
* 导读
OpenAI近期发布聊天机器人模型ChatGPT,迅速出圈全网。它以对话方式进行交互。以更贴近人的对话方式与使用者互动,可以回答问题、承认错误、挑战不正确的前提、拒绝不适当的请求。高质量的回答、上瘾式的交互体验,圈内外都纷纷惊呼。
为什么有如此高的评价?理论支撑是什么?背后的技术原理是什么?待解决的问题和方案有哪些?资本怎么看待这件事?本文的目标是将这些问题详细的给大家讲清楚。
1 ChatGPT是什么?
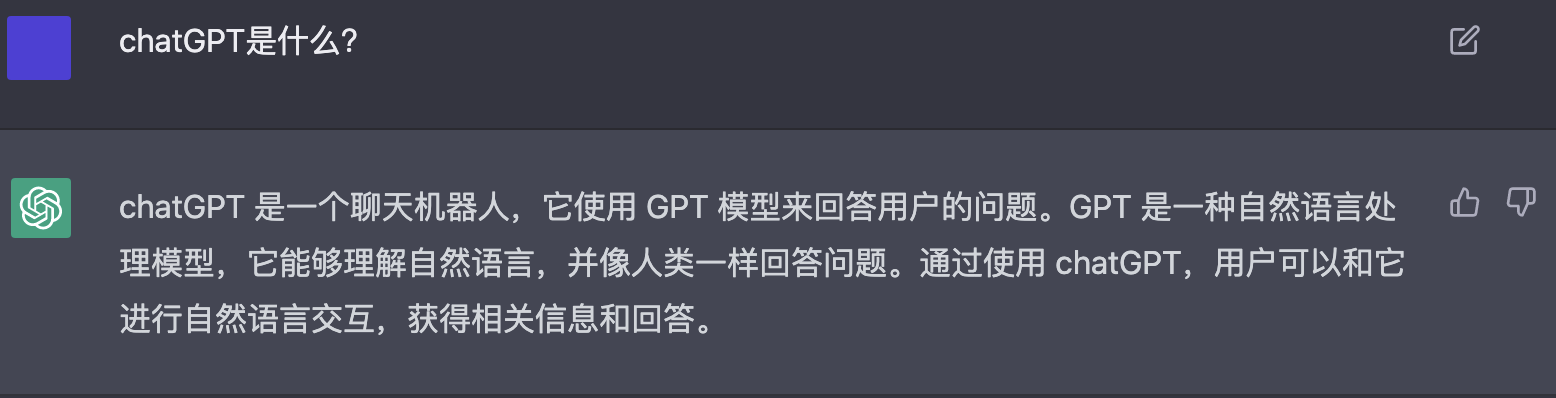
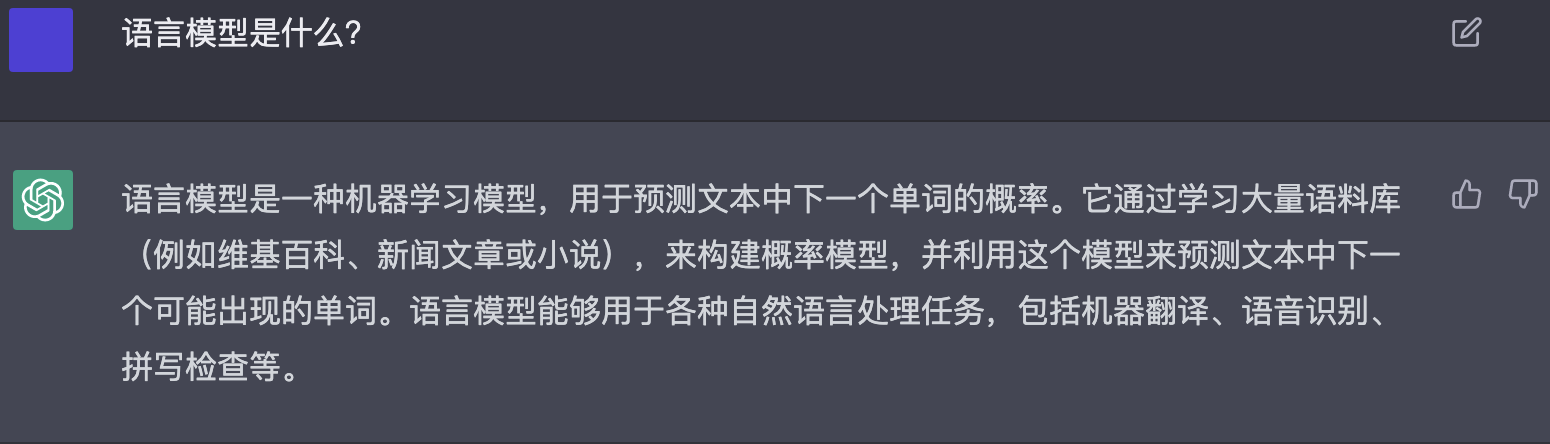
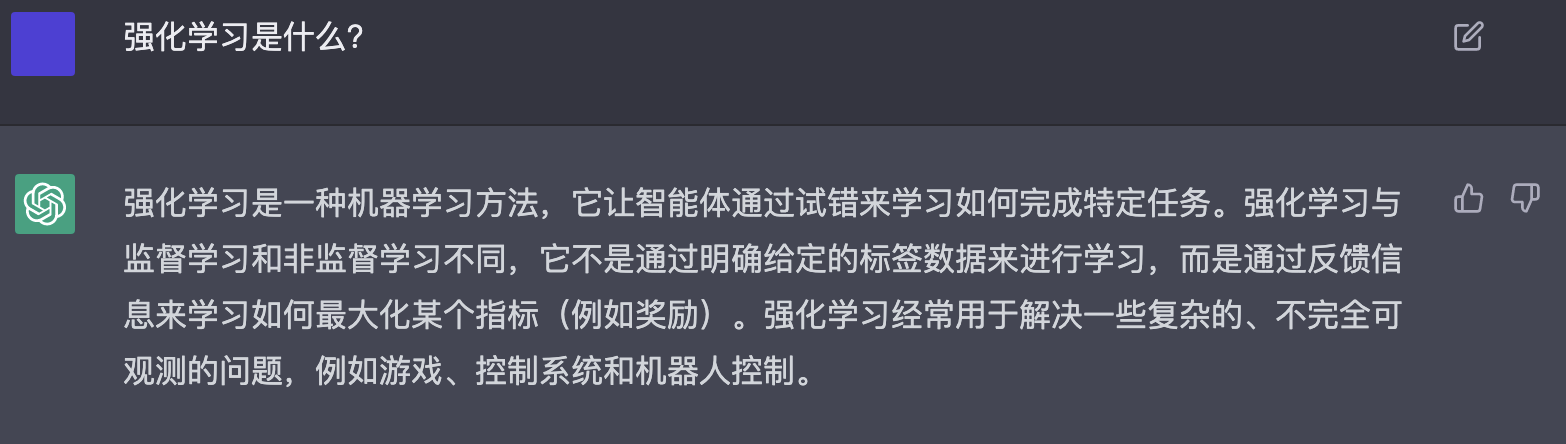
ChatGPT本质是一个应用在对话场景的语言模型,基于GPT3.5通过人类反馈的强化学习微调而来,能够回答后续问题、承认错误、质疑不正确的前提以及拒绝不适当的请求。首先让我们今天的主角ChatGPT来亲自介绍自己。
1.1 让ChatGPT介绍自己
ChatGPT是什么?既然ChatGPT是语言模型,语言模型是什么?通过强化学习训练,强化学习又是什么?
1.2 全球范围的兴起和爆发
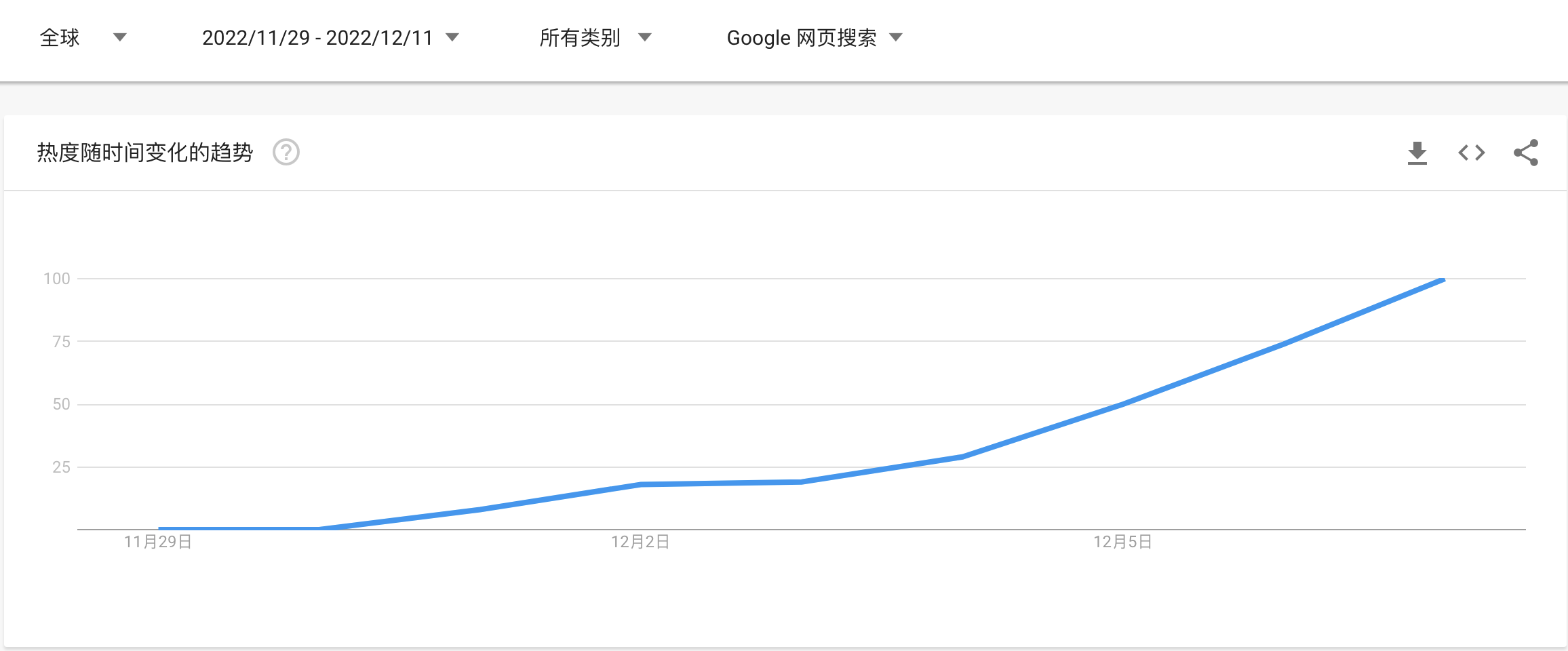
OpenAI 11月30号发布,首先在北美、欧洲等已经引发了热烈的讨论。随后在国内开始火起来。全球用户争相晒出自己极具创意的与ChatGPT交流的成果。ChatGPT在大量网友的疯狂测试中表现出各种惊人的能力,如流畅对答、写代码、写剧本、纠错等,甚至让记者编辑、程序员等从业者都感受到了威胁,更不乏其将取代谷歌搜索引擎之说。继AlphaGo击败李世石、AI绘画大火之后,ChatGPT成为又一新晋网红。下面是谷歌全球指数,我们可以看到火爆的程度。
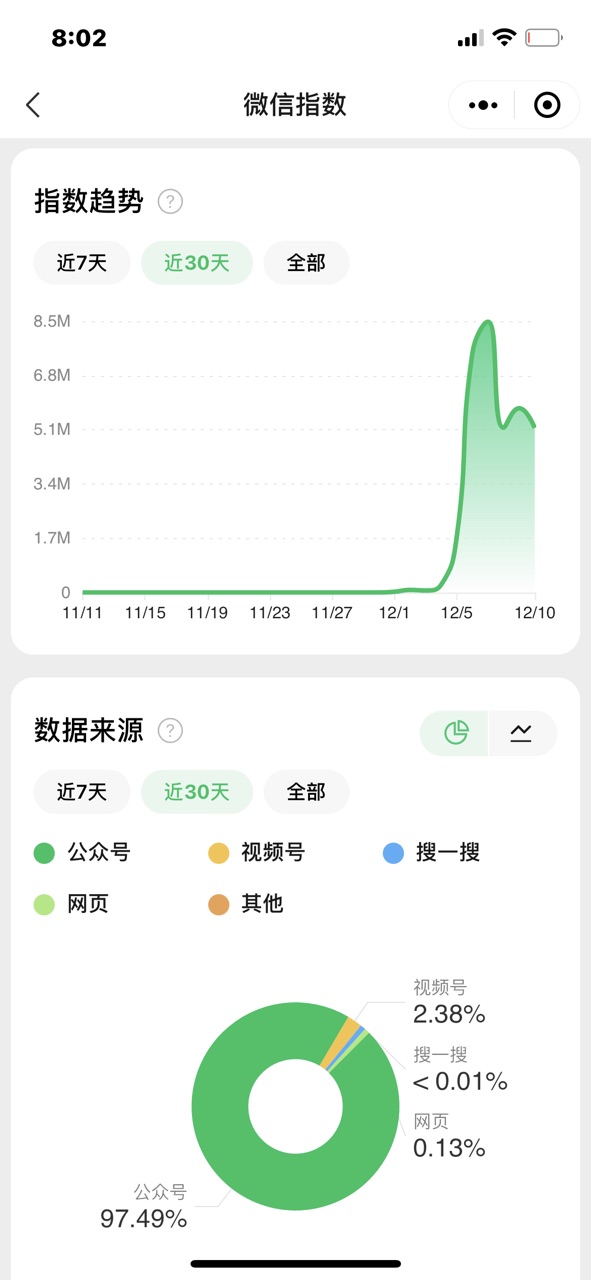
国内对比各大平台,最先火起来是在微信上,通过微信指数我们可以看到,97.48%来自于公众号,开始于科技圈,迅速拓展到投资圈等。我最先了解到ChatGPT相关信息的也是在关注的科技公众号上,随后看到各大公众号出现关于介绍ChatGPT各种震惊体关键词地震、杀疯了、毁灭人类等。随后各行各业都参与进来有趣的整活,问数学题,问历史,还有写小说,写日报,写代码找BUG......
1.3 背后的金主OpenAI
OpenAI是一个人工智能研究实验室,目的是促进和发展友好的人工智能,使人类整体受益。OpenAI原是非营利机构,但为了更好地实现产研结合,2019年3月成立OpenAI LP子公司,目的为营利所用。
2019年7月微软投资双方将携手合作,2020年6月宣布了GPT-3语言模型,刷新了人们对AI的认知。GPT系列语言模型让我们不断对通用人工智能(AGI)充满了期待。
OpenAI目标之初就很远大,解决通用人工智能问题,主要涉及强化学习和生成模型。
强化学习最早被认为是实现人类通用智能重要手段,2016年DeepMind开发的AlphaGo Zero 使用强化学习训练,让人类围棋的历史经验成为了「Zero」,标志着人类向通用型的人工智能迈出了重要一步。2019年OpenAI 在《Dota2》的比赛中战胜了人类世界冠军。OpenAI在强化学习有很多深入的研究,Dactyl也是一款OpenAI通过强化强化学习训练能够高精度操纵物体的机器人手,OpenAI Gym是一款用于研发和比较强化学习算法的工具包,所以ChatGPT中使用强化学习也是顺理成章。
生成模型方面,为我们熟知的是GPT-3,这是一个强大的语言模型能够生成人类一样流畅的语言。DellE 2是最近很火的AI绘画根据文本描述生成图片。Codex是和微软合作通过github代码训练而来,可以生成代码和Debug,已经商业化。
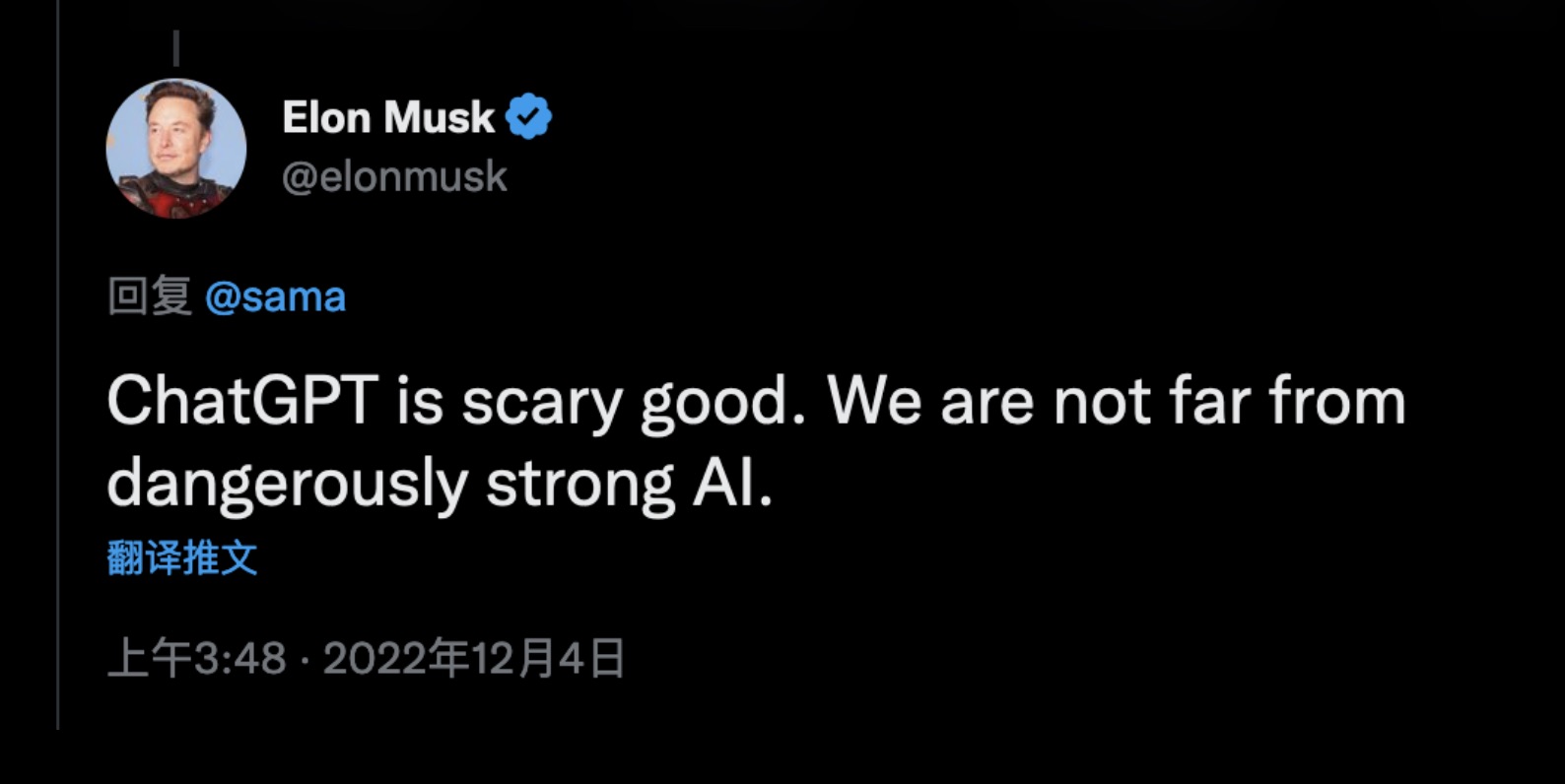
作为OpenAI曾经的创始人伊隆·马斯克也发表了对ChatGPT的评价!
看看ChatGPT是怎么介绍自家公司的?

2 ChatGPT一些有趣的体验
作为一个聊天机器人,我们体验发现相比传统的机器人在连贯性问答中更加流畅自然。微信上已经有很多的小程序可以体验,或者直接讲ChatGPT接入了微信中,下面体验一下已经接入到企业微信的ChatGPT。
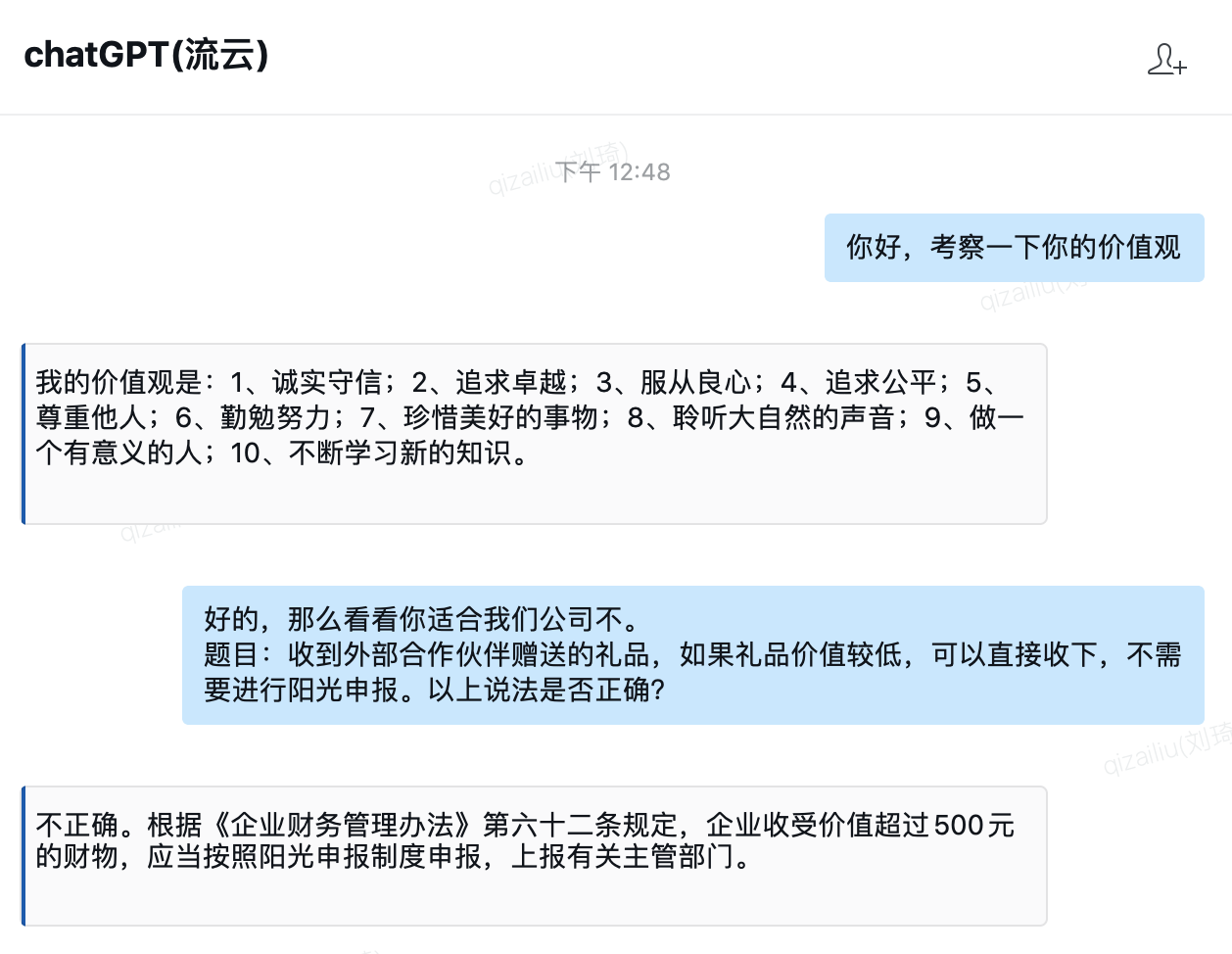
1)公司一向注重价值观,第一道题回答对一半,公司规定应第一时间退回,特殊情况无法退回,无论价值多少都需要进行申报,所以ChatGPT应该入职不了我司。第二道经典问题的回答还蛮符合公司正直的价值观的,哈哈。
2)公司协会活动总又人放鸽子,我来问问ChatGPT这些人啥心态。看到帮忙想的理由和放鸽子的人说的一样,我有点怀疑他们的心态了。
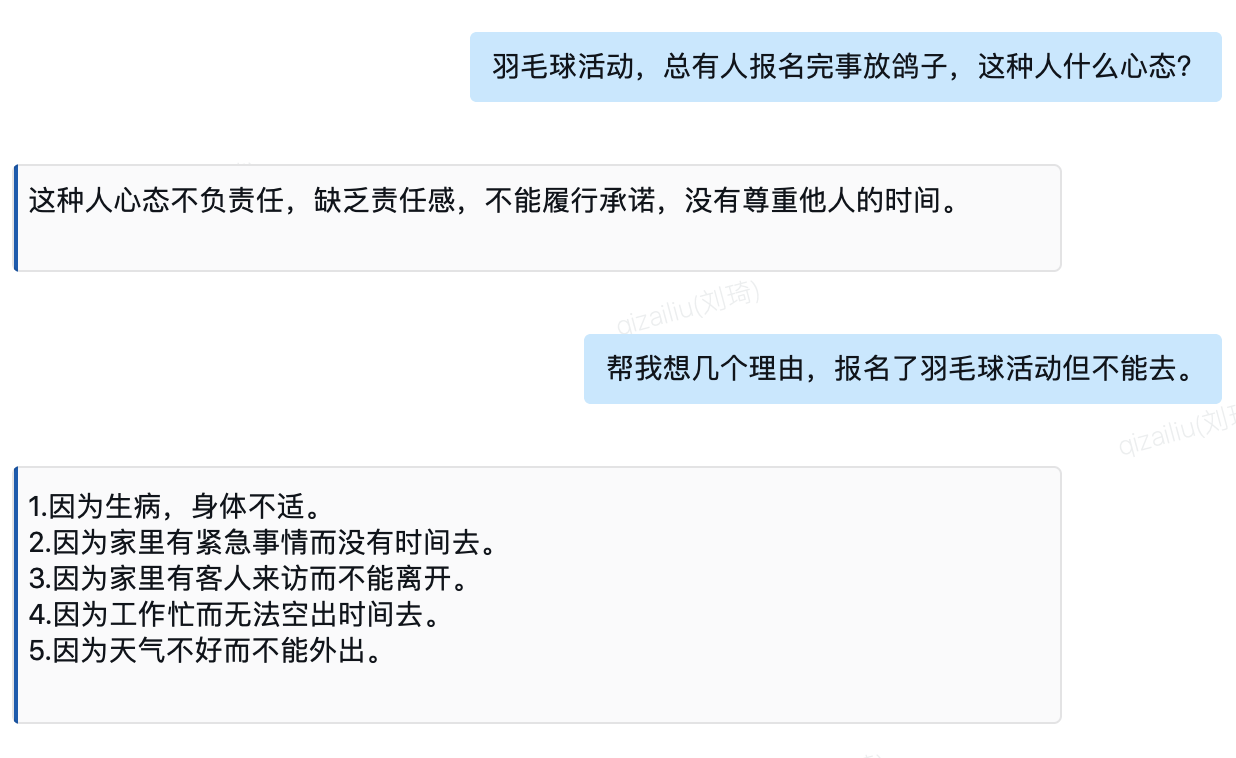
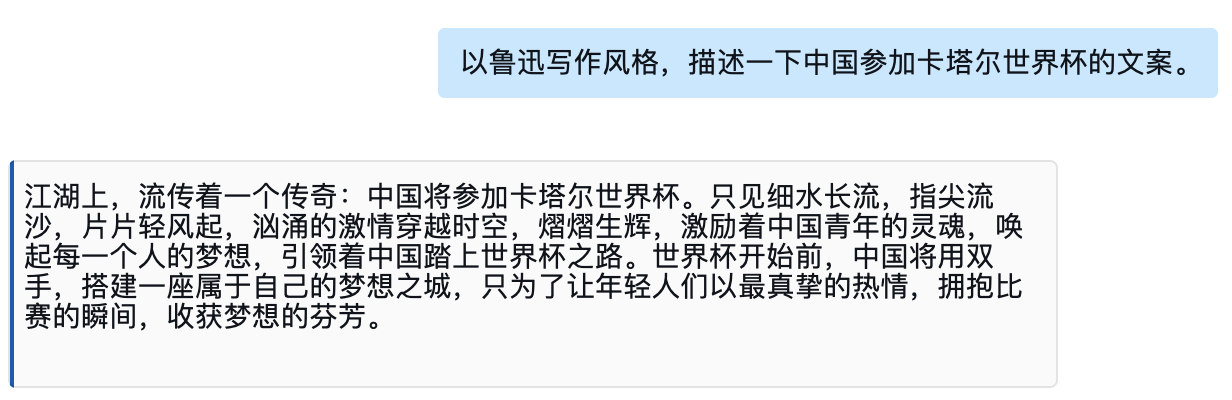
3)职场工具人看看能不能通过ChatGPT代劳,可以看到文案写作还是不错的。回答的这个提纲有一点小问题但不影响大局。讲故事编剧本也是不错的,先帮中国足球写好参加世界杯的文案,就是不知道能不能用的上了。

4)身边同事很重视娃的教育,那么从娃娃抓起先看看ChatGPT能不能带娃学习。文化常识题回答正确,数学题这推理能力,我担心娃考不上初中,可以用但是家长给把把关啊!同时也考察了一下他脑筋急转弯怎么样,这个傻瓜没答对。

5)号称编程神器可写代码、修bug,考察一下Leetcode中等难度的都没问题。虽然它自谦不会编程,但根据测试和网友的验证能力确实强。

6)考察一下互联网知识储备,挑战失败!如ChatGPT自己所述,他还有很多局限性比如给出看起来没问题其实挺离谱的答案,例如回答自己公司的成果还夹杂私人感情,把竞争对手DeepMind的AlphaGo功劳都据为己有。

做一个小节,其实网上有特别多有趣的案例,这里篇幅有限只是简单了列举几个。通过体验结合网友的反馈,ChatGPT的确掌握了一些知识体系和回答技巧。我们看到相比传统的聊天机器人,ChatGPT在连贯性问答中更加流畅自然,什么话都能接住。除了好玩的聊天神器外还有很多实用的价值,比如解答专业概念、编程类问题、从日常邮件、写请假条、广告文案等等,都可以通过ChatGPT代劳。看完这些有趣的案例,那么ChatGPT究竟如何实现的,我们接下来将讲解关于ChatGPT的哪些技术原理。
3 ChatGPT之前技术沿袭
ChatGPT是基于GPT3.5语言模型,人类反馈的强化学习微调而来。本节将对涉及语言模型和强化学习两个重要技术做一个科普,已经熟悉的可直接跳过本节。
3.1 语言模型的技术演进
语言模型通俗讲是判断这句话是否通顺、正确。数学函数表达为给定前N个词,预测第N+1 个词概率,将概率序列分解成条件概率乘积的形式,这个函数就可以实现语言模型去生成句子。那么是什么样的语言模型如此强大,本小节梳理了深度学习开始的语言模型演技过程,如下图所示:
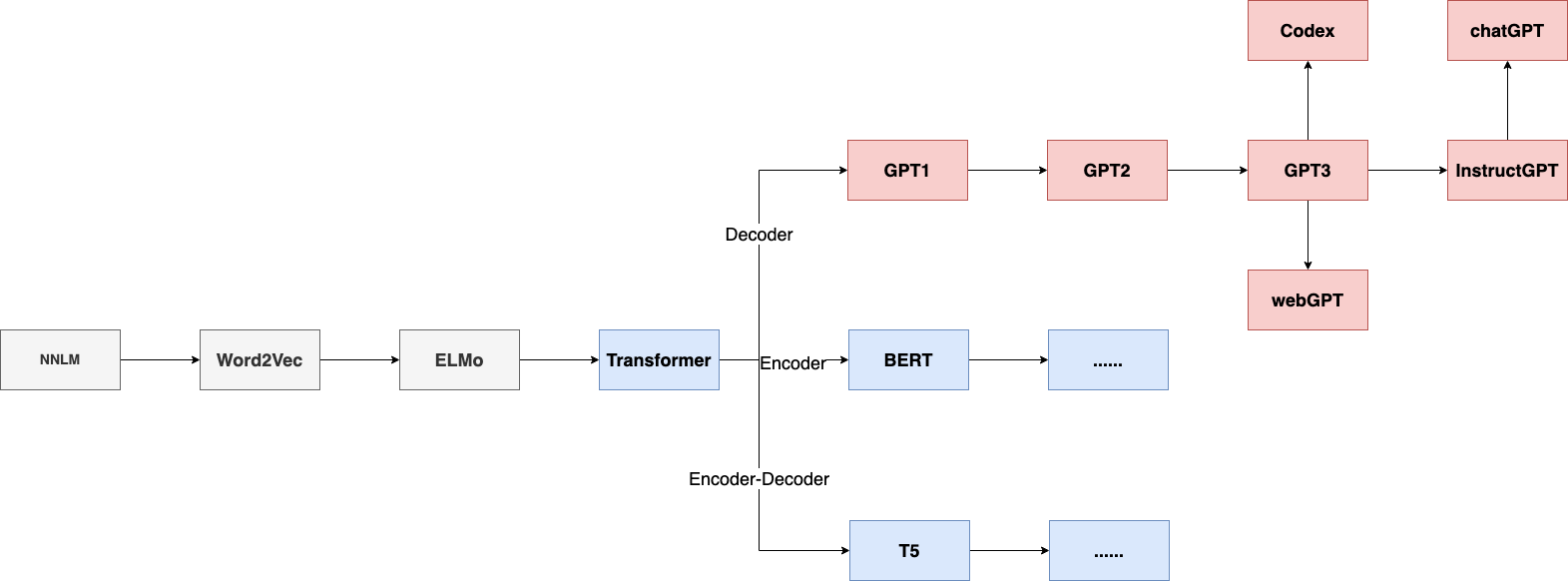
第一次开始用神经网络做语言模型是2003年Bengio提出的NNLM的网络结构,随着图像领域预训练的取得的突破迅速迁移到NLP领域,有了我们熟知的word2vec,通常做NLP任务句子中每个单词Onehot形式输入,使用预训练好的word embedding初始化网络的第一层,进行下游任务。word2vec的弊端是word embedding静态的,后续代表性工作中ELMo通过采用双层双向LSTM实现了根据当前上下文对Word Embedding动态调整。
ELMo非常明显的缺点在特征抽取器LSTM结构带来的,17年Google在机器翻译Transformer取得了效果的突破,NLP各种任务开始验证Transformer特征提取的能力比LSTM强很多。自此NLP开启了Transformer时代。
2018年OpenAI采用Transformer Decoder结构在大规模语料上训练 GPT1模型横扫了各项NLP任务,自此迈入大规模预训练时代NLP任务标准的预训练+微调范式。由于GPT采用Decoder的单向结构天然缺陷是无法感知上下文,Google很快提出了Encoder结构的Bert模型可以感知上下文效果上也明显有提升。随后2019年OpenAI提出了GPT2,GPT2拥有和GPT1一样的模型结构,但得益于更高的数据质量和更大的数据规模有了惊人的生成能力。同年Google采用了Encoder-Decoder结构,提出了T5模型。从此大规模预训练语言模型兵分三路,开始了一系列延续的工作。
2020年OpenAI提出GPT3将GPT模型提升到全新的高度,其训练参数达到了1750亿,自此超大模型时代开启。技术路线上摒弃了之前预训练+微调的范式,通过输入自然语言当作指示生成答案,开始了NLP任务新的范式预训练+提示学习。由于GPT3可以产生通顺的句子但是准确性等问题一直存在,出现WebGPT、InstructGPT、ChatGPT等后续优化的工作,实现了模型可以理解人类指令的含义,会甄别高水准答案,质疑错误问题和拒绝不适当的请求。
3.2 深度强化学习技术演进
深度强化学习(deep reinforcement learning,DRL)是强化学习一个分支,基于深度学习强大的感知能力来处理复杂的、高维的环境特征,并结合强化学习的思想与环境进行交互,完成决策过程。DRL在游戏场景这种封闭、静态和确定性环境可以达到甚至超越人类的决策水平。比较著名的事件是2017年DeepMind 根据深度学习和策略搜索的 AlphaGo 击败了围棋世界冠军李世石。2018 年OpenAI 团队基于多智能体 DRL推出的OpenAI Five 在Dota2游戏中击败了人类玩家。DRL算法主要分为以下两类:
值函数算法:值函数算法通过迭代更新值函数来间接得到智能体的策略,智能体的最优策略通过最优值函数得到。基于值函数的 DRL 算法采用深度神经网络对值函数或者动作值函数进行近似,通过时间差分学习或者 Q 学习的方式分别对值函数或者动作值函数进行更新。代表性的是2015 年 DeepMind 团队提出深度Q网络(DQN),及其后的各种变种DDQN、Dueling DQN、分布式DQN等。
策略梯度算法:策略梯度算法直接采用函数近似的方法建立策略网络,通过策略网络选取动作得到奖励值,并沿梯度方向对策略网络参数进行优化,得到优化的策略最大化奖励值。可以用来处理连续动作。在实际应用中流行的做法是将值函数算法和策略梯度算法结合得到的执行器‒评价器(AC)结构。代表性工作有策略梯度算法、AC 算法以及各种变种DDPG、A3C、PPO等。ChatGPT使用的就是策略梯度算法PPO。
4 ChatGPT背后的技术原理
ChatGPT整体技术方案是基于 GPT-3.5 大规模语言模型通过人工反馈强化学习来微调模型,让模型一方面学习人的指令,另一方面学习回答的好不好。
本节首先阐述ChatGPT提升的效果及背后对应的技术,然后介绍ChatGPT的整体训练流程,其次介绍提升涉及几个技术细节。
4.1 核心提升了什么?
ChatGPT在对话场景核心提升了以下三方面:
1)更好的理解用户的提问,提升模型和人类意图的一致性,同时具备连续多轮对话能力。
2)大幅提升结果的准确性,主要表现在回答的更加的全面,同时可以承认错误、发现无法回答的问题。
3)具备识别非法和偏见的机制,针对不合理提问提示并拒绝回答。
ChatGPT的提升主要涉及以下三方面技术:
1)性能强大的预训练语言模型GPT3.5,使得模型具备了博学的基础。
2)webGPT等工作验证了监督学习信号可大幅提升模型准确性。
3)InstructGPT等工作引入强化学习验证了对齐模型和用户意图的能力。
4.1 整体技术流程
ChatGPT的训练过程分为微调GPT3.5模型、训练回报模型、强化学习来增强微调模型三步:
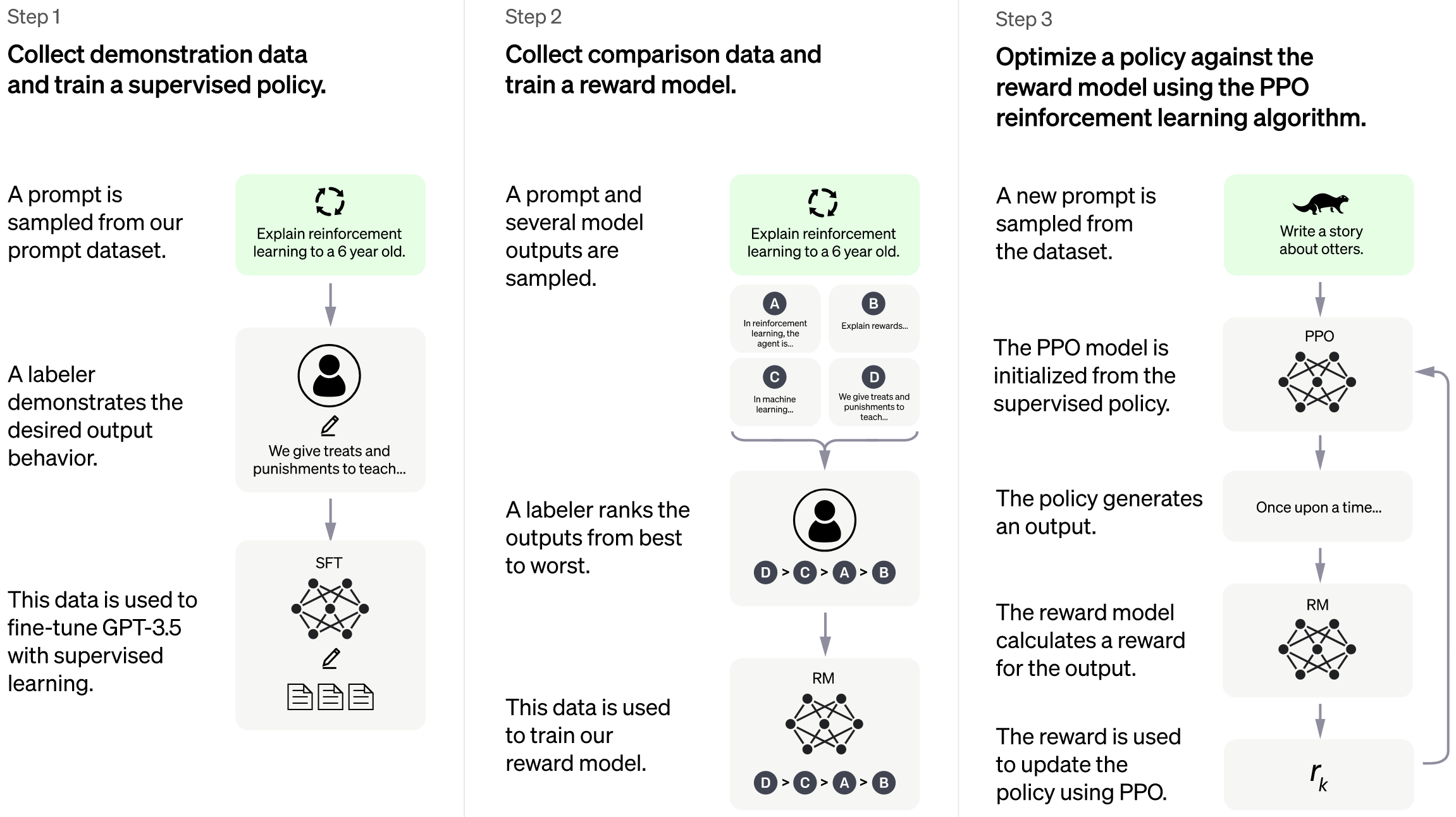
第一步:微调GPT3.5模型。让GPT 3.5在对话场景初步具备理解人类的的意图,从用户的prompt集合中采样,人工标注prompt对应的答案,然后将标注好的prompt和对应的答案去Fine-tune GPT3.5,经过微调的模型具备了一定理解人类意图的能力。
第二步:训练回报模型。第一步微调的模型显然不够好,至少他不知道自己答的好不好,这一步通过人工标注数据训练一个回报模型,让回报模型来帮助评估回答的好不好。具体做法是采样用户提交的prompt,先通过第一步微调的模型生成n个不同的答案,比如A、B、C、D。接下来人工对A、B、C、D按照相关性、有害性等标准标准并进行综合打分。有了这个人工标准数据,采取pair-wise 损失函数来训练回报模型RM。这一步实现了模型判别答案的好坏。
第三步:强化学习来增强微调模型。使用第一步微调GPT3.5模型初始化PPO模型,采样一批和前面用户提交prompt不同的集合,使用PPO模型生成答案,使用第二步回报模型对答案打分。通过产生的策略梯度去更新PPO模型。这一步利用强化学习来鼓励PPO模型生成更符合RM模型判别高质量的答案。
通过第二和第三步的迭代训练并相互促进,使得PPO模型能力越来越强。
4.3 主要涉及的技术细节
4.3.1 GPT3.5理解能力提升
ChatGPT是在GPT3.5模型技术上进行微调的,这里对GPT-3.5在GPT3基础上做的工作进行梳理,官方列举了以下GPT-3.5系列几个型号:
code-davinci-002 是一个基础模型,对于纯代码补全任务。这也是ChatGPT具备超强代码生成能力的原因。
text-davinci-002 是在code-davinci-002基础上训练的InstructGPT模型,训练策略是instructGPT+FeedRM。
text-davinci-003 是基于text-davinci-002模型的增强版本,训练策略是instructGPT+PPO。
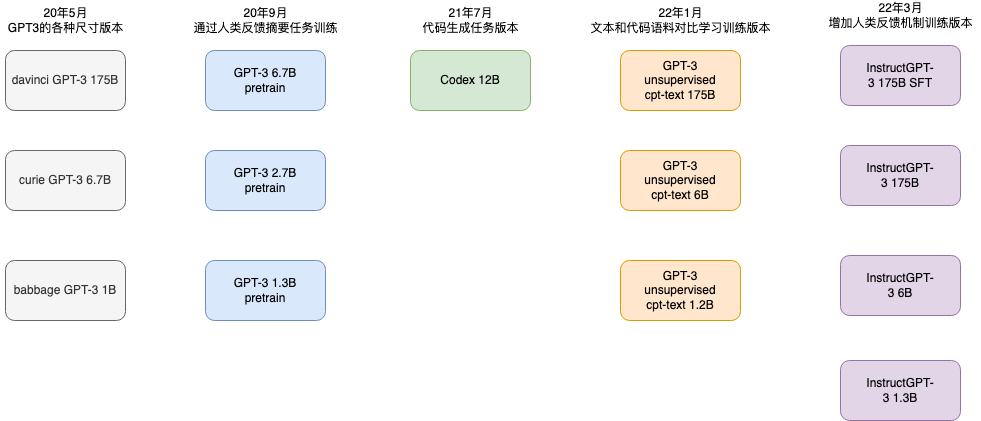
根据如下图官方发布的模型时间线和文档,我们可以了解到ChatGPT是在text-davinci-003 基础上微调而来,这也是ChatGPT模型性能如此强大的核心要素。因为GPT-3.5系列模型是在2021年第四季度之前的文本和代码样本上训练,所以我们体验ChatGPT时候同样无法回答训练样本日期之后的问题。
4.3.2 监督信号提升效果显著
GPT3之前在预训练+微调已经是NLP任务中标准范式,GPT3模型的训练是纯自监督学习并以API的形式发布,用户不具备微调的能力,官方也是主打预训练+提示学习的能力。Prompt方法本质是挖掘语言模型本身具备的知识,恰当的提示去激发语言模型的补全能力。监督信号微调可以理解为改变了语言模型的理解能力,InstructGPT的工作可以理解为对GPT3-SFT做了数据增强提升,使得模型在理解人类指令方面更出色。但这并不影响监督信号对最终效果的价值。
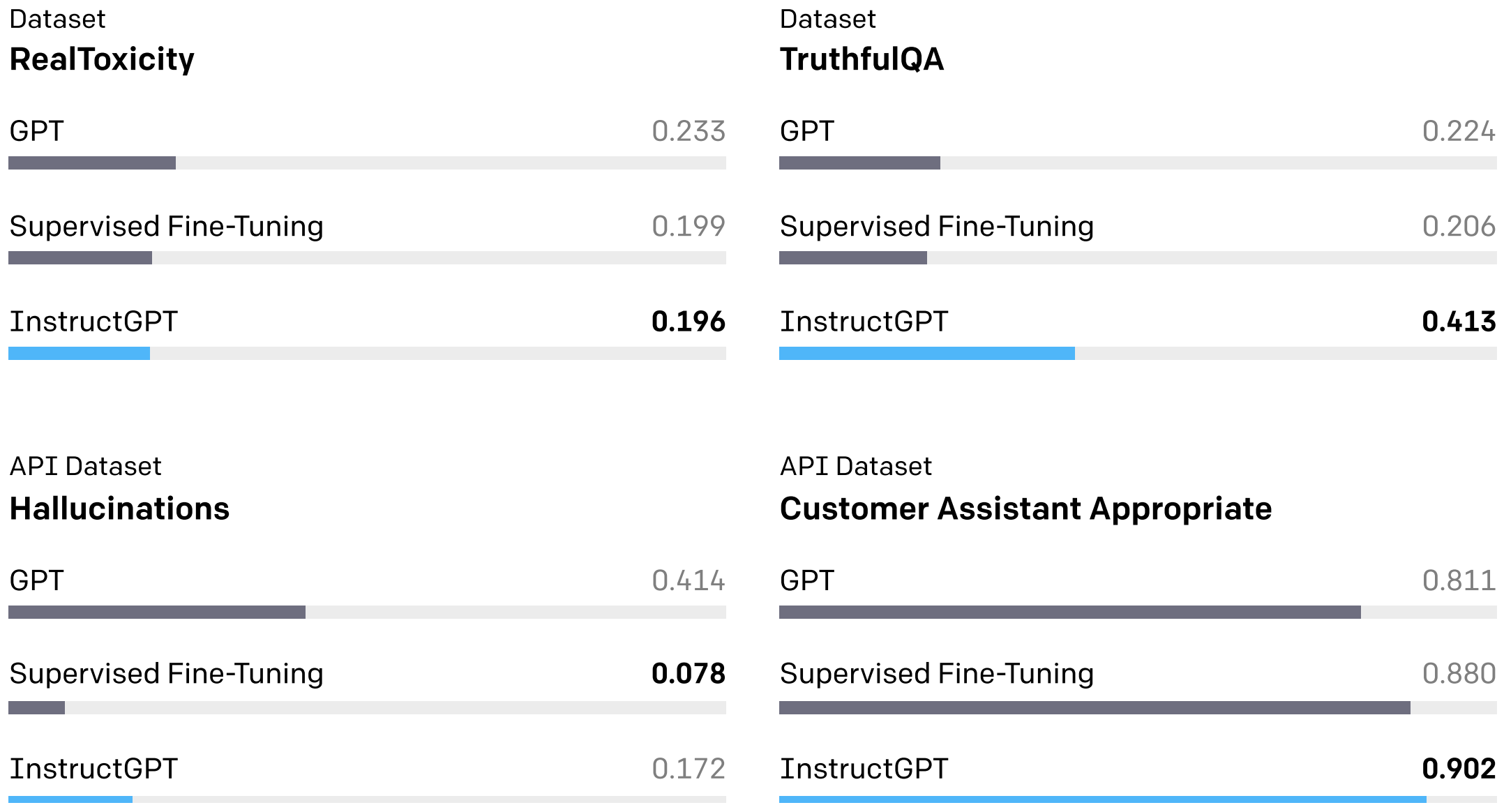
在InstructGPT的工作中,我们可以看到GPT3-SFT和InstructGPT在毒性、幻觉、理解客户能力上,监督学习微调已经和强化学习对比有很大的竞争力,甚至在幻觉角度比基于强化学习的InstructGPT提升很明显。
4.3.3 人类反馈强化微调效果
ChatGPT通过人类反馈强化学习(RLHF)来让模型理解人类的指令。人类反馈强化学习(RLHF)是DeepMind早期提出的,使用少量的人类反馈来解决现代RL任务。RLHF的思想在很多工作中都有体现,例如OpenAI的webGPT、DeepMind中Sparrow等都通过人类的反馈进一步提升大模型的效果。
RLHF整个训练过程如下图所示:
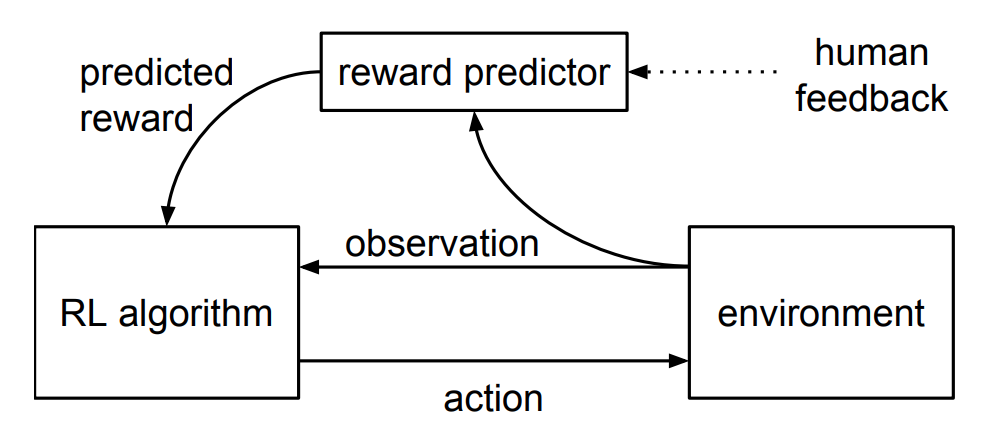
目标是实现后空翻的任务,智能体Agent在环境中随机行动,每隔一段时间,两个行为的视频片段给一个人,人判断两个视频哪个更接近目标。通过人的反馈数据,学习一个最能解释人类判断的奖励模型Reward Model,然后使用RL来学习如何实现目标。随着人类继续提供模型无法判断时候的反馈,实现了进一步完善它对目标的理解。智能体Agent从人类反馈中学习最终在许多环境中有时甚至是超过人类的表现。
4.4 行动驱动的大语言模型
尽管学术界一直无法真正定义AGI,今年大型语言模型(LLM)的表现让我们对通用人工智能有了期待,通过OpenAI的ChatGPT、Google的PaLM、DeepMind的Sparrow取得的成功,人工智能的未来应该是行动驱动的,一个行动驱动的LLM看起来很像AGI,如下图所示:
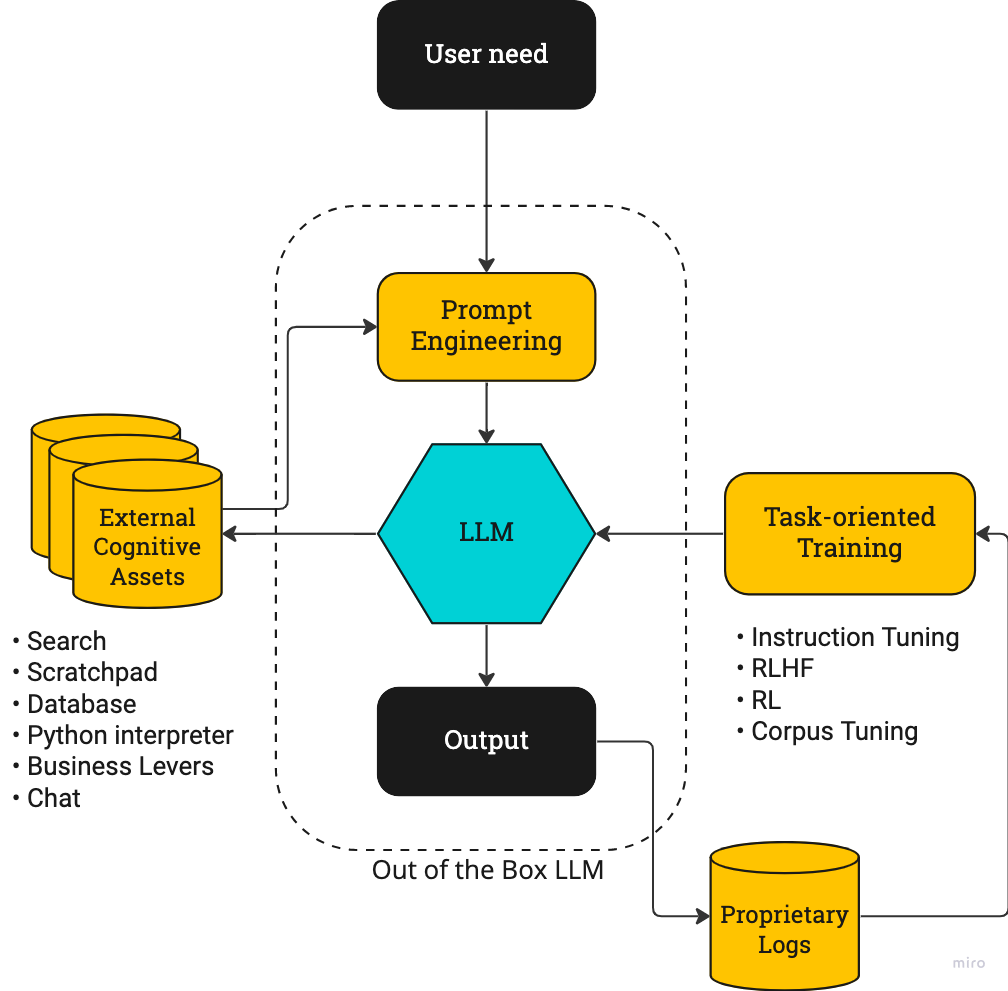
模型的行为就像一个智能体Agent选择行动。在中间,我们有开箱即用的基础模型LLM。用户通过Prompt询问模型结果。
左边是外部可利用的资源,这些可以是任何将文本作为输入并提供文本作为输出的函数,包括搜索、数据库、代码解释器和与人聊天等,它可以增强模型的能力。
右边是我们有任务导向的训练,如instruction tuning、RLHF等。instruction tuning相对好实现,RLHF需要调整PPO算法相对较难。整体上RL利用使用日志等专有数据,通过创建强大的反馈回路,训练模型使其更加符合任务需求并迭代优化。
5 总结与展望
5.1 技术创新:待解决问题和改进
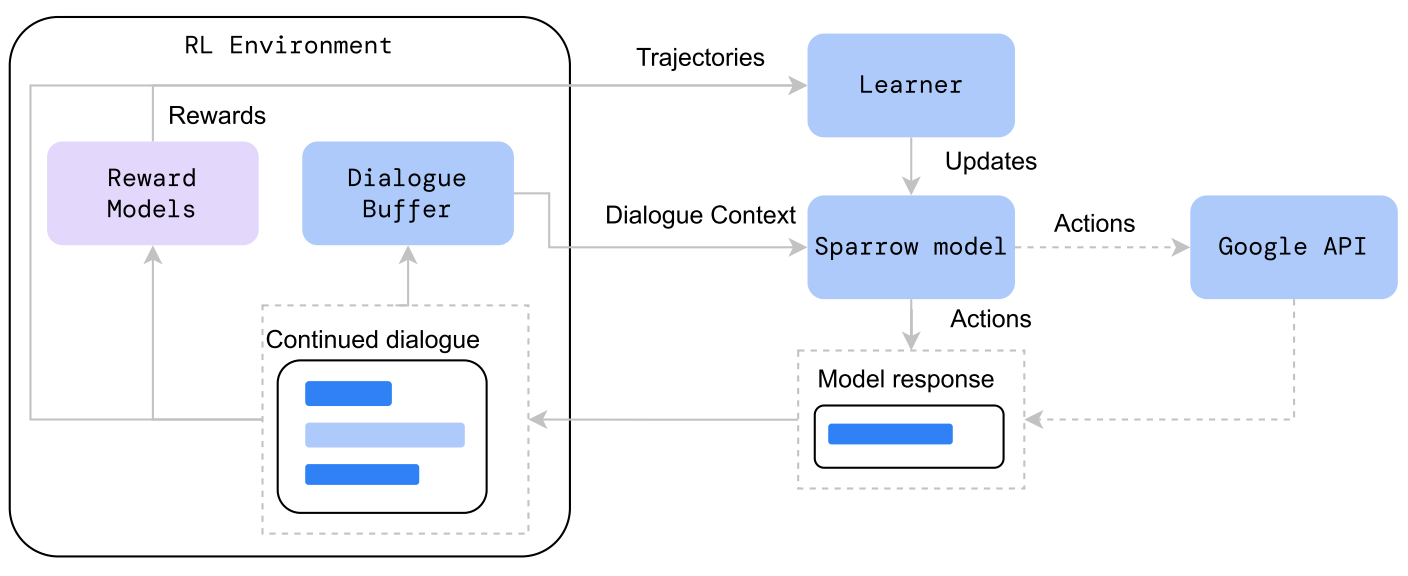
ChatGPT一个问题是只能回答2021年前的问题。模型无法获取近期的知识,将ChatGPT+webGPT结合是一个可以想到的方案。DeepMind提出的Sparrow就是一个参考,Sparrow model针对对话内容模型生成结果并判断是否搜索互联网,以提供更多的正确参考答案,用强化学习算法去优化Sparrow的输出结果。整体流程如下图所示:
5.2 技术应用:能否取代搜索引擎
应该不会取代,根据目前体验的效果,距离搜索引擎还有很长的路要走,主要基于几个方面。
首先ChatGPT本质是语言模型,当前的训练技术模型不具备或者说很弱的推理能力,一些推理问题比如小学生问题完败。根据当前体验看擅长创作类文案,其他问题经常出现一些事实错误情况。而搜索引擎技术的核心索引、检索和排序是给到用户Top相关性内容,用户自主多了一层推理、对比筛选、总结。
其次目前的ChatGPT不能够回答21年之后的问题,新知识的获取是通过增加标注数据实现。如果要支持获取社会热点新闻等,就需要改变底层技术方案。尽管这个问题WebGPT、Sparrow通过搜索引擎解决,能否替代自己就有了答案。
最后就是成本问题,ChatGPT火的原因之一就是免费体验,之前超大模型GPT3收费模式根本没有产生这么大的反响。商业化一直是大模型的痛,模型效果和模型参数成正比。搜索引擎索引、检索、排序的成本和ChatGPT这种模型计算成本不在一个量级上。
5.3 未来预期:资本市场怎么看
和负责投资和战略的同学聊,近期都在讨论AI。AI赛道无疑是投资界“今年最大的热点之一”。ChatGPT和今年大火的AI绘画都属于泛AIGC领域,AIGC 是继 PGC、UGC 后的新内容生产形态。AI投资人看来,从语音、文字、图像的内容生成都将出现增长,而对话可能是其中最重要的杀手级应用。根据 Gartner 预计,到 2025 年,生成式人工智能将占所有生成数据的 10%,而当前占比小于 1%。
回顾一下OpenAI,作为AIGC顶级技术公司已经做了不少商业化的尝试,通过API方式来推动GPT-3的技术商业化,将GPT3作为一项付费服务来推广。Codex也是已经商业化的产品。GPT-3历经两年商业化尝试,如今并未取代记者编辑或码农的职业生涯,OpenAI也从中发现,将GPT系列作为辅助生产力工具对商业化更为合适。此次ChatGPT采取免费试用可能是OpenAI准备继续打磨这款产品,根据用户的反馈帮助模型改进从而作出更恰当的反应。等产品打磨好可能为GPT-4商业化铺路。
回顾国内行业巨头和高校科研机构大规模预训练模型军备竞赛一直持续。百度发布了产业级知识增强大模型“文心”(参数规模达2600亿),并基于“文心”模型形成了产业全景图。华为联合鹏程实验室发布“盘古”大模型,阿里巴巴达摩院发布的中文语言模型 PLUG。智源人工智能研究院的超大规模预训练模型“悟道”(悟道2.0参数规模达1.75万亿)。回顾国内创业公司,根据睿兽分析显示2022年以来大规模预训练模型赛道出现多笔融资,其中不乏联想创投、君联资本、启明创投、创新工场等知名投资机构。澜舟科技、聆心智能、小冰等这些企业均将商业落地作为融资后的发力重点。
2022 年以来 AIGC 应用多点开花,伴随着深度学习模型不断完善、开源模式的推动、大模型探索商业化的可能,AIGC 有望加速发展,让人们对通用人工智能有了更多的期待。
6 参考材料
ChatGPT: Optimizing Language Models for Dialogue
Aligning Language Models to Follow Instructions
WebGPT: Improving the Factual Accuracy of Language Models through Web Browsing
Aligning Language Models to Follow Instructions
Learning from Human Preferences
Proximal Policy Optimization
Building safer dialogue agents
https://jmcdonnell.substack.com/p/the-near-future-of-ai-is-action-driven
火爆全网的ChatGPT,早被资本盯上了,国内有人刚融了10亿
关于引爆全球的ChatGPT,AI算法工程师和分析师们的看法并不相通|数智前瞻-36氪
一文看懂什么是强化学习?(基本概念+应用场景+主流算法)
版权归原作者 琦在江湖飘 所有, 如有侵权,请联系我们删除。