
Agent的发展成为了LLM发展的一个热点。只需通过简单指令,Agent帮你完成从输入内容、浏览网页、选择事项、点击、返回等一系列需要执行多步,才能完成的与网页交互的复杂任务。
比如给定任务:“搜索Apple商店,了解iPad智能保护壳Smart Folio的配件, 并查看最近的自提点位置 (邮政编码90038)。”
下图演示Agent如何按照在线方式逐步与Apple网站进行交互,完成任务。在最后的屏幕截图中,Agent获取了所需的信息,然后选择"ANSWER"动作进行回应和导航的结束。
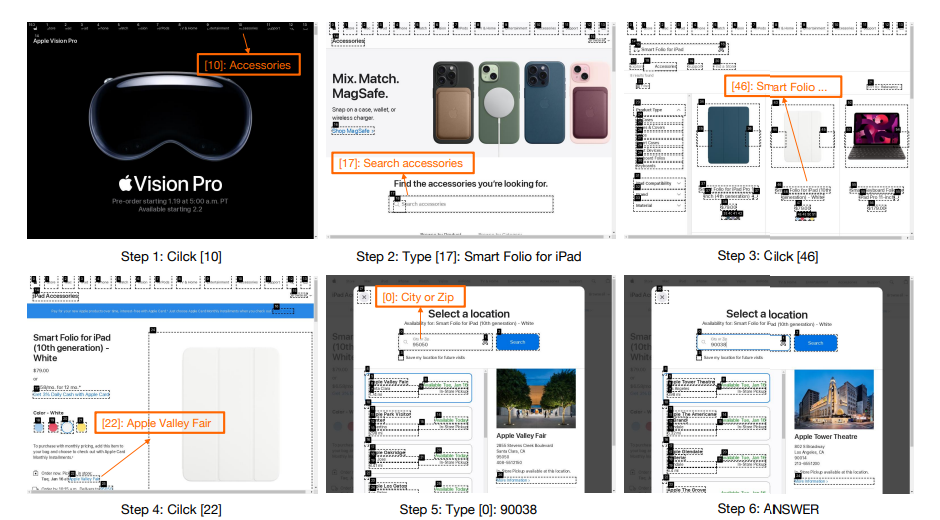
▲在线网络浏览完整轨迹的屏幕截图
Agent与Apple网站进行交互, 并获得答案:“Apple Valley Fair。”
然而,现有的Agent通常用于处理复杂且冗长的HTML文本这一单一输入模态,而忽视了可以将HTML渲染为视觉网页这一要点,并且仅在简化的网络模拟器或静态网络快照中进行评估,很大程度上限制了Agent在现实世界场景中的适用性。
腾讯AI lab提出了一种新的多模态网络Agent——WebVoyager,旨在以端到端的方式在线处理网络任务,即在没有人工介入的情况下从开始到结束自主管理整个过程。
另外还构建了一个新的评估数据集,包含来自15个常用网站的300个网络任务;并提出了一种自动评估的方法,在在线导航过程中保存屏幕截图,使用GPT-4V自动评估轨迹和最终结果,同时进行人工评估以验证结果,通过实验验证了GPT-4V评估器与人类评估的一致性,从而减轻人工评估员的负担,显著降低实验的成本。
结果显示,WebVoyager的任务成功率为55.7%, 显著优于GPT-4(All Tools)的32.7%和纯文本设置的39.0%。
论文标题:
WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models
论文链接:
https://arxiv.org/pdf/2401.13919.pdf
WebVoyager 的工作流程
WebVoyager的目标是构建一个能够在没有任何人工干预的情况下自主浏览开放网页并完成用户指令的Agent。整体工作流程如下图所示:

人类将网络任务分配给WebVoyager,它会自动在线浏览网络。在每 个步骤中,WebVoyager根据屏幕截图和文字(即网页元素的“类型”和其内容)选择操作。根据每个步骤的输入产生一个动作,然后在浏览器环境中执行该动作。这个过程会一直持续,直到agent决定停止。任务完成后,答案将返回给用户。
例如,用户查询:“在亚马逊上找到PS4 2年保修的费用。” agent与亚马逊进行在线互动,找到PS4,确定2年保修的价格,并返回“30.99美元”给用户。
接下来,将详细描述WebVoyager的细节,包括环境、交互循环、观察空间和动作空间。
1. 浏览环境的构建
WebVoyager的工作流程始于构建一个自动化的网页浏览环境。使用Selenium工具,Agent可以模拟用户的浏览行为,访问真实的网页。这个环境允许Agent像人类用户一样与浏览器窗口交互,但与本地托管的网站不同,它允许Agent探索开放的网络环境,面对实时更新、浮动广告等挑战。
2. 交互周期和决策过程
WebVoyager的决策过程是一个交互周期,Agent在每一步接收输入(包括截图和辅助文本),然后产生一个动作,该动作在浏览器环境中执行。如果动作执行期间出现异常,还会将错误信息纳入提示中,要求模型重新生成响应。这个过程持续进行,直到模型生成终止动作或达到最大步数为止。此外,为了避免长时间的导航导致的混淆,WebVoyager执行上下文裁剪,只保留最近的3个截图,并保留所有思考和动作的历史记录,以更好地指导Agent。
3. 观察空间定义
类似于人类浏览网页,Agent也将网页的视觉信息(屏幕截图)作为主要输入来源。因此观察空间包括当前的网页截图和辅助文本。通过在网页上的交互元素上叠加边框和数字标签,Agent能够更准确地确定需要交互的元素,并执行相应的动作。
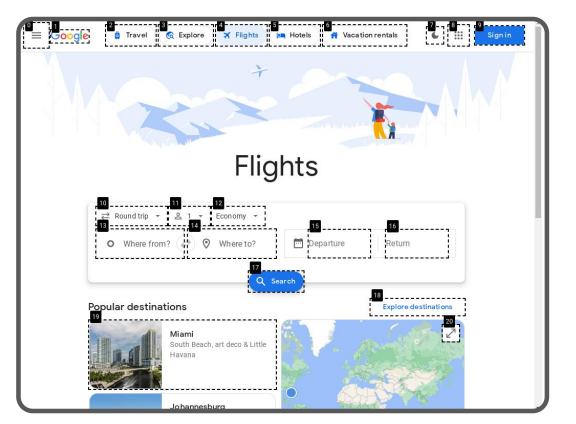
▲网页截图示例
4. 行动空间
而行动空间则定义了Agent可以执行的动作,如点击、输入、滚动、等待、返回、跳转到搜索引擎等,这都是最常用的鼠标和键盘操作,足以让Agent浏览各种网页并找到任务所需的内容。通过在屏幕截图中使用数字标签,使Agent能够以简洁的行为格式进行响应。一旦任务中的所有问题得到解答,这个动作就会结束迭代并根据任务要求提供一个答案。
实验设计
1. 选取的网站和任务多样性
为了确保评估的多样性,本文选择了15个流行且具有代表性的网站,这些网站涵盖了日常生活的不同方面。包括Allrecipes、Amazon、Apple、ArXiv、BBC News、Booking、Cambridge Dictionary、Coursera、ESPN、GitHub、Google Flights、Google Map、Google Search、Huggingface和Wolfram Alpha。其中排除了需要登录或验证码才能访问内容的网站,但这并不影响评估的有效性。此外,Google Search作为一个通用网站,可以作为任何网站的起点,使该框架适用于广泛的场景。
2. 数据集
- GAIA 数据集:从中提取了90个网页浏览任务(Level 1 和 Level 2)。GAIA 数据集中的任务没有注明具体的网站,本文指示Agent从谷歌搜索开始搜索答案。并采用主要的评估指标为任务成功率,衡量成功完成任务的能力,不考虑逐步执行是否最优。将每个任务的最大交互次数设置为15次。
- 自建数据集:数据集的构建采用了自我指导(self-instruct)方法和人工验证相结合的方式,如下图所示。首先,从Mind2Web中手动采样并重写了一些任务,然后使用GPT-4 Turbo生成约100个新任务,并对每个生成的任务进行人工验证和必要的重写,以确保其数据的高质量且答案可以在相应的网站上找到。最终收集了每个网站20个任务,共计300个任务。
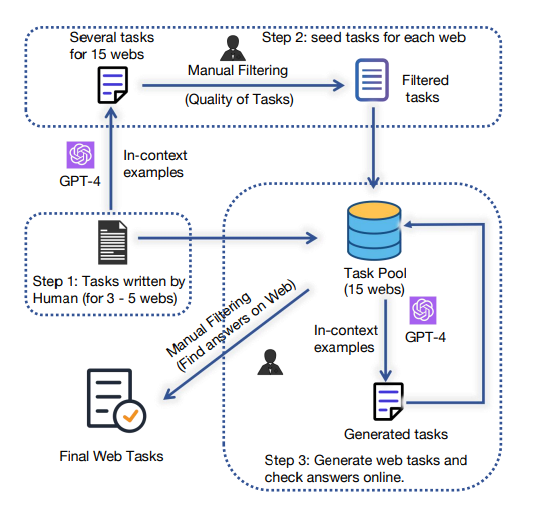
3. 评估方法
- 人类评估:人类评估作为主要的评估指标,特别是针对那些具有开放式答案的任务。具体来说,向评估者提供了Agent与网络交互的完整轨迹(所有屏幕截图和所有动作),并要求评估者提供一个二元判断,即Agent是否成功完成了任务。
- 自动评估:使用GPT-4V作为自动评估器的方法,它模仿人类评估者的行为来评估WebVoyager的导航轨迹。向评估器提供任务、WebVoyager的回答以及最后k个截图,并要求它判断Agent是否成功完成任务,其中k是一个超参数。假设GPT-4V强大的多模态推理能力使其能够作为可靠的评估器,从而减轻人工评估员的负担,显著降低未来实验的成本。
4. 基线模型
- GPT-4 (All Tools),它将视觉、网页浏览、代码分析和各种插件集成在一个模型中。
- 考虑了一个仅接收网站可访问性树作为输入并进行行为预测的文本基线。
实验结果与分析
1. 任务成功率的比较
WebVoyager在自建的数据集和提取自GAIA数据集的网络任务上均表现出色,任务成功率达到了55.7%,显著优于仅文本和GPT-4(所有工具)的基线。如下图所示,是WebVoyager在两个数据集上的主要结果。每个网站包含20个任务,在表中报告"任务成功数量"(任务成功率)WebVoyager∗的结果是由基于GPT-4V的评估器给出的(完整轨迹,kappa等于0.70)。
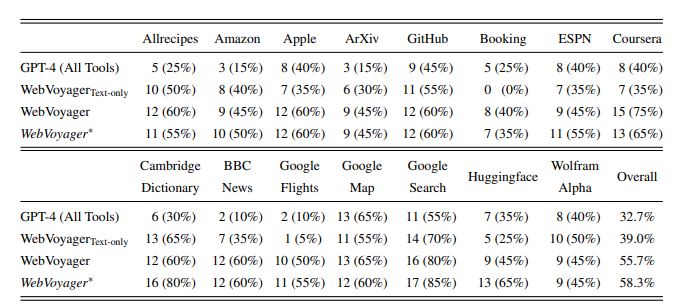
▲自建数据集上的成功率,
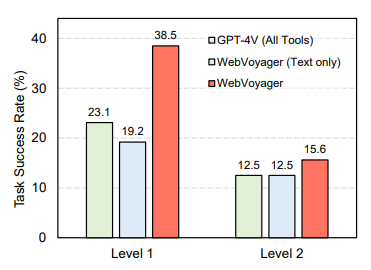
▲GAIA一级和二级任务的成功率
这一结果突显了WebVoyager在实际应用中的卓越能力。
2. 评估一致性分析
为了计算人类评估与自动评估之间的差距,本文首先计算了三名人类评注员在最终讨论前的一致性得分,发现Fleiss's Kappa为0.7,表明评注员之间达成了一致。而GPT-4V自动评估与人类评之间的一致性(重叠比率)和Kappa值如下图所示:

结果表明,GPT-4V与人类评注员的一致性随着其接收到的信息量的增加而逐渐提高,其最终的Kappa得分也达到了0.7,与人类评注员之间的一致性相当。这表明,使用GPT-4V自动评估多模态网络Agent的性能是可行的。
局限性与未来方向
1. 直接网站交互的必要性
WebVoyager作为一款先进的多模态模型(LMM)驱动的Agent,虽然在实际应用中表现出色,但其性能仍受限于直接与网站交互的能力。例如,GPT-4(All Tools)在执行任务时主要依赖于Bing搜索,而不是直接访问特定网站,这限制了其完成某些类型任务的能力。
为了提高任务成功率,未来的WebVoyager需要增强其直接与网站交互的能力,以便更准确地获取实时信息。
2. 文本与视觉信息的必要性
WebVoyager在处理文本密集型网站时存在挑战,例如在剑桥词典和Wolfram Alpha上的表现略逊于仅文本的设置。这表明,在构建通用网络Agent时,需要同时考虑文本和视觉信息。
未来的工作可以探索更好的视觉信息和文本信息的集成方法,以提高对复杂视觉元素的处理能力。
3. 面对复杂元素的挑战
WebVoyager在处理具有更多可交互元素的网站时面临更大的挑战。例如,与日历和其他复杂组件交互时,文本输入如可访问性树变得非常复杂和冗长,远不如使用屏幕截图直观。
因此,未来的WebVoyager需要能够更好地处理这些复杂元素,以提高其在各种网站上的任务成功率。
错误分析
在任务完成过程中,WebVoyager遇到了几个主要问题,这些问题对其性能产生了影响。下图统计了任务失败原因所占比例:

通过对这些问题的分析,可以在未来的工作中针对性地改进WebVoyager,以提高其在实际应用中的性能和可靠性。
1. 导航困难
WebVoyager最常见的失败模式是在完成任务之前耗尽步骤。例如,如果搜索查询不够精确和明确,Agent可能会在不相关的搜索结果中徘徊,而不是纠正其先前的操作。
给定任务:“在Allrecipes上搜索一个Beef Wellington的食谱,该食谱至少有200条评论和平均评分4.5星或更高。列出制作这道菜所需的主要配料。”
如下图所示,Agent未能正确滚动页面并找到配料。
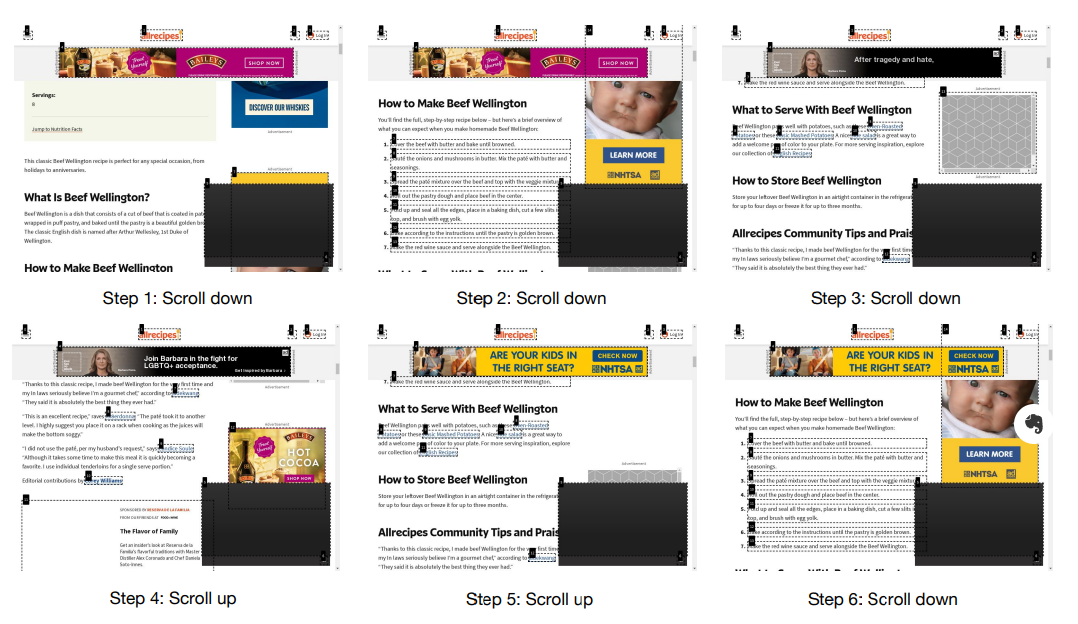
2. 提示不对齐
复杂的提示理解和遵循对WebVoyager来说是一个挑战。过长的轨迹可能导致过长的上下文,从而影响有效的指令遵循。
给定任务:“找出足球锦标赛苏格兰超级联赛中有多少支球队, 以 及Hibernian队最近一场比赛是什么时候开始的?”
Agent提供答案:“苏格兰超级联赛有12支球队。要获取Hibernian队最近一场比赛的确切开始时间,需要进一步与网站互动。” Agent知道任务尚未完成,但它提前了结束导航,即使它可以找到Hibernian队的最近一场比赛。
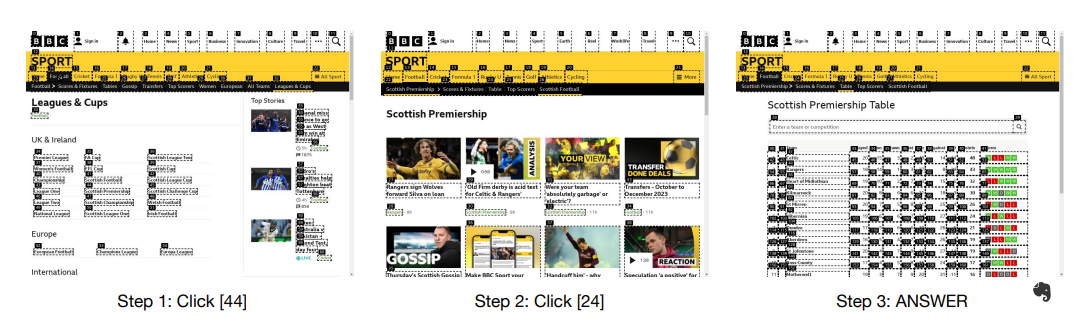
3. 视觉定位问题
WebVoyager的视觉定位能力仍有很大的提升空间。例如,Agent可能无法解释不常见的模式,或者由于相邻元素的混淆而选择错误的元素进行操作执行。
给定任务:“找出所有符合条件的单程航班中, 一位成人从JFK飞往希思罗机场的最低票价,日期为1月22日。”
Agent知道要选择1月22号,但就是无法选择正确的数字标签。

4. 幻觉错误
有时,WebVoyager可能会产生看似正确的答案,但需要仔细检查才能发现错误。例如,Agent可能忽略了任务的某些要求,提供了一个只是部分正确的答案。
给定任务:“识别一门与’人工智能在医疗保健领域的应用’相关的Coursera课程,并记录课程持续时间以及测验数量。”
Agent提供了答案:“模块1中在评估中包含3个测验。” 然而,还需要其他模块的结果,但Agent未能提供。
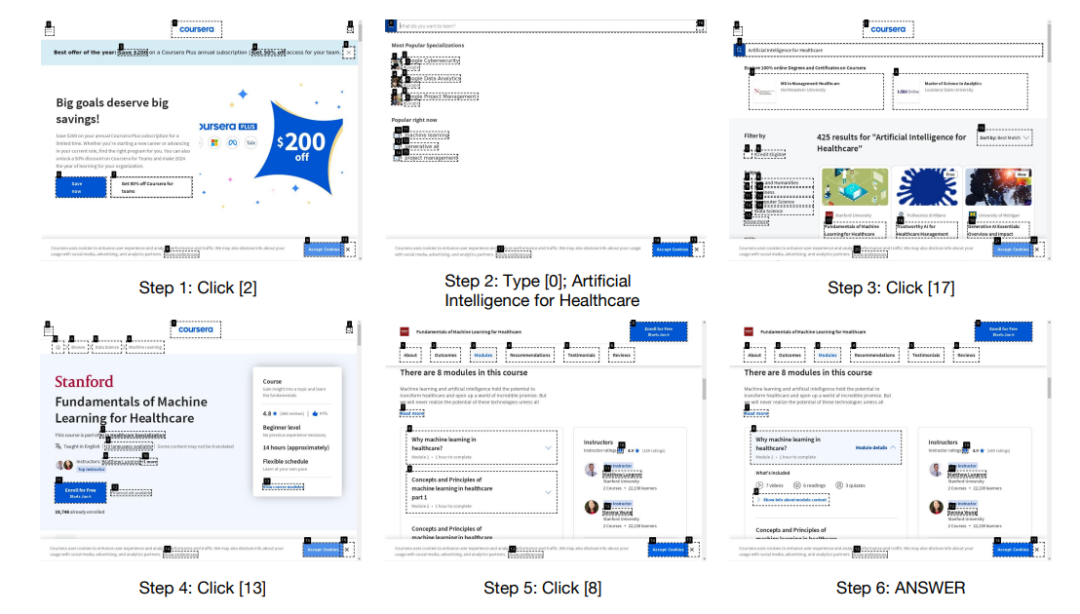
结论
WebVoyager是一个端到端的多模态Agent,从用户指令的开始到任务完成的结束,整个过程都由Agent自主管理,无需人为干预;通过整合文本和视觉信息,WebVoyager展示了在完成用户指令方面的卓越能力,其任务成功率达到了55.7%,显著超越了GPT-4 (All Tools) 和仅文本的WebVoyager 设置。
版权归原作者 AI知识图谱大本营 所有, 如有侵权,请联系我们删除。