
目录
报告内容仅供学习参考,请独立完成作业和实验喔~
一、报告摘要
1.1 实验要求
(1)了解朴素贝叶斯与半朴素贝叶斯的区别与联系,掌握高斯分布、多项式分布和伯努利分布的朴素贝叶斯计算方法。
(2)编程实现朴素贝叶斯分类器,基于多分类数据集,使用朴素贝叶斯分类器实现多分类预测,通过精确率、召回率和F1值度量模型性能。
1.2 实验思路
\qquad
使用Python读取数据集信息并生成对应的朴素贝叶斯分类器,随后使用生成的分类器实现多分类预测,并根据精确率、召回率和F1值度量模型性能。
1.3 实验结论
\qquad
本实验训练了一个高斯分布朴素贝叶斯分类器,并可获得0.94以上的F1度量值,即可准确的完成鸢尾花分类任务。
二、实验内容
2.1 方法介绍
(1)朴素贝叶斯
\qquad
朴素贝叶斯(Naive Bayes)是基于贝叶斯定理与特征独立假设的分类方法。使用朴素贝叶斯方法时,首先基于训练数据,基于特征条件独立假设学习输入与输出的联合概率分布;随后对于给定的X,利用贝叶斯定理求解后验概率最大的输出标签。
朴素贝叶斯本质属于生成模型,学习生成数据的机制,也就是联合概率分布。
(2)半朴素贝叶斯
\qquad
半朴素贝叶斯是适当考虑一部分属性之间的相互依赖信息,其中“独依赖估计”(One-Dependent Estimator,简称ODE)是半朴素分类中最常用的一种策略。所谓“独依赖估计”,也就是假设每个属性在分类类别之外最多仅依赖于一个其他属性。
\qquad
与基于特征的条件独立性假设开展的朴素贝叶斯方法相比,其最大的区别就是半朴素贝叶斯算法放宽了条件独立假设的限制,考虑部分属性之间的相互依赖信息。但两者有共同特点:假设训练样本所有属性变量的值都已被观测到,即训练样本是完整的。
(3)高斯分布朴素贝叶斯计算方法
\qquad
使用条件:所有特征向量都是连续型特征变量且符合高斯分布。
\qquad
概率分布密度:
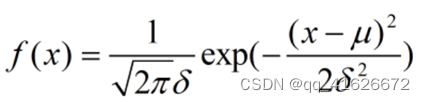
(4)多项式朴素贝叶斯计算方法
\qquad
使用条件:所有的特征变量都是离散型变量且符合多项式分布。
\qquad
概率分布密度:
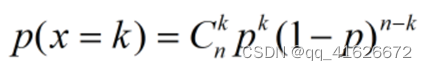
(5)伯努利分布朴素贝叶斯计算方法
\qquad
使用条件:所有的特征变量都是离散型变量且符合伯努利分布。
\qquad
概率分布密度:
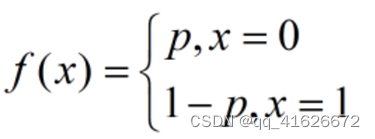
2.2 实验细节
2.2.1 实验环境
硬件环境:Intel® Core™ i5-10300H CPU + 16G RAM
软件环境:Windows 11 家庭中文版 + Python 3.8
2.2.2 实验过程
(1)划分数据集
\qquad
按照实验要求,本次数据集划分采用随机划分80%数据用于训练,其余20%数据用于测试。使用sklearn库的train_test_split()方法划分数据,代码如下:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
(2)训练朴素贝叶斯分类方法
\qquad
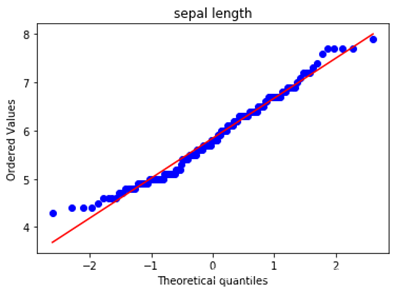
由于实验数据中四个特征变量均为连续型特征变量,我们如果需要使用高斯分布朴素贝叶斯的话,只需要验证他是否符合高斯分布即可。这里使用Q-Q图来验证数据是否符合高斯分布,如果数据符合高斯分布,则该Q-Q图趋近于落在y=x线上,绘制的代码如下:
from scipy.stats import probplot
probplot(data,dist='norm',plot=plt)
plt.title('sepal length')
plt.show()
\qquad
绘制的到结果如下,依次为4个特征向量的Q-Q图。可以看出,4个特征向量整体趋势大致符合高斯分布,可以尝试使用高斯分布朴素贝叶斯分类方法。
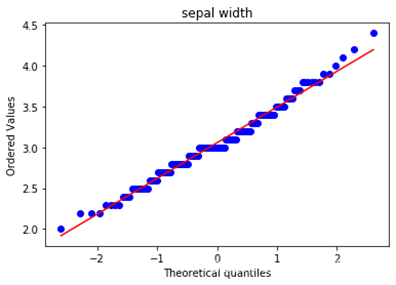
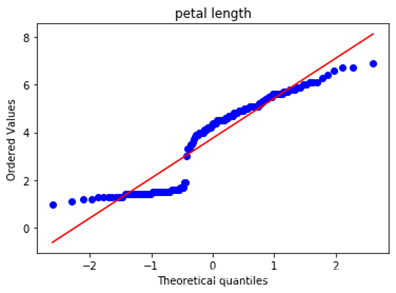
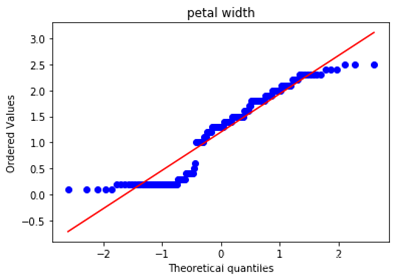
\qquad
使用sklearn库的GaussianNB()方法训练分类器,代码如下:
clf = GaussianNB()
clf.fit(X_train, y_train)
(3)评价分类器
\qquad
使用精确率、召回率、F1度量值对分类器作为评价指标,使用sklearn库中的accuracy_score()、precision_score()、recall_score()、f1_score()方法进行计算,具体代码如下:
y_pred = clf.predict(X_test)print(precision_score(y_test, y_pred, average=None))print(recall_score(y_test, y_pred, average=None))print(f1_score(y_test, y_pred, average=None))
(4)使用分类器进行预测
\qquad
我们选取测试集的最后一条数据进行预测,观察分类器计算得到的概率、分类结果与真实标签的内容。具体代码如下:
y_proba = clf.predict_proba(X_test[:1])
y_pred_num = clf.predict(X_test[:1])[0]print("预测值:"+str(y_pred_num)+" "+label[y_pred_num])print("预计的概率值:", y_proba)print("实际值:"+str(y_test[:1][0])+" "+label[y_test[:1][0]])
\qquad
得到的预测结果如下图所示,可以看出分类器成功完成分类预测。

2.2.3 实验与理论内容的不同点
\qquad
朴素贝叶斯分类器的计算方法不难,在代码实现时,可以直接使用sklearn提供的GaussianNB()方法快速实现。
\qquad
GaussianNB()方法提供两个参数,分别为priors和var_smoothing,即先验概率和所有特征的最大方差添加比例。var_smoothing作用是在估计方差时,为了追求估计的稳定性,将所有特征的方差中最大的方差以var_smoothing给出的比例添加到估计的方差中,默认为1e-9。
\qquad
其余一个不同是在数据的预处理上,由于数据集给出的原始数据集是将特征向量与标签同时给出,且标签为字符型的鸢尾花种类名,不方便后续操作。因此我们将数据预处理为X、y两个数组,分别为特征向量和标签,同时将y中标签重新映射为整数编号,以方便后续处理,具体对照关系如下:
0 -- Iris Setosa,1 -- Iris Versicolour,2 -- Iris Virginica
2.3 实验数据介绍
\qquad
实验数据为来自UCI的鸢尾花三分类数据集Iris Plants Database。
\qquad
数据集共包含150组数据,分为3类,每类50组数据。每组数据包括4个参数和1个分类标签,4个参数分别为:萼片长度sepal length、萼片宽度sepal width、花瓣长度petal length、花瓣宽度petal width,单位均为厘米。分类标签共有三种,分别为Iris Setosa、Iris Versicolour和Iris Virginica。
\qquad
数据集格式如下图所示:
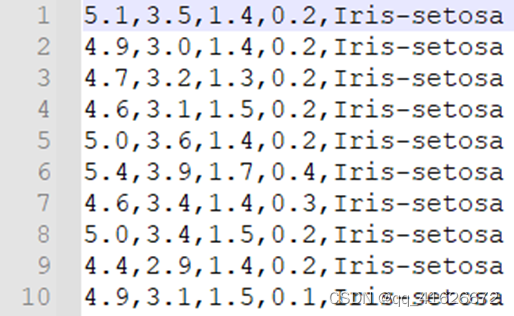
\qquad
为方便后续使用,该数据集需要进行特征向量与标签分割以及标签编号,具体处理方式在2.2.3部分已进行介绍。
2.4 评价指标介绍
\qquad
评价指标选择精确率P、召回率R、F1度量值F1,计算公式如下:
P
=
T
P
T
P
+
F
P
P=\frac{TP}{TP+FP}
P=TP+FPTP
R
=
T
P
T
P
+
F
N
R=\frac{TP}{TP+FN}
R=TP+FNTP
F
1
=
2
∗
P
∗
R
P
+
R
F1=\frac{2*P*R}{P+R}
F1=P+R2∗P∗R
\qquad
具体代码实现时,可以直接调用sklearn库中的相应方法进行计算。
2.5 实验结果分析
\qquad
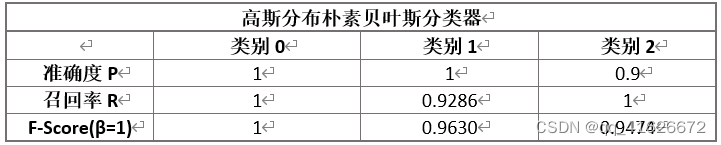
根据计算,对于二分类数据集,可以得到如下结果:
三、总结及问题说明
\qquad
本次实验的主要内容为使用朴素贝叶斯分类鸢尾花三分类数据集,并计算生成模型的精确度Precision、召回率Recall和F1度量值,从而对得到的模型进行评测,评价性能好坏。
\qquad
在本次实验中,未遇到很难解决的问题,得到的分类模型性能较好,可以较准确的完成鸢尾花的分类任务。
四、参考文献
[1] 周志华. 机器学习[M]. 清华大学出版社, 2016.
[2] 朴素贝叶斯算法_经典算法之朴素贝叶斯[EB/OL]. [2022-4-29]. https://blog.csdn.net/weixin_39637975/article/details/111373577.
[3] sklearn.naive_bayes.GaussianNB — scikit-learn 1.1.0 documentation[EB/OL]. [2022-4-29]. https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.GaussianNB.html.
附录:实验代码
import numpy as np
from sklearn import datasets
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
import random
label =['Iris Setosa','Iris Versicolour','Iris Virginica']
X, y = datasets.load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)# 使用高斯朴素贝叶斯进行计算
clf = GaussianNB()
clf.fit(X_train, y_train)from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
# 评估
y_pred = clf.predict(X_test)print(precision_score(y_test, y_pred, average=None))print(recall_score(y_test, y_pred, average=None))print(f1_score(y_test, y_pred, average=None))# 预测
y_proba = clf.predict_proba(X_test[:1])
y_pred_num = clf.predict(X_test[:1])[0]print("预测值:"+str(y_pred_num)+" "+label[y_pred_num])print("预计的概率值:", y_proba)print("实际值:"+str(y_test[:1][0])+" "+label[y_test[:1][0]])
本文转载自: https://blog.csdn.net/qq_41626672/article/details/127511187
版权归原作者 qq_41626672 所有, 如有侵权,请联系我们删除。
版权归原作者 qq_41626672 所有, 如有侵权,请联系我们删除。