
参考书:机器学习(周志华)
几个重要概念
信息熵
随机事件未按照某个属性的不同取值划分时的熵减去按照某个属性的不同取值划分时的平均熵。
表示事物的混乱程度,熵越大表示混乱程度越大,越小表示混乱程度越小。
对于随机事件,如果当前样本集合D中第k类样本所占的比例为
p
k
{p_k}
pk,那么D的信息熵为:

我们需要选择熵最小的。
信息增益——ID3
考虑到不同的分支结点所包含的样本数不同,我们给分支结点赋予权重|
D
v
{D^v}
Dv| / |
D
D
D|,可计算出用**属性a**对样本集D进行**划分**所获得的信息增益:

一般来说,信息增益越大,使用属性a 来进行划分所获得的“纯度提升”越大,因此我们需要选择信息增益最大的
信息增益率——C4.5
信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,我们考虑属性a的取值数目,
其中
增益率准则对可取值数目较少的属性有所偏好,在选择时,先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的
基尼系数——CART
数据集D的纯度可用基尼值来度量,它反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率,因此,Gini(D)越小,数据集D的纯度越高

属性a的基尼指数定义为:
我们在候选属性集合A中,选择那个使得划分后基尼指数最小的属性作为最优划分属性。
例题
其实主要还是
背公式+计算不出错
,步骤基本上都差不多
(20年期末)设训练集如下表所示,请用经典的 ID3 算法 完成其学习过程。

题目还给出了: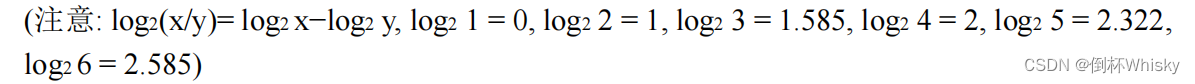
使用ID3算法就只需要计算信息增益就好了,计算步骤如下:
**
STEP1
** 第一步需要计算出集合D的总信息熵
在决策树学习开始时,根结点包含D中的所有样例,其中正例占
p
1
p_1
p1 =
3
6
3 \over 6
63 =
1
2
1 \over 2
21,反例占
p
2
p_2
p2=
1
2
1 \over 2
21,于是根结点的信息熵为:
Ent(D) = -(
1
2
1 \over 2
21 log2
1
2
1 \over 2
21 +
1
2
1 \over 2
21 log2
1
2
1 \over 2
21) = 1
**
STEP2
** 接下来计算每个属性的信息熵
属性
x
1
{x_1}
x1:包含
D
1
{D^1}
D1(T)和
D
2
{D^2}
D2(F),各占
1
2
1 \over 2
21
D
1
{D^1}
D1(T):正例占
p
1
p_1
p1 =
2
3
2 \over 3
32,反例占
p
2
p_2
p2=
1
3
1 \over 3
31
**Ent(
D
1
{D^1}
D1) = -(
2
3
2 \over 3
32 log2
2
3
2 \over 3
32 +
1
3
1 \over 3
31 log2
1
3
1 \over 3
31) = 0.9183**
D
2
{D^2}
D2(F):正例占
p
1
p_1
p1 =
1
3
1 \over 3
31,反例占
p
2
p_2
p2=
2
3
2 \over 3
32
**Ent(
D
2
{D^2}
D2) = -(
1
3
1 \over 3
31 log2
1
3
1 \over 3
31 +
2
3
2 \over 3
32 log2
2
3
2 \over 3
32) = 0.9183**
因此**Ent(
x
1
{x_1}
x1) =
1
2
1 \over 2
21Ent(
D
1
{D^1}
D1) +
1
2
1 \over 2
21Ent(
D
2
{D^2}
D2) = 0.9183**
属性
x
2
{x_2}
x2:包含
D
1
{D^1}
D1(T)和
D
2
{D^2}
D2(F),分别占
2
3
2 \over 3
32和
1
3
1 \over 3
31
D
1
{D^1}
D1(T):正例占
p
1
p_1
p1 =
1
2
1 \over 2
21,反例占
p
2
p_2
p2=
1
2
1 \over 2
21
**Ent(
D
1
{D^1}
D1) = -(
1
2
1 \over 2
21 log2
1
2
1 \over 2
21 +
1
2
1 \over 2
21 log2
1
2
1 \over 2
21) = 1**
D
2
{D^2}
D2(F):正例占
p
1
p_1
p1 =
1
2
1 \over 2
21,反例占
p
2
p_2
p2=
1
2
1 \over 2
21
**Ent(
D
2
{D^2}
D2) = -(
1
2
1 \over 2
21 log2
1
2
1 \over 2
21 +
1
2
1 \over 2
21 log2
1
2
1 \over 2
21) = 1**
因此**Ent(
x
2
{x_2}
x2) =
2
3
2 \over 3
32Ent(
D
1
{D^1}
D1) +
1
3
1 \over 3
31Ent(
D
2
{D^2}
D2) = 1**
**
STEP3
** 最后计算每个属性的信息增益
Gain(D,
x
1
{x_1}
x1)=Ent(D) - Ent(
x
1
{x_1}
x1) = 1 - 0.9183 = 0.0817
Gain(D,
x
2
{x_2}
x2)=Ent(D) - Ent(
x
2
{x_2}
x2) = 1-1 = 1
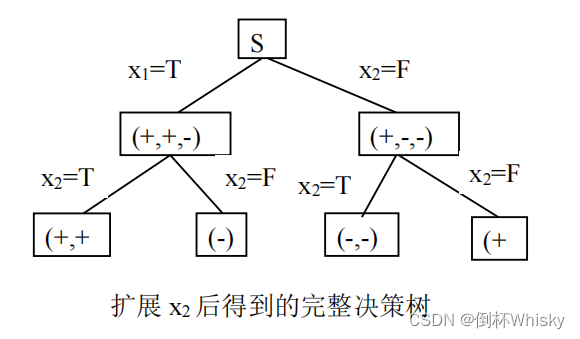
选择信息增益大的作为第一个属性,即选择属性
x
1
{x_1}
x1对根节点进行扩展
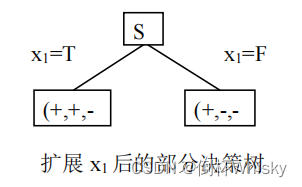
扩展
x
1
{x_1}
x1之后还未得到最终方案结果,只剩
x
2
{x_2}
x2属性可拓展,因此不需要再进行条件熵的计算,对
x
2
{x_2}
x2扩展后所得到的决策树如下图所示:
(19年)下表给出外国菜是否有吸引力的数据集,每个菜品有 3 个属性“温度”、“口味”,“份量”,请用决策树算法画出决策树(根据信息增益)。并预测 dish= {温度=热,口味=甜,份量=大} 的一道菜,是否具有吸引力。

这题也是根据信息增益选择属性,和上一题步骤一样
**
STEP1
** 第一步计算出集合D的总信息熵
根结点包含10个样例,其中正例占
p
1
p_1
p1 =
1
2
1 \over 2
21 ,反例占
p
2
p_2
p2=
1
2
1 \over 2
21,于是根结点的信息熵为:
Ent(D) = -(
1
2
1 \over 2
21 log2
1
2
1 \over 2
21 +
1
2
1 \over 2
21 log2
1
2
1 \over 2
21) = 1
**
STEP2
** 接下来计算每个属性的条件熵
温度属性:包含
D
1
{D^1}
D1(冷)和
D
2
{D^2}
D2(热),各占
1
2
1 \over 2
21
D
1
{D^1}
D1(冷):正例占
p
1
p_1
p1 =
3
5
3 \over 5
53,反例占
p
2
p_2
p2=
2
5
2 \over 5
52
**Ent(
D
1
{D^1}
D1) = -(
3
5
3 \over 5
53 log2
3
5
3 \over 5
53 +
2
5
2 \over 5
52 log2
2
5
2 \over 5
52) = 0.971**
D
2
{D^2}
D2(热):正例占
p
1
p_1
p1 =
2
5
2 \over 5
52,反例占
p
2
p_2
p2=
3
5
3 \over 5
53
**Ent(
D
2
{D^2}
D2) = -(
2
5
2 \over 5
52 log2
2
5
2 \over 5
52 +
3
5
3 \over 5
53 log2
3
5
3 \over 5
53) = 0.971**
因此**Ent(温度) =
1
2
1 \over 2
21Ent(
D
1
{D^1}
D1) +
1
2
1 \over 2
21Ent(
D
2
{D^2}
D2) = 0.971**
份量属性:包含
D
1
{D^1}
D1(大)和
D
2
{D^2}
D2(小),各占
1
2
1 \over 2
21
D
1
{D^1}
D1(冷):正例占
p
1
p_1
p1 =
1
5
1 \over 5
51,反例占
p
2
p_2
p2=
4
5
4 \over 5
54
**Ent(
D
1
{D^1}
D1) = -(
1
5
1 \over 5
51 log2
1
5
1\over 5
51 +
4
5
4 \over 5
54 log2
4
5
4 \over 5
54) = 0.722**
D
2
{D^2}
D2(热):正例占
p
1
p_1
p1 =
4
5
4 \over 5
54,反例占
p
2
p_2
p2=
1
5
1 \over 5
51
**Ent(
D
2
{D^2}
D2) = -(
4
5
4 \over 5
54 log2
4
5
4 \over 5
54 +
1
5
1 \over 5
51 log2
1
5
1 \over 5
51) = 0.722**
因此**Ent(份量) =
1
2
1 \over 2
21Ent(
D
1
{D^1}
D1) +
1
2
1 \over 2
21Ent(
D
2
{D^2}
D2) = 0.722**
口味属性:包含
D
1
{D^1}
D1(咸)和
D
2
{D^2}
D2(甜)和
D
3
{D^3}
D3(酸),分别占
3
10
3 \over 10
103、
4
10
4 \over 10
104和
3
10
3 \over 10
103
D
1
{D^1}
D1(咸):正例占
p
1
p_1
p1 = 0,反例占
p
2
p_2
p2= 1
**Ent(
D
1
{D^1}
D1) = 0**
D
2
{D^2}
D2(甜):正例占
p
1
p_1
p1 =
1
2
1 \over 2
21,反例占
p
2
p_2
p2=
1
2
1 \over 2
21
**Ent(
D
2
{D^2}
D2) = -(
1
2
1 \over 2
21 log2
1
2
1 \over 2
21 +
1
2
1 \over 2
21 log2
1
2
1 \over 2
21) = 1**
D
3
{D^3}
D3(酸):正例占
p
1
p_1
p1 = 1,反例占
p
2
p_2
p2= 0
**Ent(
D
3
{D^3}
D3) = 0**
因此**Ent(口味) =
3
10
3 \over 10
103Ent(
D
1
{D^1}
D1) +
4
10
4 \over 10
104Ent(
D
2
{D^2}
D2) +
3
10
3 \over 10
103Ent(
D
3
{D^3}
D3)= 0.4**
**
STEP3
** 最后计算每个属性的信息增益
Gain(D,温度)=Ent(D) - Ent(温度 = 1 - 0.971= 0.029
Gain(D,份量)=Ent(D) - Ent(份量) = 1 - 0.722 = 0.278
Gain(D,口味)=Ent(D) - Ent(口味) = 1 - 0.4= 0.6
选择信息增益大的作为第一个属性,即选择口味属性对根节点进行扩展,第二层选择份量属性,最后选择温度属性,画出的决策树如下
也可以只在口味=甜的时候选择下一个属性是“份量”还是“温度”,因为口味=酸的时候已经可以得出结果为“是”,口味为咸的时候已经可以得出结果为“否”。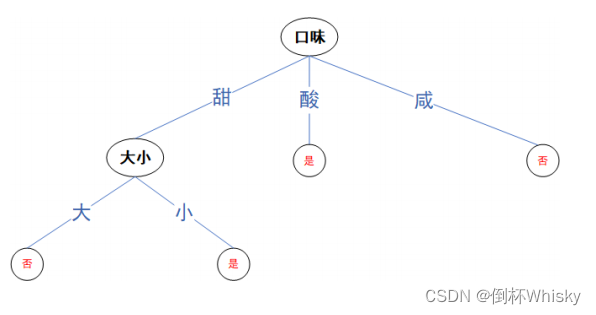
预测 dish= {温度=热,口味=甜,份量=大},根据决策树可以预测结果为“否”。
剩下的题我就不具体写了,大家可以自己练练手。
(18年期末)下表为是否适合打垒球的决策表,请用决策树算法画出决策树,并请预测 E= {天气=晴,温度=适中,湿度=正常,风速=弱} 的场合,是否合适打垒球。

画出的决策树如下
(17年期末)设使用ID3算法进行归纳学习的输入实例集S={ i | 1≤ i ≤ 7 }如下表所示。学习的目标是用属性A、B、C预测属性F。
(1)写出集合S分别以属性A、B、C作为测试属性的熵的增益Gain(S, A)、Gain(S, B)、Gain(S, C)的表达式。
(2)属性A、B、C中哪个应该作为决策树根节点的测试属性?

(1)
Gain(S, A)=0.067、Gain(S, B)=0.128、Gain(S, C)=0.522
(2)C作为根节点,AB位置可互换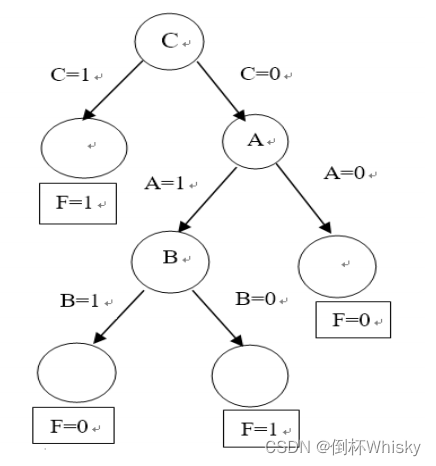
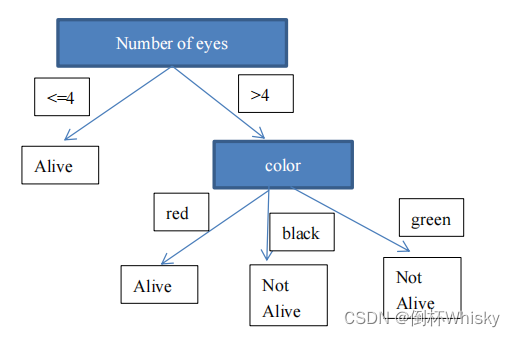
(22年秋期末)你的飞船刚刚降落在一个外星星球上,你的船员已经开始调查当地的野生动物。不幸的是,你的大多数科学设备都坏了,所以你只能知道一个物体是什么颜色,它有多少只眼睛,它是否活着。更糟糕的是,你们都不是生物学家,所以你们必须使用决策树来将着陆点附近的物体分类为活着或不活着。使用下表回答以下问题:
(1)下列哪个熵值最大?
H(Alive|eyes>10), H(Alive|eyes<10), H(Alive|color=green), H(Alive|color=black)
(2)计算信息增益值 IG(Alive|color);
(3)假设我们想将“眼睛数”转换为一个二进制属性,以构建决策树。以下哪种二元分类划分导致 IG(活眼数)值更大?
(a) {Number of eyes = 11, Number of eyes != 11},
(b) {Number of eyes <= 4, Number of eyes > 4},
(c) {Number of eyes <= 13, Number of eyes > 13}
(4)按照信息熵理论根据上一问的二元划分构造一个决策树并对下面的例子进行分类
(a) A red object with 23 eyes,
(b) A black object with 1.5 eyes

考虑下面一个数据集,它记录了某学生多次考试的情况,请根据提供的数据按要求构建决策树。
(1)根据信息增益率选择第一个属性,构建一个深度为1的决策树(根结点深度为1)。
(2)根据信息增益率构建完整的决策树。请回答,这两个决策树的决策结果是否和训练数据一致,并解释说明。

设样本集合如下表格,其中A、B、C是F的属性,请根据信息增益标准(ID3算法),画出F的决策树。

版权归原作者 倒杯Whisky 所有, 如有侵权,请联系我们删除。