
数据挖掘 —— 有监督学习(分类)
1. KNN分类算法
- 预备知识:KD-Tree算法 (KDimensional Tree)
- 在空间中寻找与目标点距离最近的k个点
- from sklearn.neighbors import NearestNeighbors
- n_neighbors 为查询的临近点个数
- algorithm 为查询算法
- ‘ball_tree’ will use BallTree
- ‘kd_tree’ will use KDTree
- ‘brute’ will use a brute-force search.
- ‘auto’ will attempt to decide the most appropriate algorithm based on the values passed to fit method.
- radius 为查询半径
- p 为闵可夫斯距离的p值
from sklearn import datasets
data = datasets.load_iris()
X_data = data["data"]
Y_data = data["target"]NN.fit(X_data) # 训练模型
result =NN.kneighbors(X=[[5.2,3.1,1.4,0.2]],n_neighbors =5,return_distance = True)
result[0] # 距离
result[1] # 索引
# ————KNN分类算法
"""
算法简介:https://www.cnblogs.com/jyroy/p/9427977.html
"""
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
features = pd.read_excel("./data.xlsx",sheet_name ="features",headers =0)
label = pd.read_excel("./data.xlsx",sheet_name ="label",headers =0)
# 训练集、验证集、测试集拆分
from sklearn.model_selection import train_test_split
X_tt,X_validation,Y_tt,Y_validation =train_test_split(features,label,test_size =0.2)
X_train,X_test,Y_train,Y_test =train_test_split(X_tt,Y_tt,test_size =0.25)
# 创建KNN分类模型对象
knn =KNeighborsClassifier(n_neighbors =3)
knn_5 =KNeighborsClassifier(n_neighbors =5)
# 使用训练集数据训练模型
knn.fit(X_test,Y_test)
knn_5.fit(X_test,Y_test)
# 使用模型对训练集和验证集数据进行预测
Y_validation_predict = knn.predict(X_validation)
Y_validation_predict_5 = knn_5.predict(X_validation)
Y_test_predict = knn.predict(X_test)
Y_test_predict_5 = knn_5.predict(X_test)
# 模型效果评判
"""
1、精准度:precision_score 指被分类器判定正例中的正样本的比重
2、准确率:accuracy_score 代表分类器对整个样本判断正确的比重。
3、召回率:recall_score 指的是被预测为正例的占总的正例的比重
4、f1_score 它是精确率和召回率的调和平均数,最大为1,最小为0"""
from sklearn.metrics import f1_score,precision_score,accuracy_score,recall_score
def metrics_wj(x,y,title):print("*"*8,title,"*"*8)print("precision score:",precision_score(x,y))print("recall score :",recall_score(x,y))print("accuracy score :",accuracy_score(x,y))print("f1 score:",f1_score(x,y))metrics_wj(Y_validation,Y_validation_predict,"neighbors = 3 validation datasets:")metrics_wj(Y_validation,Y_validation_predict_5,"neighbors = 5 validation datasets:")"""
存在微小过拟合现象
"""
# 模型保存
from sklearn.externals import joblib
joblib.dump(knn,"knn_wj")
knn_wj = joblib.load("knn_wj")
2. 决策树分类算法
- 叶节点:标注 内部节点:特征
- 决定特征顺序的方法:
- 信息增益 ID3算法 —— 优先选择信息增益大的特征(特征与标注之间的信息增益)
- 信息增益率 C4.5算法 —— 考虑到熵很小时,信息增益也比较小
- Gini系数 CART决策树 ——不纯度 不纯度最低的切分当做当前切分
- 几个问题:
- 连续值切分 —— 计算每个分隔
- 规则用尽 —— 投票
- 过拟合 —— 修枝剪叶。(1)前剪枝:构造决策树前,规定每个叶子结点有多少个样本.。(2)后剪纸:对样本值悬殊的枝叶进行修剪
# ————————决策树可视化——————
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.externals import joblib
from sklearn.tree import DecisionTreeClassifier,export_graphviz
from sklearn.metrics import accuracy_score,f1_score,recall_score,precision_score
import os
import pydotplus
# 读取数据
features = pd.read_excel("./data.xlsx",sheet_name ="features",header =0)
label = pd.read_excel("./data.xlsx",sheet_name ="label",header =0)
feature_name = features.columns.values
# 训练集、验证集、测试集拆分
X_tt,X_validation,Y_tt,Y_validation =train_test_split(features,label,test_size =0.2)
X_train,X_test,Y_train,Y_test =train_test_split(X_tt,Y_tt,test_size =0.25)
# 训练决策树模型
"""
DecisionTreeClassifier(criterion,max_depth,min_sample_split,min_sample_leaf,min_impurity_decrease,min_impurity_split)
criterion:决定特征顺序的方法 默认为"gini",还有"entropy"
max_depth:设置决策随机森林中的决策树的最大深度,深度越大,越容易过拟合,推荐树的深度为:5-20之间
min_sample_split:设置结点的最小样本数量,当样本数量可能小于此值时,结点将不会在划分。
min_sample_leaf: 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝
min_impurity_decrease: 当不纯度的减小值低于这个值时,则不再生成子节点
min_impurity_split:这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。
"""
dtc =DecisionTreeClassifier(criterion="gini")
# 训练模型
dtc.fit(X_train,Y_train)
# ————决策树可视化
"""
1、下载graphviz(Graph visualization Software) https://www.graphviz.org/download/2、下载完成后 将graphviz 添加到环境变量中 当然也可以使用代码添加到环境变量中
3、代码添加环境变量的方法:
import os
os.environ["path"]+= os.pathsep +"------/bin/""""
# 将graphviz 添加到环境变量
os.environ["PATH"]+= os.pathsep +"D://bin/"
# 导入python与graphviz的接口:pydotplus
"""
pydotplus在anaconda中默认缺省不安装 pip install pydotplus
"""
# 将模型输出为dot数据
dot_data =export_graphviz(dtc,\
out_file = None,\
feature_names = feature_name,\
class_names =["not left","left"],\
filled = True,\
rounded = True,\
special_characters =True)"""
dtc:为需要输出位dot数据的决策树模型
out_file:输出到已存在的dot文件(import stringIO dot_data = StringIO out_file = dot_data_) 否则为None
feature_names:特征名称
class_names:标注的类别
"""
# 使用pydotplus作图
graph = pydotplus.graph_from_dot_data(dot_data)
# 写入pdf文件
graph.write_pdf("./decesion_tree_graph.pdf")
3. SVM算法简介
- 超平面: W T ∗ x + B = 0 W^T*x + B = 0 WT∗x+B=0
- 分界面: W T ∗ x ( p ) + b > = 1 W T ∗ x ( n ) + b < = − 1 W^Tx(p)+b >= 1\ W^Tx(n)+b <= -1 WT∗x(p)+b>=1WT∗x(n)+b<=−1
- 若样本线性可分则采用线性支持向量机
- 若不符合线性可分,则可采取以下两个思路:
- 软间隔 即引入松弛变量
- 扩维:先映射再计算,会产生维度灾难,先计算(低维空间),再升维,需使用核函数
- 核函数:
- 线性核函数
- 高斯径向基(RBF)核函数 可映射至无限维 100%切分
- 多项式核函数
- 相比于决策树 SVM的边界更加平滑
- 解决多分类问题:
- one-other
- one-one
from sklearn.svm importSVCSVC(C,kernel,degree,max_iter,tol,decision_function_shape)C:一个标准被分错后应施加多大的惩罚 默认为1
kernel:核函数 linear poly rbf sigmoid precomputed
degree: n阶多项式
max_iter:最大迭代次数
tol:精度
decision_function_shape: ovo ovr
SVC.coef_
4. 分类——集成算法
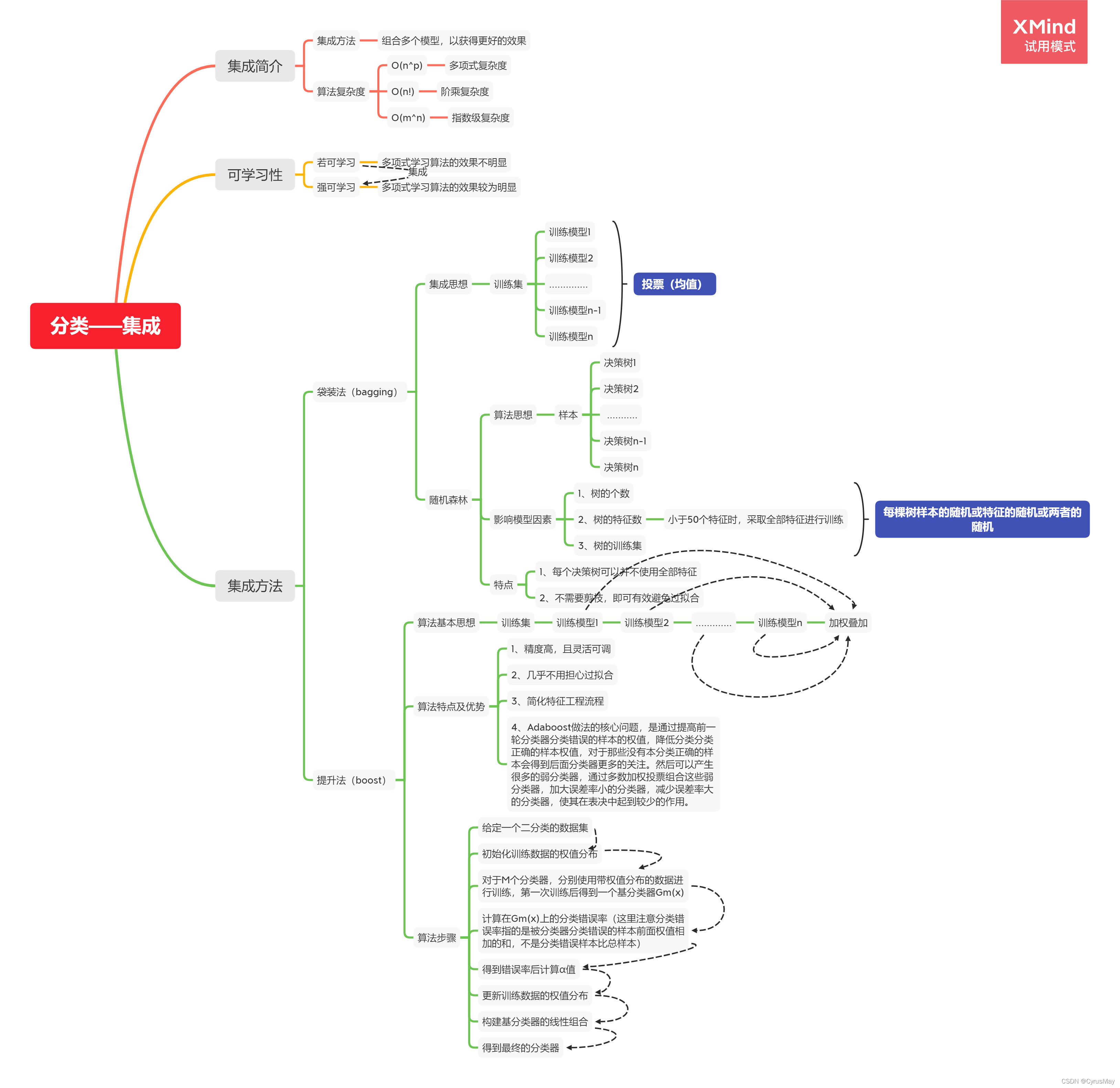
4.1 随机森林参数介绍
from sklearn.ensemble import RandomForestClassifier
RandomForestClassifier()
- n_estimators:决策树的个数
- criterion: 决定特征顺序的方法:“gini”,“entropy”,默认使用gini
- max_features:每棵树的特征 int:特征数 float:所用特征比例 比如0.8 “auto”:默认使用的方式 即取根号 “sqrt”:取根号 “log2” None: 取全量特征
- bootstrap:有放回的取样 或者取全量 True为有放回取样 False为取全样
- oob_score:若有放回取样时,没有取到的数据将被用于评估整体模型的准确性 True/False
- n_jobs:并行数量 默认1 若为-1,则一起并行
4.2 Adaboost算法参数介绍
from sklearn.ensemble import AdaBoostClassifier(base_estimator,n_estimators,learing_rate,algorithm)
- base_estimator:弱分类器 默认为DecisionTreeClassifier
- n_estimators:默认为50个
- algorithm:{SAMME,SAMME.R},默认为使用SAMM.R,即分类器基于概率分类,若使用不是基于概率分类的分类器,则使用SAMME
- learning_rate:权值的衰减率
5 总结
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score,recall_score,precision_score,f1_score
from sklearn.naive_bayes import GaussianNB,BernoulliNB
from sklearn.externals import joblib
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm importSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
features = pd.read_excel("./data.xlsx",sheet_name ="features")
feature_names = features.columns.values
features = features.values
label = pd.read_excel("./data.xlsx",sheet_name ="label").values
# 训练集拆分
X_tt,X_validation,Y_tt,Y_validation =train_test_split(features,label,test_size =0.2)
X_train,X_test,Y_train,Y_test =train_test_split(X_tt,Y_tt,test_size =0.25)
models =[]
# 添加 KNN 分类模型
models.append(("KNN",KNeighborsClassifier(n_neighbors =3)))
# 添加GaussianNB BernoulliNB(高斯朴素贝叶斯和伯努利朴素贝叶斯) 分类模型
models.append(("GaussianNB",GaussianNB()))
models.append(("BernoulliNB",BernoulliNB()))
# 添加决策树分类模型 决定顺序的算法(1)Gini系数 CART算法,(2)信息增益 ID3算法
models.append(("DecisionTree_Gini",DecisionTreeClassifier(criterion="gini")))
models.append(("DecisionTree_entropy",DecisionTreeClassifier(criterion ="entropy",min_impurity_split =0)))
# 添加支持向量机分类模型 SVC
models.append(("SVM Classifier",SVC(C=10**3)))
# 添加集成分类算法中的随机森林算法RandomForest
models.append(("RandomForest",RandomForestClassifier(n_estimators =100)))
# 添加集成分类算法中的AdaBoostClassifier
models.append(('AdaBoost',AdaBoostClassifier(n_estimators =1000)))for clf_name,clf inmodels:
clf.fit(X_train,Y_train)
XY_list =[(X_train,Y_train,"训练集"),(X_validation,Y_validation,"验证集"),(X_test,Y_test,"测试集")]print("*"*15,clf_name,"*"*15)for x,y,data_type inXY_list:
y_predict = clf.predict(x)print(data_type+":")print("\t","ACC:",accuracy_score(y,y_predict))print("\t","PRC:",precision_score(y,y_predict))print("\t","REC:",recall_score(y,y_predict))print("\t","f1 :",f1_score(y,y_predict))
# 决策树可视化
import re
pattern = re.compile("_")
clf_name_new = pattern.split(clf_name)[0]if clf_name_new =="DecisionTree":import pydotplus
from sklearn.tree import export_graphviz
import os
os.environ["PATH"]+= os.pathsep +"D://bin/"
dot_data =export_graphviz(clf,out_file = None,feature_names = feature_names,class_names =["not left","left"],\
filled = True,rounded = True,special_characters = True)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("./"+clf_name+".pdf")
# 模型保存
joblib.dump(clf,clf_name)
by CyrusMay 2022 04 05
本文转载自: https://blog.csdn.net/Cyrus_May/article/details/123970438
版权归原作者 CyrusMay 所有, 如有侵权,请联系我们删除。
版权归原作者 CyrusMay 所有, 如有侵权,请联系我们删除。