现,它利用CTranslate2,一个专为Transformer模型设计的快速推理引擎。这种实现不仅提高了语音识别的速度,还优化了内存使用效率。faster-whisper的核心优势在于其能够在保持原有模型准确度的同时,大幅提升处理速度,这使得它在处理大规模语音数据时更加高效。
2、安装
git clone https://github.com/ycyy/faster-whisper-webui.git
# 进入项目的目录cd faster-whisper-webui
# 安装项目依赖
pip3 install-r requirements.txt
# 装一下faster-whisper依赖
pip3 install-r requirements-fasterWhisper.txt
您可以选择使用 或 .Faster Whisper 作为 默认 Whisper 可实现高达 4 倍的加速和 2 倍的内存使用量减少。
mkdir models
cd models
#需要配置VAD模型:git clone https://github.com/snakers4/silero-vad
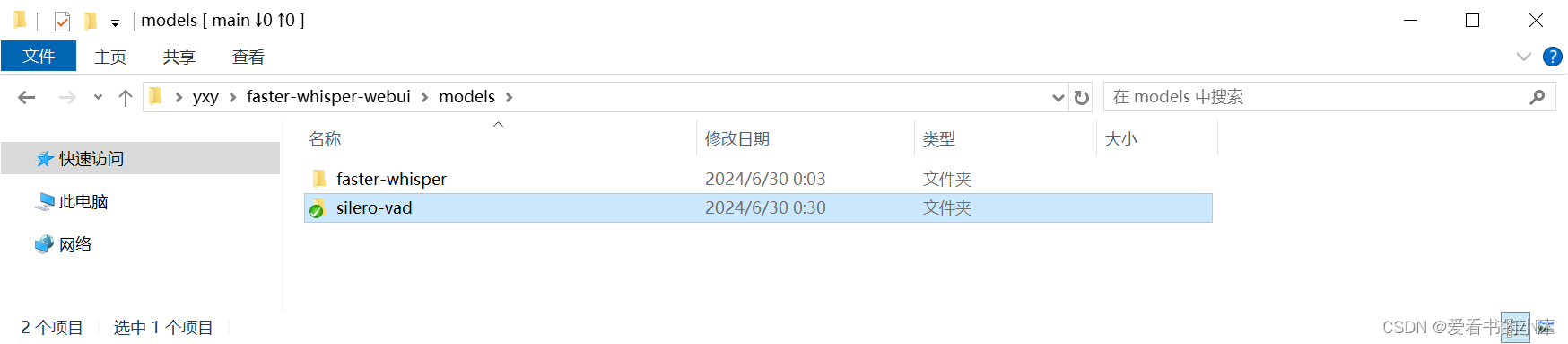
新建文件夹faster-whisper,再在里面新建子文件夹large-v2,里面存放模型文件。
下载faster-whisper模型:
https://huggingface.co/guillaumekln/faster-whisper-large-v2
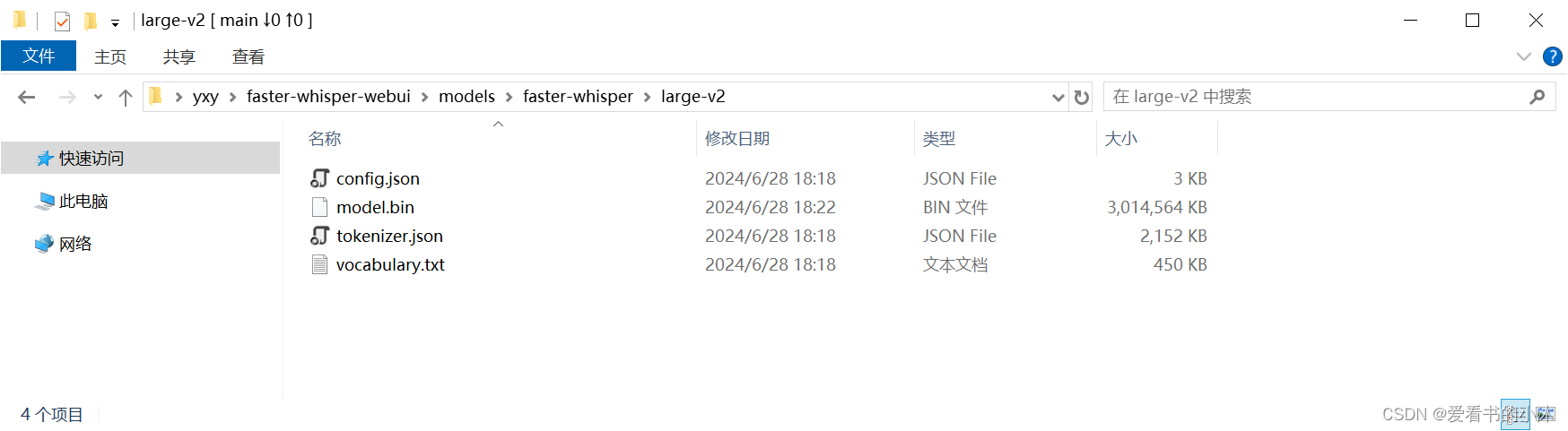
最后代码的整个文件夹树如下:
|─faster-whisper-webui
|─models
├─faster-whisper
│ ├─base
│ ├─large
│ ├─large-v2
│ ├─medium
│ ├─small
│ └─tiny
└─silero-vad
├─examples
│ ├─cpp
│ ├─microphone_and_webRTC_integration
│ └─pyaudio-streaming
├─files
└─__pycache__
在代码文件cli.py文件的最前面添加如下代码:
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
3、测试
您还可以运行 CLI 接口,该接口类似于 Whisper 自己的 CLI,但也支持以下附加参数:
python cli.py \[--vad {none,silero-vad,silero-vad-skip-gaps,silero-vad-expand-into-gaps,periodic-vad}]\[--vad_merge_window VAD_MERGE_WINDOW]\[--vad_max_merge_size VAD_MAX_MERGE_SIZE]\[--vad_padding VAD_PADDING]\[--vad_prompt_window VAD_PROMPT_WINDOW][--vad_cpu_cores NUMBER_OF_CORES][--vad_parallel_devices COMMA_DELIMITED_DEVICES][--auto_parallel BOOLEAN]
python cli.py --model large --vad silero-vad --language Japanese "https://www.youtube.com/watch?v=4cICErqqRSM"
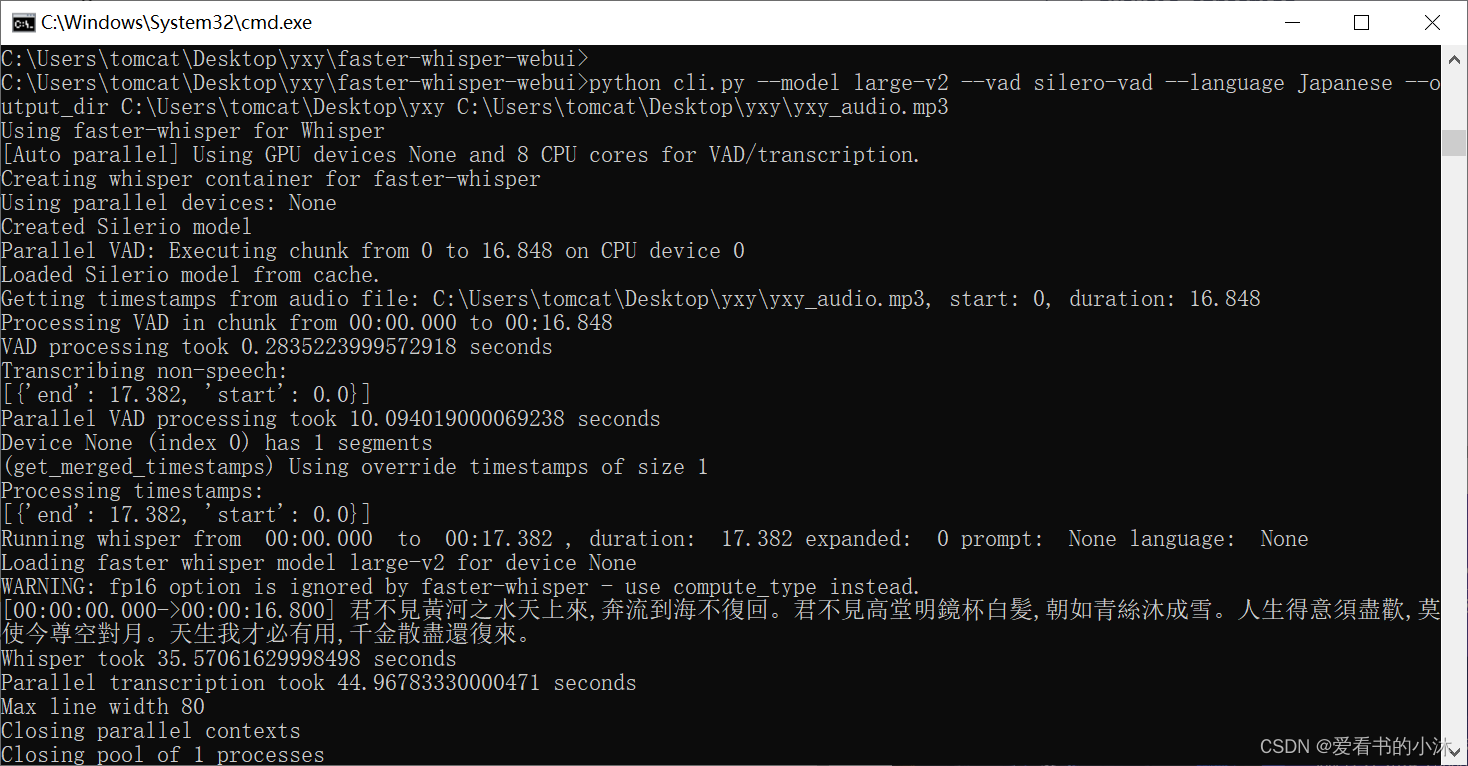
python cli.py --model large-v2 --vad silero-vad --language Japanese --output_dir C:\Users\tomcat\Desktop\yxy C:\Users\tomcat\Desktop\yxy\yxy_audio.mp3
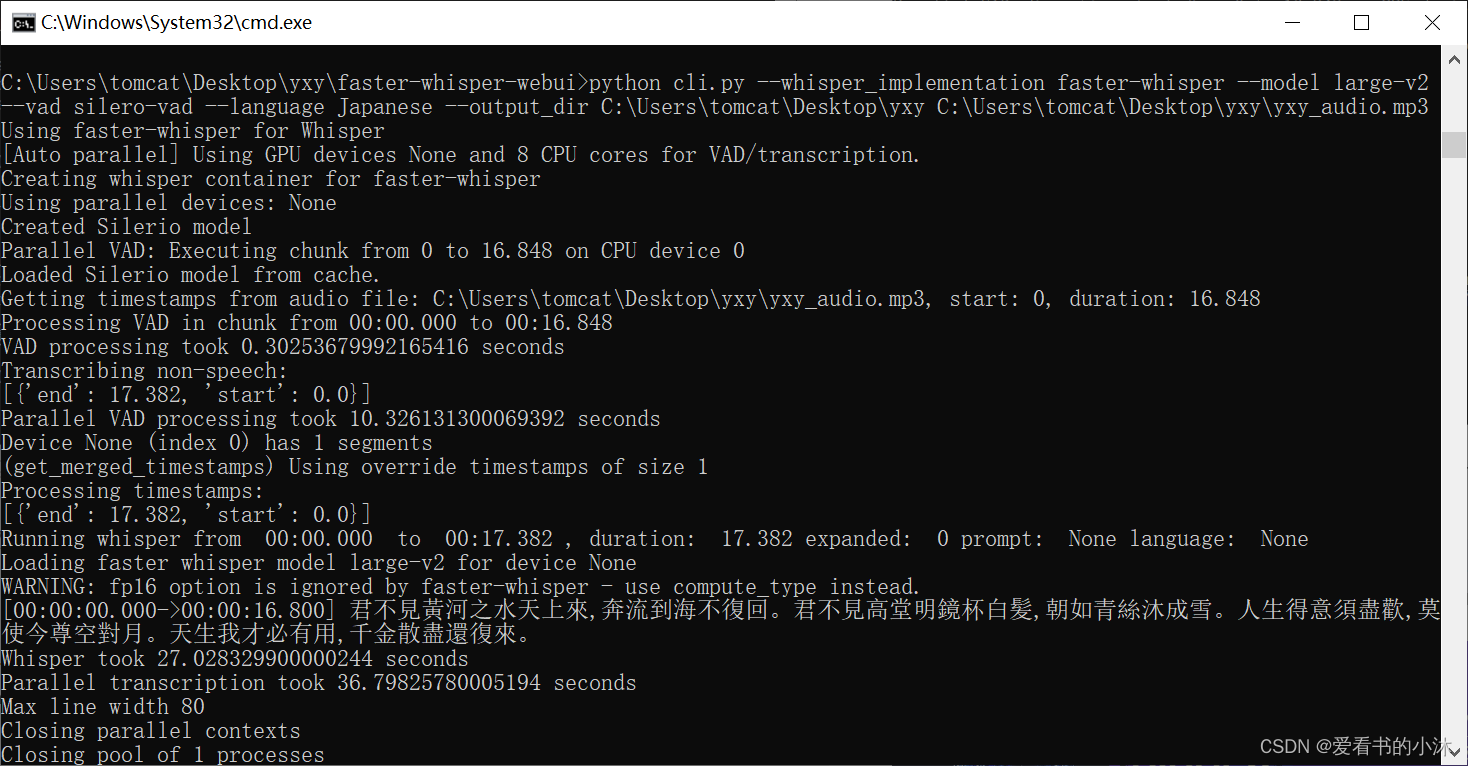
上面只是用了whisper原版的算法,现在添加–whisper_implementation faster-whisper参数来使用faster-whisper改进后的算法:
python cli.py --whisper_implementation faster-whisper --model large-v2 --vad silero-vad --language Japanese --output_dir C:\Users\tomcat\Desktop\yxy C:\Users\tomcat\Desktop\yxy\yxy_audio.mp3
更多AI信息如下:
2024第四届人工智能、自动化与高性能计算国际会议(AIAHPC 2024)将于2024年7月19-21日在中国·珠海召开。
大会网站:更多会议详情
时间地点:中国珠海-中山大学珠海校区|2024年7月19-21日
结语
如果您觉得该方法或代码有一点点用处,可以给作者点个赞,或打赏杯咖啡;
╮( ̄▽ ̄)╭
如果您感觉方法或代码不咋地
//(ㄒoㄒ)//
,就在评论处留言,作者继续改进;
o_O???
如果您需要相关功能的代码定制化开发,可以留言私信作者;
(✿◡‿◡)
感谢各位大佬童鞋们的支持!
( ´ ▽´ )ノ ( ´ ▽´)っ!!!
版权归原作者 爱看书的小沐 所有, 如有侵权,请联系我们删除。