
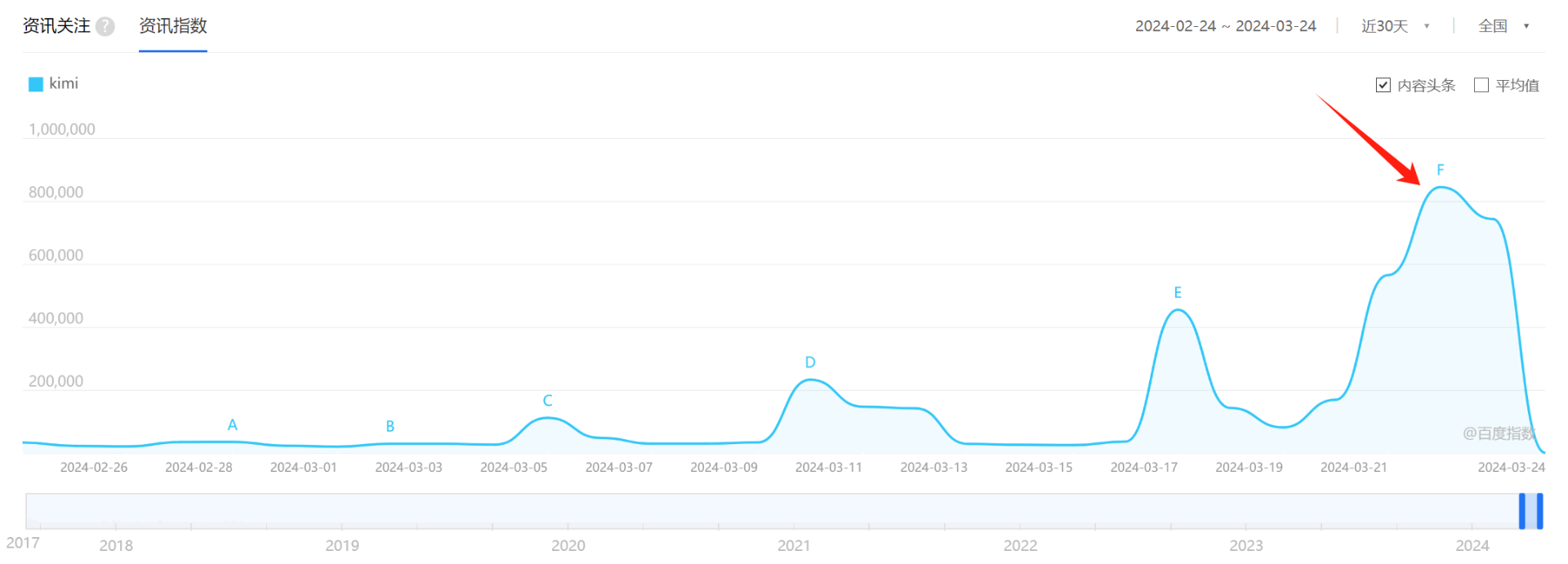
最近几天微信、知乎到处都是Kimi.ai的推荐,特意去查了一下百度指数,确实是口碑爆了,热度极高。
产品背景
公司叫月之暗面(Moonshot AI),成立于2023年3月,创始人90后、清华系背景,美团、阿里、小红书等都有投资,24年3月最新估值25亿美金。
创新点:支持超大输入
号称全球首个支持20万字输入的LLM,OpenAI的GPT-4-32k支持约2.5万字,GPT-4Turbo-128k约为10万汉字。 直接输入一本《后宫甄嬛传》,155万字符。
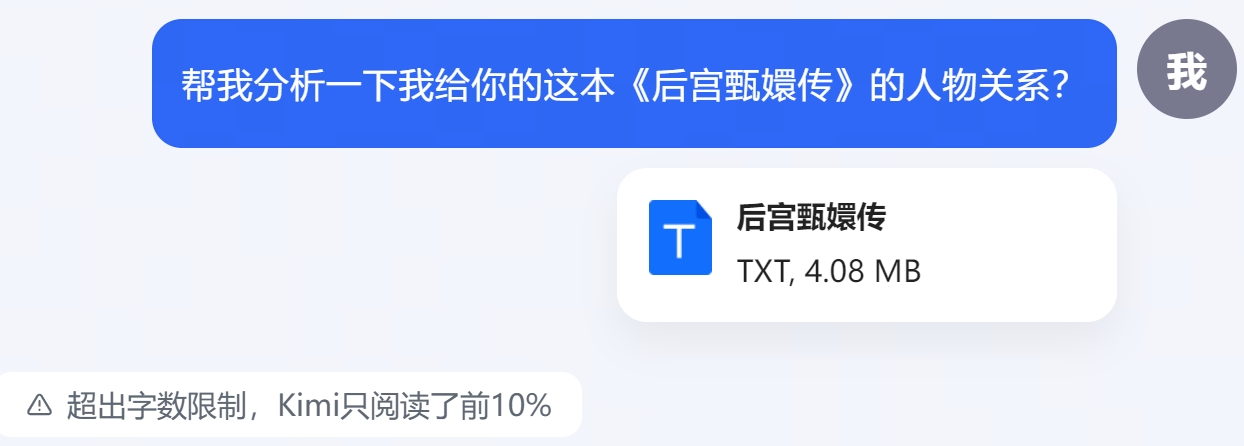

除了长篇小说以外,大部分书籍其实都在10-20万字之间,Kimi基本可以满足需求。
超长文本、超大数据肯定是未来生产力的发展方向。作为数据行业从业者,希望未来大模型能直接处理海量数据,真正实现自然语言编程。
创新点:支持联网
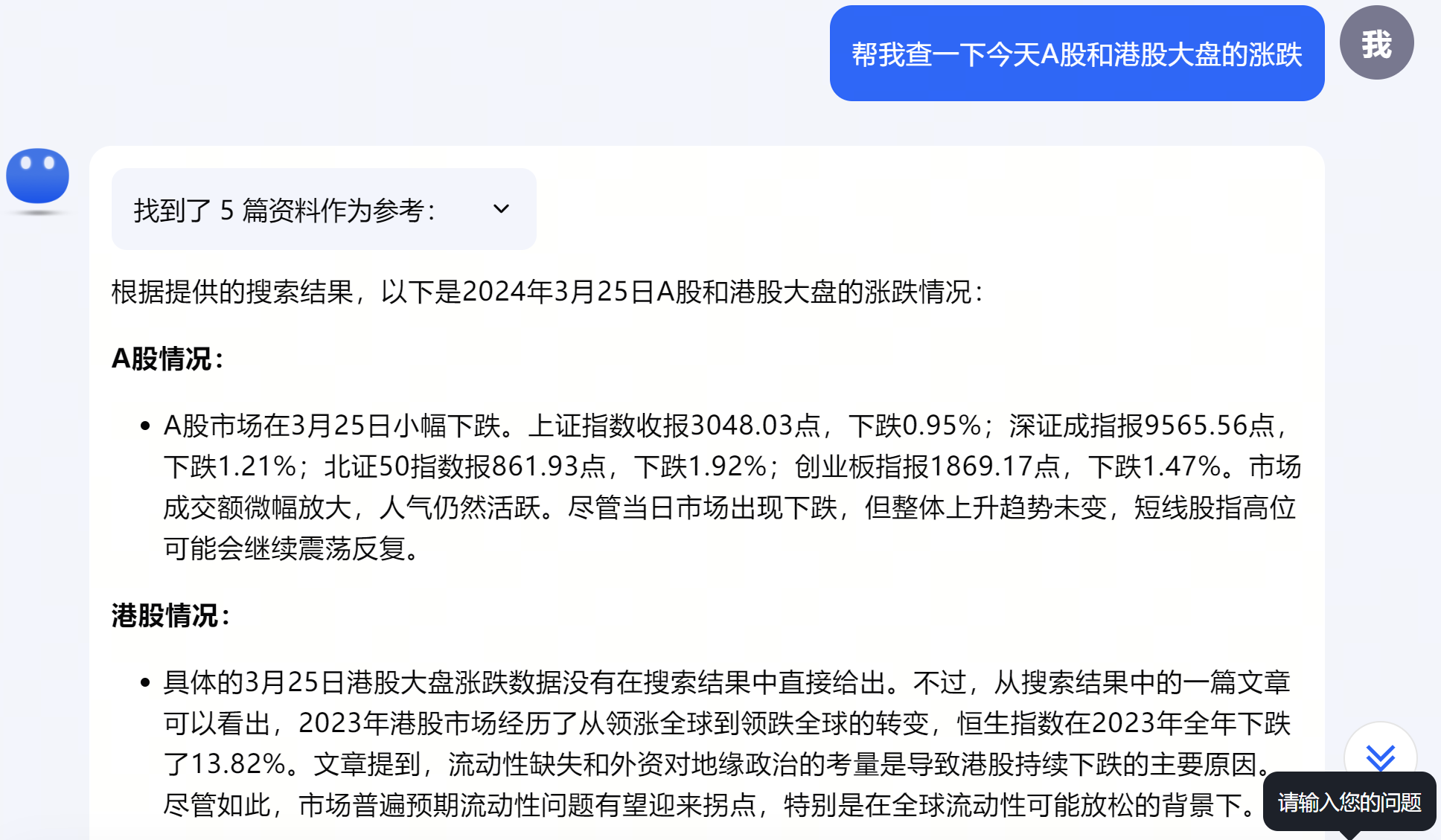
Kimi搜索了5篇互联网文章,并且阅读以后,给出了3月25号当天的股市情况。
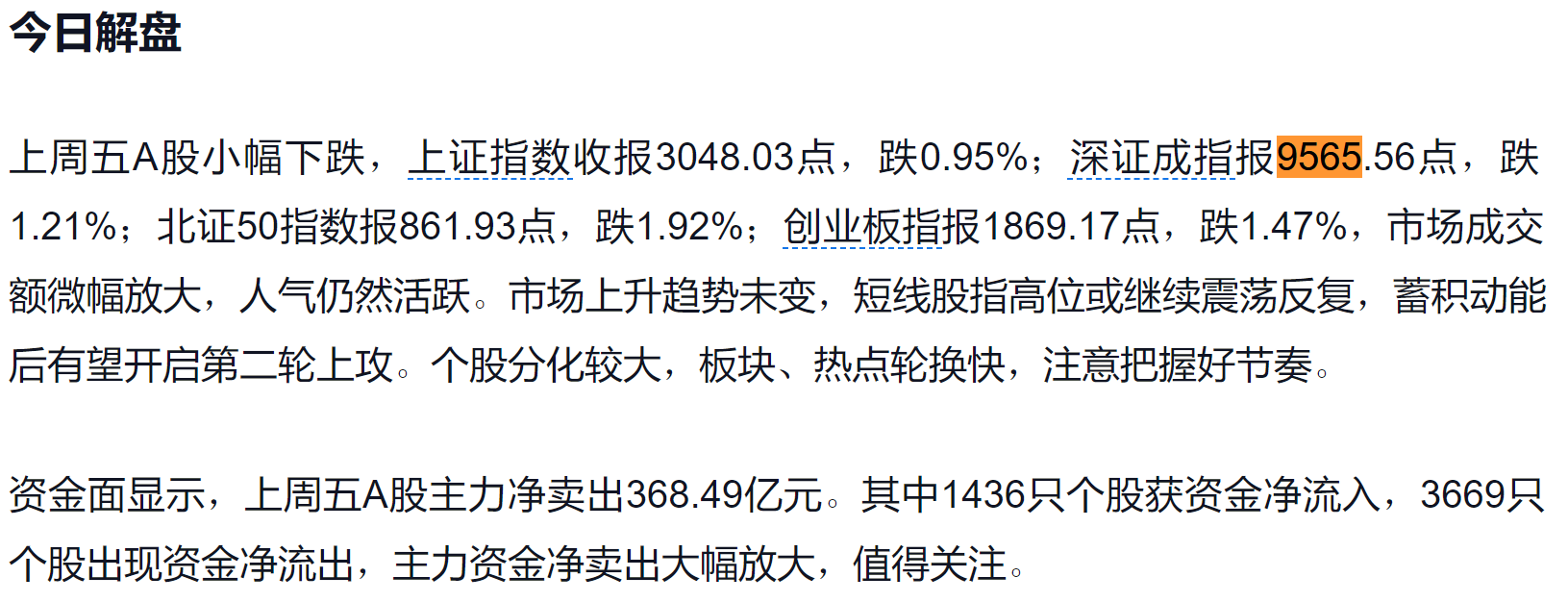
实际答案是错误的,原因是Kimi阅读了一篇3月25日当天写的文章,里面提到了上周五的收盘情况,Kimi引用了错误的数据。
测了其它大模型,也会犯一样的错误,所以答案不准确是当前大模型的通病,说明人工审核和校正还是非常重要。
造成错误的报道:A股早报2024年3月25日星期一
生产力工具:信息检索
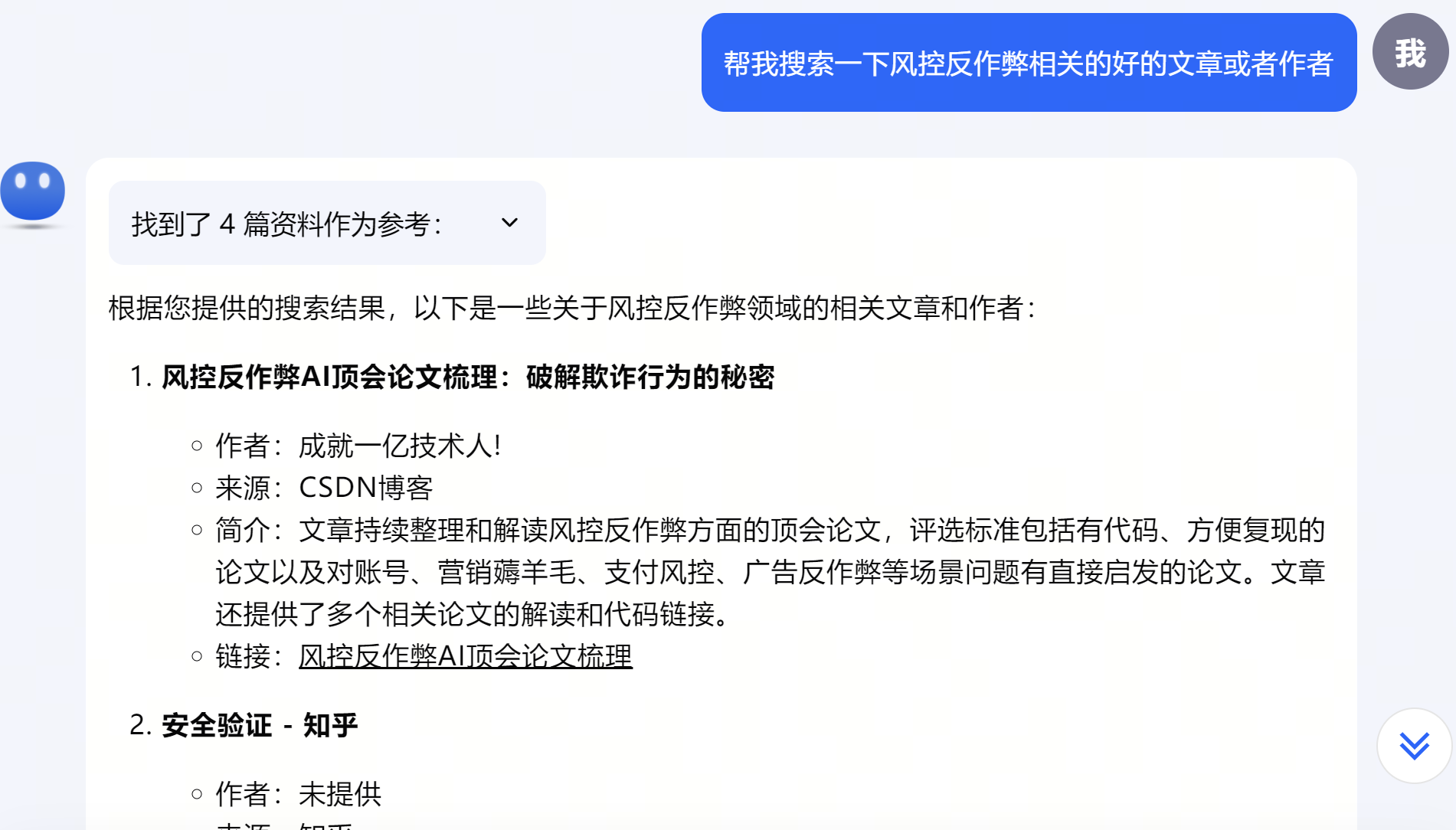
Kimi风控反作弊类Top1-风控反作弊AI顶会论文梳理 是3月21日我写的文章,很高兴能被Kimi Top1推荐。
对比百度、Google和其它大模型的输出,猜测Kimi后台应该是自建了搜索引擎,其中CSDN的权重比较高。
生产力工具:代码生成

from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建决策树分类器实例
clf = DecisionTreeClassifier(random_state=42)
# 训练模型
clf.fit(X_train, y_train)
# 进行预测
y_pred = clf.predict(X_test)
# 评估结果
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")
report = classification_report(y_test, y_pred)
print("Classification Report:")
print(report)
比较完整的代码,符合预期。

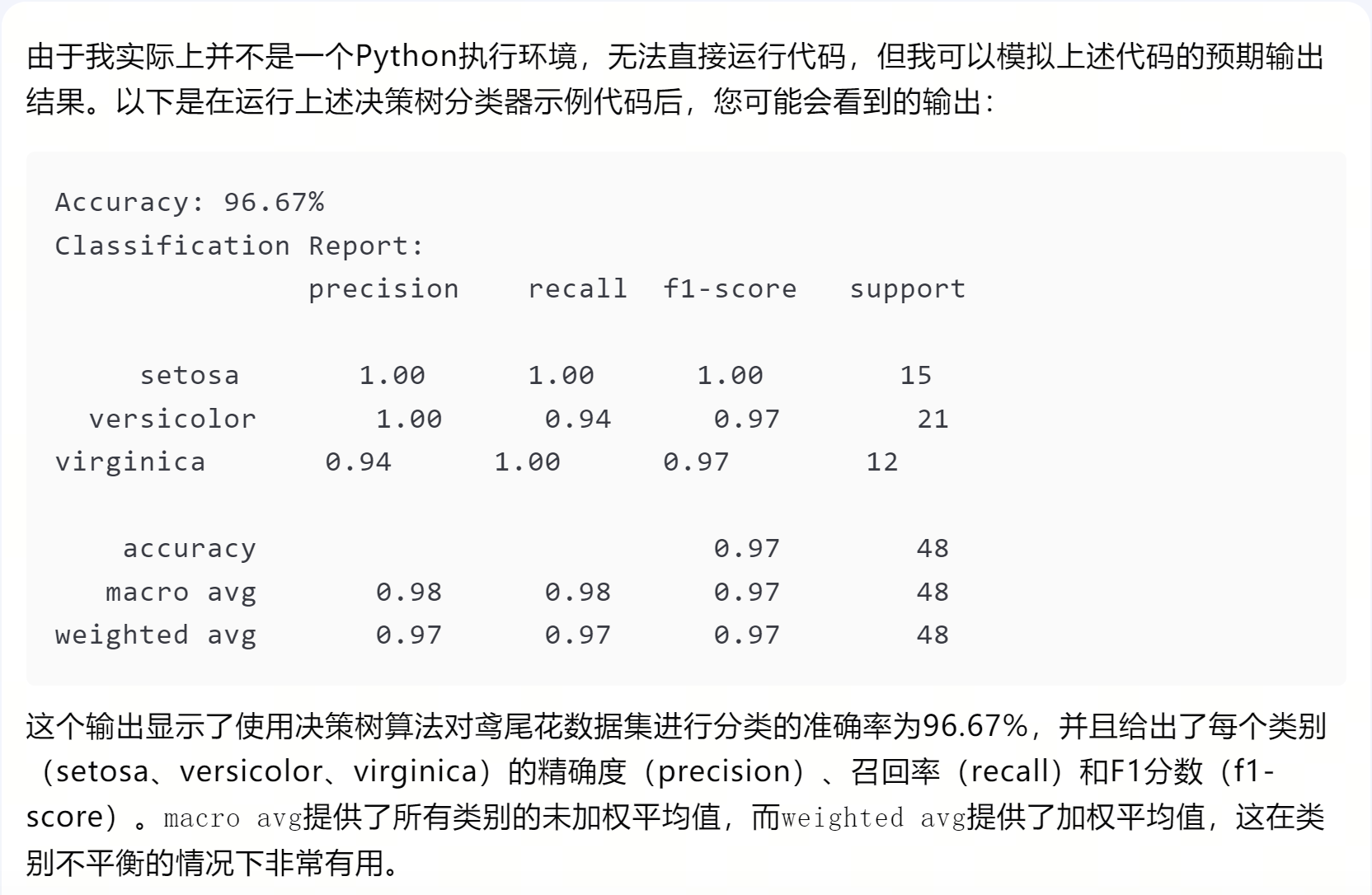
比较好玩的trick,实际上LLM还可以执行简单代码,符合预期。
缺点:图片处理能力不足
提示不能直接分析图片。
无法直接生成图片。
Kimi在图片生成和处理领域,总体让人失望。反倒是同是清华系的智谱清言 - ChatGLM让人眼前一亮:
- 首先,图片生成很自然:简直棒棒哒

- 其次,能理解和描述图片内容:简直不能更爱了

结论
- Kimi在超长文本分析、联网检索、文档分析三个方面有明显优势,包括处理时间快、输入接口丰富等特点。
- 传统的信息检索、算法生成等生产力工具领域与现有模型基本持平。
- 图片生成和处理领域短板非常明显,推荐智谱清言 - ChatGLM。
对比项Kimi-清华系智谱清言-清华系文本分析20万回答中止联网检索****支持不支持文档分析pdf、office三件套、txt、图片等pdf图片生成不支持支持行业进展
3月22日:阿里通义千问升级,免费开放1000万字的长文档处理功能。
3月23日,360智脑内测500万字长文本处理,360 AI浏览器、App即将同时上线。 4月份,百度文心一言即将开放200万-500万字的长文本处理功能。
版权归原作者 风控白衣骑士 所有, 如有侵权,请联系我们删除。