
随着Sora的发布,大模型的发展速度不仅没有遇到瓶颈,反而进一步加速了,AGI正在向我们招手。
而在这背后,不论是文本、音频、视频还是视频的大模型处理,Prompt——这个看似简单的概念,却扮演着至关重要的角色。
Prompt是大语言模型与用户之间的桥梁,一个精心设计的Prompt不仅可以帮助模型更准确地捕捉用户意图,还能激发模型的创造力和想象力,从而生成更加丰富多彩的内容。
然而,如何设计出一个有效的Prompt却是一项充满挑战的任务。它需要我们对模型的工作原理有深入的了解,同时还需要具备创造性和想象力。因此,掌握Prompt的设计技巧对于充分发挥大语言模型的潜力至关重要。
接下来将深入探讨大语言模型中的Prompt设计。我们将从Prompt的基本原理和重要性入手,分享实用的设计技巧和方法,并通过案例分析来展示Prompt在不同场景下的应用。无论你是对人工智能感兴趣的普通读者,还是正在从事相关领域研究的专家学者,相信这系列文章都会给你带来全新的启发和收获。让我们一起探索Prompt的奥秘,共同见证大语言模型的无限可能!
Prompt是如何影响输出的
1. 什么是Prompt
Prompt,指的是给予模型的输入文本或指令,用以引导模型生成特定类型或符合特定要求的输出。Prompt不仅仅是一个简单的开始或引导语句,它实际上是模型理解和生成文本的关键。
Prompt的设计可以非常多样,从简单的几个词到一个完整的句子或段落,都可以作为Prompt。其目的在于为模型提供足够的信息,以便它能够理解并生成符合期望的输出。
ChatGPT的出现,改变了传统机器的交互方式,使得每个人都可以与AI进行自然、直观的交互,而且更加简便和高效。然而,Prompt也有好坏之分。一个好的Prompt,能产生更加有创意符合预期的输出,一个不好的Prompt,则可能输出的内容偏离主题或质量不高。
如何创作出优秀的Prompt,实现AI的高效沟通,就需要对LLM的工作原理有必要的了解。
2. LLM的工作原理
2.1文本输入与编码
当我们提供Prompt给大模型时,通常是一个简短的文本描述,用以告诉模型实现的意图和输出的方式。例如:

大模型并不能直接理解该内容,需要进行必要的“翻译”。该过程包含文本编码和词嵌入。
文本编码(Tokenizer)
Tokenizer会首先对这个Prompt进行分词,将其拆分成一系列的Token。对于中文文本,分词是一个关键步骤,因为中文单词不像英文那样有明显的空格分隔。

每个Token代表一个单词或标点符号。
词嵌入(Word Embedding)
每个Token都会被映射到一个固定大小的向量。这个向量是词嵌入的结果,它捕捉了Token的语义信息。
以“西安”这个Token为例,它会被映射到一个向量,这个向量在训练过程中学会了与“中国”、“陕西”、“古都”等词在语义上的关联。
这些向量作为模型的输入,帮助模型理解文本的含义,并在生成关于西安城墙历史的介绍时,能够考虑这些语义关联。
2.2 上下文处理
模型将编码后的Prompt作为上下文输入。这个上下文会被编码成一个或多个向量,这些向量捕捉了Prompt中的关键信息。
而大模型基座Transformer的自注意力机制会捕捉文本中的依赖关系和复杂模式。
2.3 生成过程
通过贪婪搜索或集束搜索,模型会考虑候选Token,并选择其中概率最高的生成。
在生成每个Token时,模型都会基于之前的上下文和已生成的文本进行预测。
2.4 输出文本
当模型达到预设的长度限制或结束标记时,生成过程会停止。最终,模型会输出生成的文本,并进行格式化、调整长度、筛选信息。
3. Prompt的使用要求
优质Prompt是启发自然语言模型生成高质量文本的关键因素之一。优质的Prompt可以帮助模型更好地理解用户的意图和需求,从而生成更加准确、自然、有用的文本。
提供明确的上下文信息
优质 Prompt 应该提供清晰的上下文信息,以帮助模型更好地理解用户的意图和需求。这可以包括问题的背景、任务的目标、相关的实体和关系等。
含有足够的信息量
优质 Prompt 应该包含足够的信息量,以确保生成的文本能够准确、完整地回答用户的问题或满足用户的需求。如果 Prompt 包含不够的信息,模型可能会生成不准确或不完整的文本。
使用自然语言
优质 Prompt 应该使用自然、流畅的语言,以使模型能够更好地理解和生成文本。如果 Prompt 包含不自然、含糊或错误的语言,模型可能会生成不准确或不自然的文本。
满足特定的任务需求
优质 Prompt 应该根据具体的任务需求进行设计和优化,以确保生成的文本能够满足特定的需求。不同的任务可能需要不同的 Prompt 设计和优化策略。
通用性和稳定性
优质的Prompt替换任务主体,应该同样可以得出不错的效果,而且相同提示词,多次的生成内容比较稳定。
Prompt的规则规范
1. Prompt提示规范
Prompt的创作遵循一定的格式,通用的格式如下:

- 角色:大模型所扮演的角色
- 任务:大模型所要执行的任务
- 细节:大模型执行任务时的更加细节的要求,可添加多个,权重依次降低
- 形式:生成格式的说明,排版等


2. Prompt开发步骤
2.1确定基础
通过【角色】+ 【任务】先确定能否生成正确的答案,然后再逐步进行优化。
在LLM的训练过程中,训练数据的来源大多来源于互联网,可能会因为数据及其标签等的原因导致无法获取正确的答案。由于Prompt的问题表达不够清晰,比如分隔符等等,导致无法获取正确的答案。


2.2关注顺序
在模型训练的过程中,会针对关键词按照顺序设置权重。因而在编写Prompt时,需要将重要的key放在前面。

2.3 添加强调
编写Prompt时,有时为了更加清晰、细节的描述问题,会书写更多的关键词,而LLM在分析时有时会遗漏,从而导致结果不够准确。此时针对于一些必要的key,需要设置一些强调词予以提醒LLM。

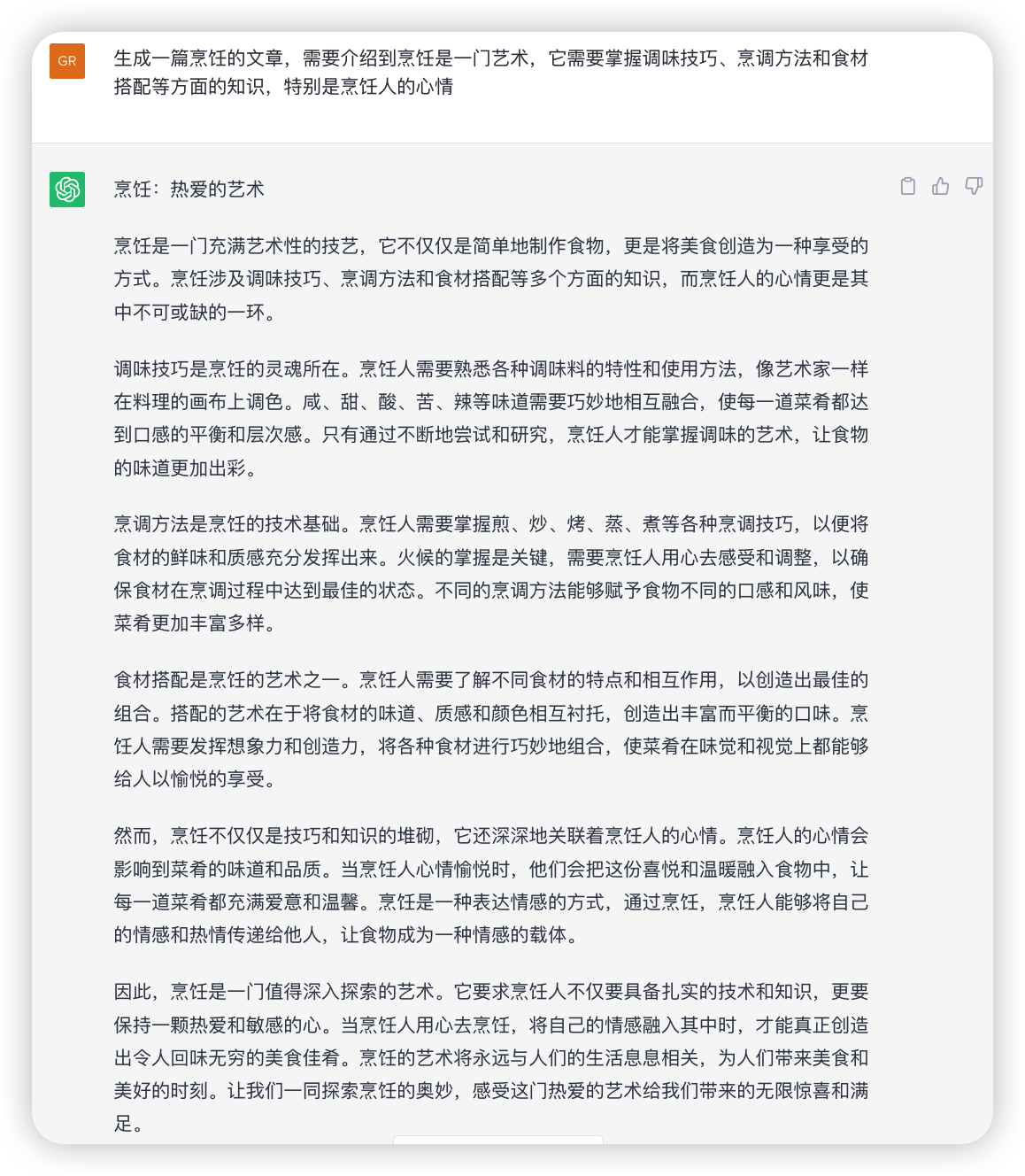
2.4 建立人设
使用“假设你是……”“你扮演一个……”“模仿……”“我希望你充当……”这样的关键字开头。在模型训练时,会将数据根据不同的场景根据标签进行分类,设置人设其实时为了更加贴近标签从而使结果更加准确。


Prompt高级
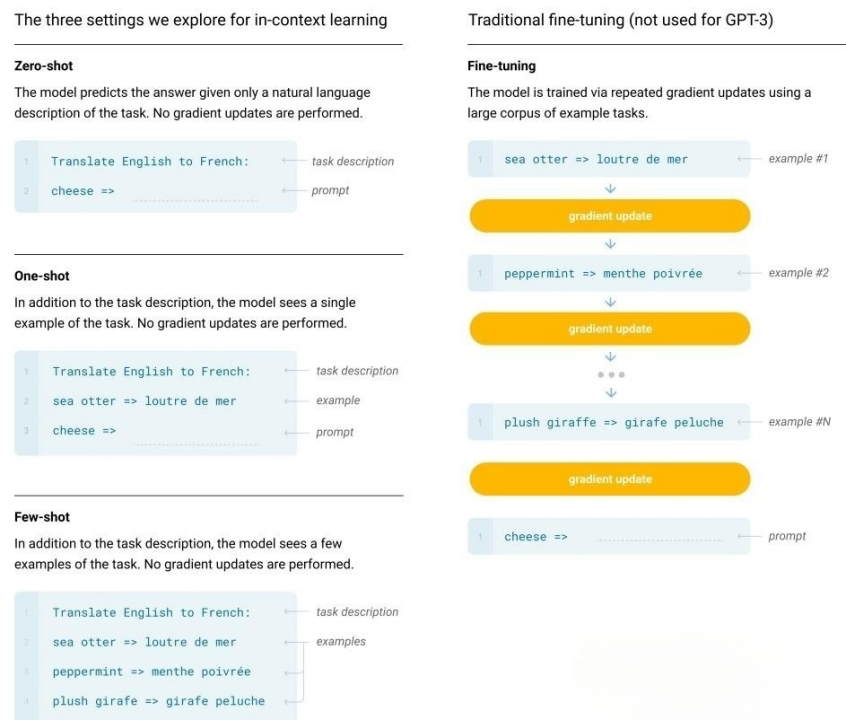
1. ICL
In-Context learning(ICL)最早在GPT-3中提出, 旨在从训练集中挑选少量的标注样本,设计任务相关的指令形成提示模板,用于指导测试样本生成相应的结果。
** ICL分为:**
few-shot learning
one-shot learning
zero-shot learning

2. CoT
大模型的魅力,在于大模型展现出的概念推理能力。能够根据几个已知的前提推导得出新的结论的过程。区别于理解,推理一般是一个“多步骤”的过程,推理的过程可以形成非常必要的“中间概念”,这些中间概念将辅助复杂问题的求解。
2.1 CoT概念
2022 年,在 Google 发布的论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中首次提出,通过让大模型逐步参与将一个复杂问题分解为一步一步的子问题并依次进行求解的过程可以显著提升大模型的性能。而这一系列推理的中间步骤就被称为思维链(Chain of Thought)。
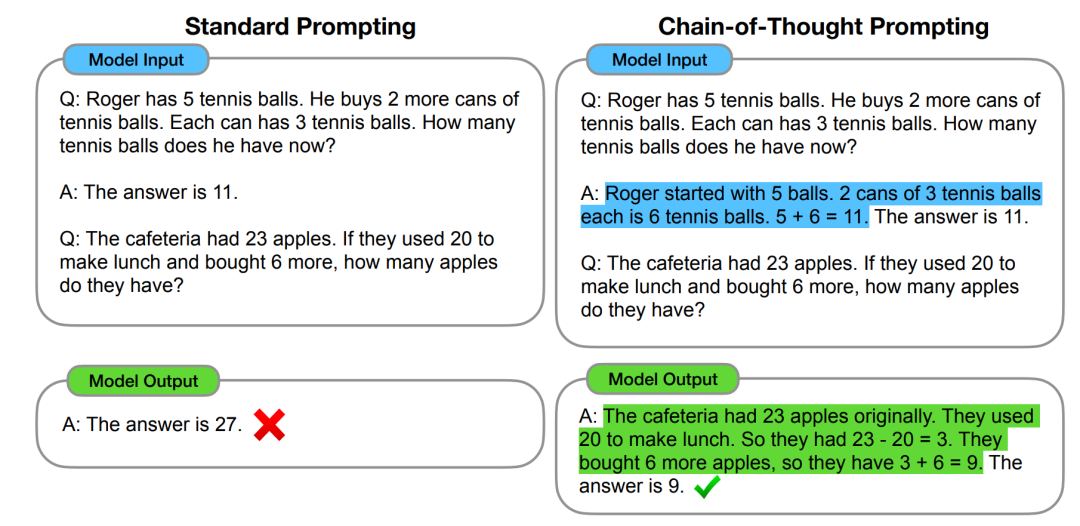
2.2 CoT的工作流程

一个完整的包含 CoT 的 Prompt 往往由指令(Instruction),逻辑依据(Rationale),示例(Exemplars)三部分组成。
指令用于描述问题并且告知大模型的输出格式,逻辑依据即指 CoT 的中间推理过程,可以包含问题的解决方案、中间推理步骤以及与问题相关的任何外部知识,而示例则指以少样本的方式为大模型提供输入输出对的基本格式,每一个示例都包含:问题,推理过程与答案。
CoT 也可以根据是否需要示例分为 Zero-Shot-CoT 与 Few-Shot-CoT。而Zero-Shot-CoT 仅仅在指令中添加“Let's think step by step”,就可以“唤醒”大模型的推理能力。
2.3 CoT示例

3. Prompt模板
通过设置和优化完成Prompt之后,可能通过替换角色和任务,检测答案的稳定性并建立模版,方便后续的使用。
总结
前面我们介绍了Prompt的基本准则和如何编写Prompt。随着技术的不断进步,大型语言模型将继续在各个领域发挥重要作用。无论是用于生成文章、摘要、代码,还是用于聊天机器人、智能助手等场景,Prompt也将继续发挥他的魅力。
接下来我们将通过具体案例和步骤,指导读者如何动手编写Prompt,并分享在实际操作中可能遇到的挑战和解决方案。
为开发者提供
高性能、易于使用、极具性价比的算力服务
版权归原作者 幕僚智算 所有, 如有侵权,请联系我们删除。