
文章来源 | 恒源云社区(恒源云,专注 AI 行业的共享算力平台)
原文地址 | 论文笔记
原文作者 | Mathor
我在,或者我不在,大佬就在那里,持续不断的发文!
所以,我还是老老实实的搬运吧!
正文开始:
文本扩增(Text Augmentation)现在大部分人都在用,因为它可以帮助提升文本分类的效果,具体来说常用的方法包括但不限于:替换、删除、增加。一般来说文本扩增都会使得最终的性能更好,少部分情况下会更差。你或许可能想过是因为诸如删除、替换等方法将句子中一些重要的词给抹去了,但是到底句子中那些词是重要的词呢?哪些词可以进行扩增,哪些词最好不要扩增?
ACL2022有一篇名为《Roles of Words: What Should (n’t) Be Augmented in Text Augmentation on Text Classification Tasks?》的投稿研究了这个问题,并且给出了指导方法。首先作者对FD News数据集进行训练,最终在测试集上的准确率为98.92%,这说明模型对数据集的拟合程度非常好。接着作者手动输入几个测试样本,如下所示
因为单词"basketball"和"athletes"经常出现在"sport"类的训练样本中,所以模型能非常准确的将其预测为"sport"类;然而从第2和4个样本来看,模型的表现并不像我们想象的那么好。由于"Based on"和"team"在训练集中经常与类别为"sport"的句子共同出现,模型被这种数据集进行训练后,自然会带有一点「偏见」;从最后一个例子来看,模型无法正确识别出与体育相关的专业词汇:三分(three-pointer)
上面这个例子启发我们从「统计相关性」和「语义相似性」两个角度看待句子中的每个词。具体来说,我们可以从这两个角度给每个词分配一种「角色」,总共有4种角色:
- Common Class-indicating words (CC-words):高统计相关性与高语义相似性
- Specific Class-indicating words (SC-words):低统计相关性与高语义相似性
- Intermediate Class-indicating words (IC-words):高统计相关性与低语义相似性
- Class-irrelevant words/Other words (O-words):低统计相关性与低语义相似性
STATISTICAL CORRELATION & SEMANTIC SIMILARITY
作者采用weighted log-likelihood ratio (WLLR) 衡量句子中的每个词与类别之间的统计相关性,WLLR分数的计算公式如下: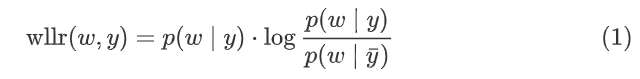
其中,
w
w
w是一个单词;
y
y
y是一个类别;
y
ˉ
\bar{y}
yˉ代表所有类别。
wllr
(
w
,
y
)
\text{wllr}(w,y)
wllr(w,y)越大,词
w
w
w与类别
y
y
y之间的统计相关性越高
为了衡量两个词的语义相似度,最直接的办法是计算两个向量的余弦相似度,但是这里作者并没有使用比较复杂的BERT-based模型提取单词的向量,因为需要比较大的计算资源,作者直接使用简单的Word2Vec方法得到一个单词的向量。预先相似度的计算公式如下:
其中,
l
l
l代表类别,
v
w
,
v
l
v_w,v_l
vw,vl分别代表词和类别的向量表示
一般来说类别都是有文本描述的,例如"体育"、"电脑"等,我们直接使用其描述当作
l l l
计算完给定句子中所有词的统计相关性与余弦相似性之后,我们设定一个阈值以区分高(低)WLLR分数
C
h
(
C
l
)
C_h(C_l)
Ch(Cl),同样也要区分高(低)余弦分数
S
h
(
S
l
)
S_h(S_l)
Sh(Sl)
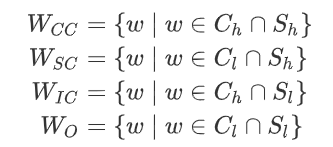
其中,
W
C
C
,
W
S
C
,
W
I
C
,
W
O
W_{CC}, W_{SC}, W_{IC}, W_{O}
WCC,WSC,WIC,WO分别表示CC-words, SC-words, IC-words以及O-words。一个真实的抽取样例如下

RESULTS
作者实验时使用的阈值为两个指标的中位数。首先是删除实验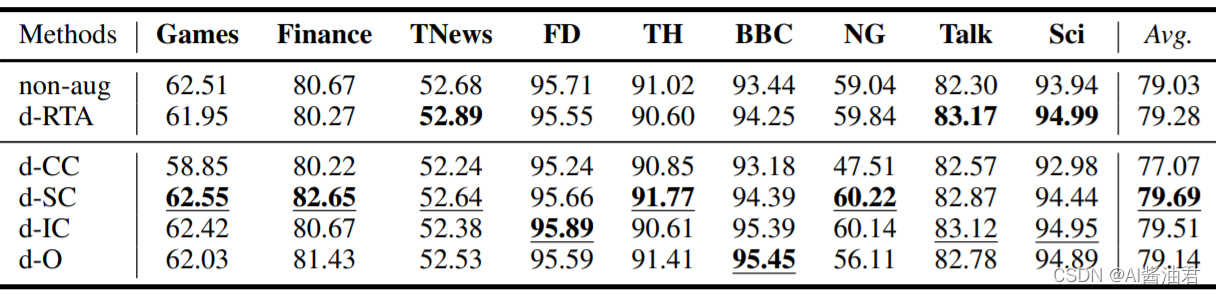
从结果来看,删除CC-words对性能的损失影响非常大;删除SC-words和IC-words带来的积极影响比较多。实际上第一条结论我们很容易想到,因为CC-words与标签同时具有高相关性与高语义相似性,将它删除肯定会大幅降低模型判断的准确率。但是后一条结论有些不符合我的猜想,我一开始认为删除O-words会更好,因为O-words与标签并不怎么相关,删除它也无伤大雅。但事实是删除SC-words和IC-words效果更好,论文里的解释是,因为SC-words与标签的统计相关性比较低、语义相似性比较高,删除这些词可以强迫模型更关注CC-words。IC-words与标签的统计相关性比较高、语义相似性比较低,论文解释说,IC-words通常是一些带有噪声以及bias的数据,删除它们可以帮助模型避免学到关于该类别的不正确特征
同理,作者也做了插入、替换、交换的数据扩增方法,这里就不一一列出结果了,感兴趣的读者自行阅读原论文即可。下面贴一张表,是作者对四种数据扩增方法使用的一个总结
个人总结
这篇论文提出了一种有选择性的文本扩增方法。具体来说,论文设定了四种角色,并且将每个单词分配为一个角色,面对不同的扩增手段,对不同角色的单词进行操作。这样可以有效地避免信息损失,并且生成高质量的文本数据
版权归原作者 AI酱油君 所有, 如有侵权,请联系我们删除。