
1 简介
本文根据openAI的2023年3月的《GPT-4 Technical Report 》翻译总结的。
原文地址:https://arxiv.org/pdf/2303.08774.pdf
原文确实没有GPT-4 具体的模型结构,openAI向盈利组织、非公开方向发展了。也没透露硬件、训练成本、训练数据、训练方法等。不过也透露了一些思想,比如提出了根据模型小的时候,预测模型大的时候的表现。
GPT-4开始多模态了,支持图片和文本输入,输出文本。GPT-4模型还是沿用AR模型的思路,transformer模型,在一个文档中预测下一个token。GPT-4除了预训练,增加了强化学习微调,即使用了Reinforcement Learning from Human Feedback (RLHF) 。
GPT-4在一些考试如司法考试上取得了top 10%的成绩。而GPT-3.5的成绩在底部10%。
2 预测扩展性
GPT-4是非常大的训练成本,它不能灵活进行特定任务的微调。为此,我们开发了一个基础结构和优化的方法,可以根据模型小的时候,预测模型大的时候的表现。比如使用千分之一到万分之一的GPT-4计算成本就可以预测GPT-4的效果。
loss预测可扩展性
提出了下面公式,可以通过小模型预测GPT-4的loss。
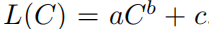
如下图,设GPT-4计算成本为1,x轴前面的就是小模型,y轴是损失loss。随着模型增大到GPT-4,损失loss可以通过小模型进行预测。
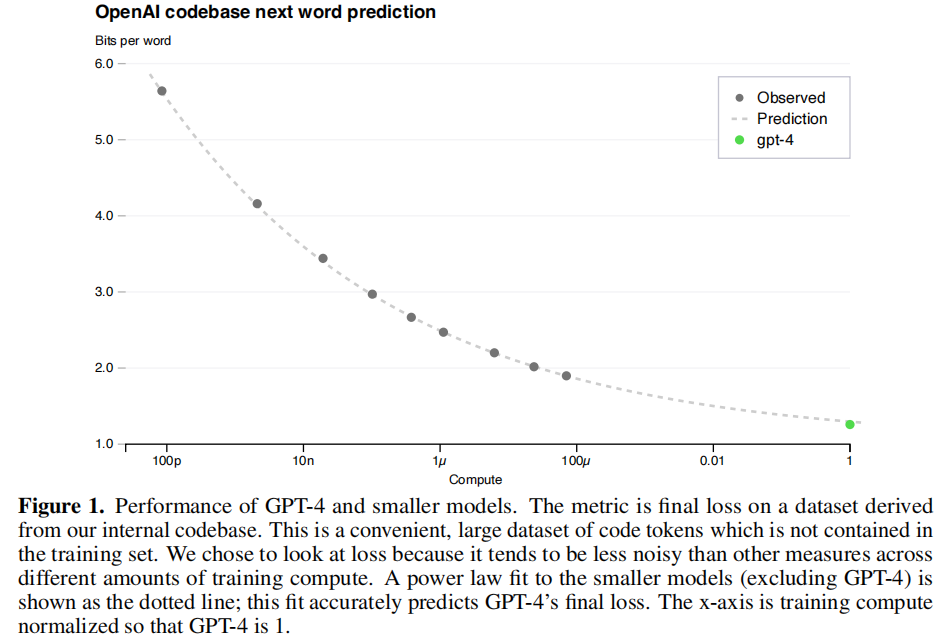
HumanEval验证数据集上能力的预测扩展性
提出了下面公式,可以通过小模型预测GPT-4的能力。
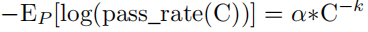
其中k和a是正常数,P是验证数据集的一个问题集合子集。
如下图,设GPT-4计算成本为1,x轴前面的就是小模型。随着模型增大到GPT-4,大模型能力可以通过小模型进行预测。
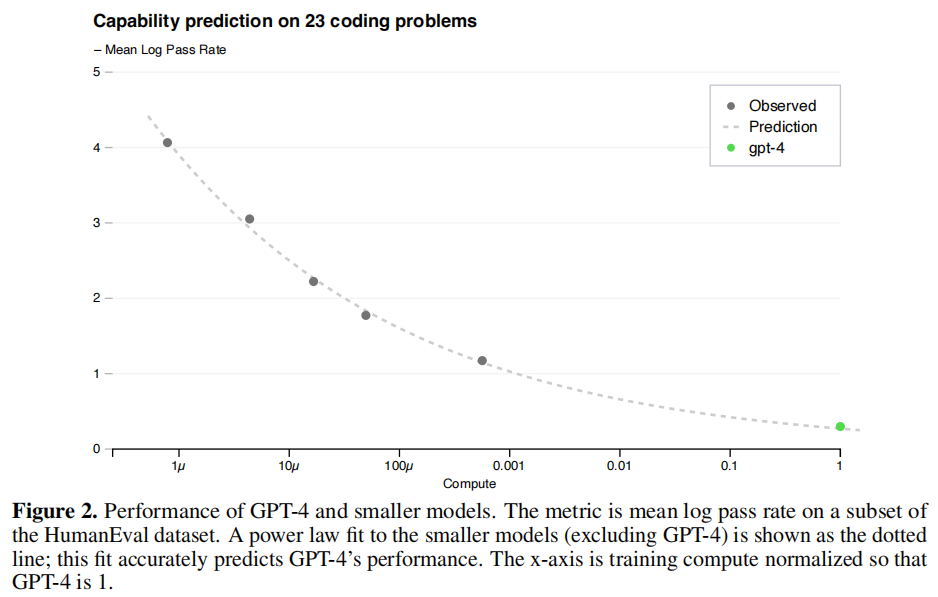
3 GPT-4能力
如下图,GPT-4比GPT-3.5更好的通过各种学术和专业考试。
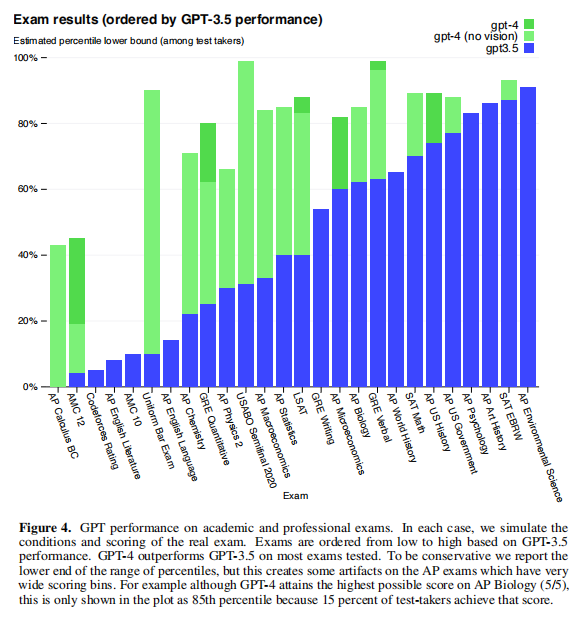
GPT-4在考试方面的能力不是太依靠强化学习RLHF,在多项选择题上,GPT-4和RLHF模型的表现差不多相等。
4 视觉输入
GPT-4支持图片和文本的任意排列的输入。
如下图,问GPT-4图片中有什么有趣的事情?分别逐张描述。GPT-4准确的描述出:图片将过时的VGA连接头插入现代手机进行充电。

5 模型缺点
GPT-4和以前GPT版本有类似的限制,最重要的是它不是完全可以信赖的。
GPT-4的训练数据是截至2021年9月的,所以没有最新的新闻事件。有时它也会犯错,或者被用户欺骗。它也不能处理很难的问题(人类可以处理)。
GPT-4有时可能对自己的输出过于自信。
6 缓解风险
a)利用专家知识对抗测试(Adversarial Testing via Domain Experts)
b)搭建模型安全助手(Model-Assisted Safety Pipeline):包括两个主要成员,一个是利用额外的进行安全相关的RLHF训练提示数据集,一个基于规则的奖励模型(RBRMs)。
rule-based reward models (RBRMs)是一个zero-shot的GPT-4分类器。这个分类器在GPT-4进行RLHF微调时提高一个额外的奖励信号,使得GPT-4倾向于正确的行为,拒绝生成有害的内容,或者不要拒绝无害的请求。
c)Improvements on Safety Metrics:在RealToxicityPrompts数据集上,GPT-4仅有0.73%的时间产生有毒的内容,而GPT-3.5是6.48%时间产生有毒内容。
版权归原作者 AI强仔 所有, 如有侵权,请联系我们删除。