
本节开始笔者针对自己的研究领域进行RL方面的介绍和笔记总结,欢迎同行学者一起学习和讨论。本文笔者来介绍RL中比较出名的算法PPO算法,读者需要预先了解Reinforcement-Learning中几个基础定义才可以阅读,否则不容易理解其中的内容。不过笔者尽可能把它写的详细让读者弄懂。本文干货内容较多,注重算法理解和数学基础而不仅仅是算法实现。
本文一定程度上参考了李宏毅"Reinforcement-Learning"
本文内容不难,适合想要学习RL的初学者进行预备,PPO是OpenAI的默认RL框架,足以见得它的强大。
1、预备知识
1.1、策略梯度
首先笔者来介绍策略梯度算法,为后续的内容做铺垫,首先给予读者一些RL中基本定义:
1.State:状态,也即智能体(Agent)当前所处的环境是什么?
(
s
)
(s)
(s)
2.Action:动作,也即Agent在当前可以采取的行动是什么?
(
a
)
(a)
(a)(该行为我们可以通过网络可控)
3.Reward:奖励,也即Agent在当前状态下采取动作Action后得到了多大的奖励?
(
r
)
(r)
(r)
首先,设置Agent采取的总步长为
t
t
t,这也即我们获得了一条轨迹(trajectory):
τ
\tau
τ:
τ
=
(
s
1
,
a
1
,
r
1
,
s
2
,
a
2
,
r
2
⋅
⋅
⋅
⋅
s
t
,
a
t
,
r
t
)
,
R
(
τ
)
=
∑
i
=
1
t
r
t
\tau=(s_1,a_1,r_1,s_2,a_2,r_2····s_t,a_t,r_t),R(\tau)=\sum_{i=1}^{t}r_t
τ=(s1,a1,r1,s2,a2,r2⋅⋅⋅⋅st,at,rt),R(τ)=i=1∑trt
事实上,上述的1,2,3中我们只有2是可控的,其他的1,3为从环境中获取的,是无法人为干预的。假设我们拥有一个具有网络参数为
θ
\theta
θ的**策略**
π
θ
(
a
t
∣
s
t
)
\pi_\theta(a_t|s_t)
πθ(at∣st),那么显然我们的目标是想要使得总Reward越大越好,但由于该奖励为一个随机变量,因此我们只能求得它的期望。**即target任务为最大化以下函数**:
E
τ
[
R
(
τ
)
]
=
∫
p
θ
(
τ
)
R
(
τ
)
E_{\tau}[R(\tau)]=\int p_{\theta}(\tau)R(\tau)
Eτ[R(τ)]=∫pθ(τ)R(τ)
为了让上述期望最大化,我们需要策略梯度,即:
∇
θ
E
τ
[
R
(
τ
)
]
=
∫
∇
θ
p
θ
(
τ
)
R
(
τ
)
=
∫
p
θ
(
τ
)
∇
θ
l
o
g
(
p
θ
(
τ
)
)
R
(
τ
)
\nabla_{\theta} E_{\tau}[R(\tau)]=\int \nabla_{{\theta}} p_{\theta}(\tau)R(\tau)=\int p_{\theta}(\tau)\nabla_{{\theta}} log(p_{\theta}(\tau))R(\tau)
∇θEτ[R(τ)]=∫∇θpθ(τ)R(τ)=∫pθ(τ)∇θlog(pθ(τ))R(τ)
以下简称策略梯度
∇
θ
E
τ
[
R
(
τ
)
]
=
∇
∗
\nabla_{\theta} E_{\tau}[R(\tau)]=\nabla^*
∇θEτ[R(τ)]=∇∗,由上述推导我们可知:
∇
∗
=
∫
p
θ
(
τ
)
∇
θ
l
o
g
(
p
θ
(
τ
)
)
R
(
τ
)
=
E
τ
[
∇
θ
l
o
g
(
p
θ
(
τ
)
)
R
(
τ
)
]
\nabla^*=\int p_{\theta}(\tau)\nabla_{{\theta}} log(p_{\theta}(\tau))R(\tau)=E_{\tau}[\nabla_{{\theta}} log(p_{\theta}(\tau))R(\tau)]
∇∗=∫pθ(τ)∇θlog(pθ(τ))R(τ)=Eτ[∇θlog(pθ(τ))R(τ)]
由于
p
θ
(
τ
)
=
∏
i
=
1
t
π
θ
(
a
t
∣
s
t
)
p_\theta(\tau)=\prod_{i=1}^{t}\pi_{\theta}(a_t|s_t)
pθ(τ)=∏i=1tπθ(at∣st),故代入有:
∇
∗
=
E
τ
[
R
(
τ
)
]
=
E
τ
[
R
(
τ
)
∑
i
=
1
t
∇
l
o
g
(
π
θ
(
a
i
∣
s
i
)
)
]
\nabla^*=E_{\tau}[R(\tau)]=E_{\tau}[R(\tau)\sum_{i=1}^t\nabla log(\pi_\theta(a_i|s_i))]
∇∗=Eτ[R(τ)]=Eτ[R(τ)i=1∑t∇log(πθ(ai∣si))]
因此,在实际应用的时候,用sampling的办法,应该做一些的更新方式(
l
r
lr
lr为学习率):
∇
∗
=
1
s
∑
k
=
1
s
∑
i
=
1
t
R
(
τ
k
)
∇
l
o
g
(
π
θ
(
a
i
k
∣
s
i
k
)
)
\nabla^*=\frac{1}{s}\sum_{k=1}^{s}\sum_{i=1}^t R(\tau^k) \nabla log(\pi_\theta(a_i^{k}|s_i^{k}))
∇∗=s1k=1∑si=1∑tR(τk)∇log(πθ(aik∣sik))
θ
=
θ
+
l
r
∇
∗
\theta=\theta+lr\nabla^*
θ=θ+lr∇∗
但是,该
∇
∗
\nabla^*
∇∗存在以下的缺陷。
1.1.1、策略梯度缺陷(1)
首先针对
∇
∗
\nabla^*
∇∗而言,直观的理解为,若某一条轨迹
τ
\tau
τ得到的奖励总和
R
(
τ
)
R(\tau)
R(τ)为正(positive)的,那么该策略梯度会升高产生这条轨迹的每一步骤产生的概率大小,若
τ
\tau
τ得到的奖励总和
R
(
τ
)
R(\tau)
R(τ)为负(negative)的,那么该策略梯度会降低产生该条轨迹的概率大小,但若奖励总和
R
(
τ
)
R(\tau)
R(τ)总为positive的,那该策略梯度会受到一定的影响。虽然Reward的大小可以反应策略梯度上升的快慢大小,但是由于动作是通过Sample来获取的,因此会产生某些"好的动作"没办法被偶然采样到,那么该好的动作就容易被忽略掉。因此一般会采用以下更新策略梯度方式来更新,保证
R
(
τ
)
R(\tau)
R(τ)有正有负。
∇
∗
=
E
τ
[
(
R
(
τ
)
−
b
)
∑
i
=
1
t
∇
l
o
g
(
π
θ
(
a
i
∣
s
i
)
)
]
=
E
τ
[
∑
i
=
1
t
(
R
(
τ
)
−
b
)
∇
l
o
g
(
π
θ
(
a
i
∣
s
i
)
)
]
\nabla^*=E_{\tau}[(R(\tau)-b)\sum_{i=1}^t\nabla log(\pi_\theta(a_i|s_i))]=E_{\tau}[\sum_{i=1}^t(R(\tau)-b)\nabla log(\pi_\theta(a_i|s_i))]
∇∗=Eτ[(R(τ)−b)i=1∑t∇log(πθ(ai∣si))]=Eτ[i=1∑t(R(τ)−b)∇log(πθ(ai∣si))]
其中
b
b
b为待定参数,可以为人工设定或者其他办法获得。
1.1.2、策略梯度缺陷(2)
策略梯度的缺陷之二是:针对,更新时刻每一步
π
θ
(
a
i
∣
s
i
)
\pi_{\theta}(a_i|s_i)
πθ(ai∣si),他们共用一个
R
(
τ
)
R(\tau)
R(τ),这会带来很大的问题,因为显然地,一个轨迹的总Reward高不见得每一步的Reward都要求的是好(高)的并且完美的,而是一个整体的现象。如果单纯用一整条轨迹更新轨迹中每个操作显得很不满足条件。
因此,常见的处理办法之一为:采用未来折扣回报来代替
R
(
τ
)
R(\tau)
R(τ):
其中第
i
i
i步时的未来折扣回报的定义为:
∑
k
=
i
t
δ
k
−
i
r
k
\sum_{k=i}^t\delta^{k-i}r_k
∑k=itδk−irk,代表了从第
i
i
i步到结束的带有折扣因子
δ
\delta
δ的未来总奖励大小。
因此策略梯度被写成了如下情况:
∇
∗
=
E
τ
[
∑
i
=
1
t
(
∑
k
=
i
t
δ
k
−
i
r
k
−
b
)
∇
l
o
g
(
π
θ
(
a
i
∣
s
i
)
)
]
\nabla^*=E_{\tau}[\sum_{i=1}^t(\sum_{k=i}^t\delta^{k-i}r_k -b)\nabla log(\pi_\theta(a_i|s_i))]
∇∗=Eτ[i=1∑t(k=i∑tδk−irk−b)∇log(πθ(ai∣si))]
往往,某些时刻,我们可以将未来折扣回报
∑
k
=
i
t
δ
k
−
i
r
k
\sum_{k=i}^t\delta^{k-i}r_k
∑k=itδk−irk视为在当前
s
i
s_i
si下,采取了动作
a
i
a_i
ai,未来给了我多少奖励,也即当前状态
s
i
s_i
si下,采取了动作
a
i
a_i
ai的好坏程度,这通常称之为**状态价值函数**,一般用
Q
(
s
i
,
a
i
)
Q(s_i,a_i)
Q(si,ai)来表示,通常情况下,**未来折扣回报**是通过
Q
(
s
i
,
a
i
)
Q(s_i,a_i)
Q(si,ai)来进行估计的,若将其也视为一个网络,参数为
δ
\delta
δ,这即:
∇
∗
=
E
τ
[
∑
i
=
1
t
Q
δ
(
s
i
,
a
i
)
∇
l
o
g
(
π
θ
(
a
i
∣
s
i
)
)
]
\nabla^*=E_{\tau}[\sum_{i=1}^tQ_{\delta}(s_i,a_i)\nabla log(\pi_\theta(a_i|s_i))]
∇∗=Eτ[i=1∑tQδ(si,ai)∇log(πθ(ai∣si))]
则想要更新参数时,可以首先采样出一系列轨迹
(
τ
1
,
τ
2
,
τ
3
⋅
⋅
⋅
⋅
⋅
τ
k
)
(\tau_1,\tau_2,\tau_3·····\tau_k)
(τ1,τ2,τ3⋅⋅⋅⋅⋅τk),并进行策略梯度的更新:
∇
∗
=
∑
m
=
1
k
∑
i
=
1
t
Q
δ
(
s
i
m
,
a
i
m
)
∇
l
o
g
(
π
θ
(
a
i
m
∣
s
i
m
)
)
\nabla^*=\sum_{m=1}^k\sum_{i=1}^tQ_{\delta}(s_i^{m},a_i^{m})\nabla log(\pi_\theta(a_i^{m}|s_i^{m}))
∇∗=m=1∑ki=1∑tQδ(sim,aim)∇log(πθ(aim∣sim))
θ
=
θ
+
l
r
∇
∗
\theta=\theta+lr\nabla^*
θ=θ+lr∇∗当然,这是针对某一个整条轨迹做更新的,那么如果想要按照时间步长逐步更新(第
l
l
l步):
∇
l
∗
=
∑
m
=
1
k
Q
δ
(
s
l
m
,
a
l
m
)
∇
l
o
g
(
π
θ
(
a
l
m
∣
s
l
m
)
)
\nabla_{l}^*=\sum_{m=1}^kQ_{\delta}(s_l^{m},a_l^{m})\nabla log(\pi_\theta(a_l^{m}|s_l^{m}))
∇l∗=m=1∑kQδ(slm,alm)∇log(πθ(alm∣slm))这也即采样了一个Batch的第
l
l
l步的
(
s
l
,
a
l
)
(s_l,a_l)
(sl,al)信息后,进行的梯度更新:
∇
l
∗
=
E
a
l
~
π
θ
(
a
l
∣
s
l
)
[
(
Q
δ
(
s
l
m
,
a
l
m
)
∇
l
o
g
(
π
θ
(
a
l
m
∣
s
l
m
)
)
]
\nabla_{l}^*=E_{a_l~\pi_\theta(a_l|s_l)}[(Q_{\delta}(s_l^{m},a_l^{m})\nabla log(\pi_\theta(a_l^{m}|s_l^{m}))]
∇l∗=Eal~πθ(al∣sl)[(Qδ(slm,alm)∇log(πθ(alm∣slm))]策略梯度有个明显的缺点,就是更新过后,网络
π
θ
\pi_{\theta}
πθ就发生了改变,而策略梯度是要基于
π
θ
\pi_{\theta}
πθ进行采样的,因此,**之前的采样样本就失效了**,也即参数只能被更新一次,之后需要根据更新后的重新采集样本。这显然用起来非常不方便,理想情况下如果能够进行off-policy更新,即某个样本可以被反复更新而不需重采样,这就需要1.2的重要性采样过程。
1.2、Important-Sampling
设需要估计
E
x
~
p
[
f
(
x
)
]
E_{x~p}[f(x)]
Ex~p[f(x)],但是无法从
p
(
x
)
p(x)
p(x)中进行sampling,只能从一个以知的分布
q
(
x
)
q(x)
q(x)进行采样,那如何计算所要求的期望?
事实上:
E
x
~
p
[
f
(
x
)
]
=
∫
p
(
x
)
f
(
x
)
=
∫
q
(
x
)
p
(
x
)
q
(
x
)
f
(
x
)
=
E
x
~
q
[
p
(
x
)
q
(
x
)
f
(
x
)
]
E_{x~p}[f(x)]=\int p(x)f(x)=\int q(x)\frac{p(x)}{q(x)}f(x)=E_{x~q}[\frac{p(x)}{q(x)}f(x)]
Ex~p[f(x)]=∫p(x)f(x)=∫q(x)q(x)p(x)f(x)=Ex~q[q(x)p(x)f(x)]
即
E
x
~
p
[
f
(
x
)
]
=
E
x
~
q
[
p
(
x
)
q
(
x
)
f
(
x
)
]
E_{x~p}[f(x)]=E_{x~q}[\frac{p(x)}{q(x)}f(x)]
Ex~p[f(x)]=Ex~q[q(x)p(x)f(x)]
这是理论相等,但是存在如下问题:
V
a
r
x
~
p
[
f
(
x
)
]
=
E
x
~
p
[
f
2
(
x
)
]
−
(
E
x
~
p
[
f
(
x
)
]
)
2
Var_{x~p}[f(x)]=E_{x~p}[f^2(x)]-(E_{x~p}[f(x)])^2
Varx~p[f(x)]=Ex~p[f2(x)]−(Ex~p[f(x)])2
V
a
r
x
~
q
[
p
(
x
)
q
(
x
)
f
(
x
)
]
=
E
x
~
q
[
p
2
(
x
)
q
2
(
x
)
f
2
(
x
)
]
−
(
E
x
~
p
[
f
(
x
)
]
)
2
Var_{x~q}[\frac{p(x)}{q(x)}f(x)]=E_{x~q}[\frac{p^2(x)}{q^2(x)}f^2(x)]-(E_{x~p}[f(x)])^2
Varx~q[q(x)p(x)f(x)]=Ex~q[q2(x)p2(x)f2(x)]−(Ex~p[f(x)])2
E
x
~
q
[
p
2
(
x
)
q
2
(
x
)
f
2
(
x
)
]
=
∫
p
2
(
x
)
q
(
x
)
f
2
(
x
)
=
∫
p
(
x
)
q
(
x
)
p
(
x
)
f
2
(
x
)
E_{x~q}[\frac{p^2(x)}{q^2(x)}f^2(x)]=\int \frac{p^2(x)}{q(x)}f^2(x)=\int \frac{p(x)}{q(x)}p(x)f^2(x)
Ex~q[q2(x)p2(x)f2(x)]=∫q(x)p2(x)f2(x)=∫q(x)p(x)p(x)f2(x)
E
x
~
p
[
f
2
(
x
)
]
=
∫
p
(
x
)
f
2
(
x
)
E_{x~p}[f^2(x)]=\int p(x)f^2(x)
Ex~p[f2(x)]=∫p(x)f2(x)
很明显若
p
(
x
)
q
(
x
)
>
>
1
\frac{p(x)}{q(x)}>>1
q(x)p(x)>>1,此时
V
a
r
x
~
q
[
p
(
x
)
q
(
x
)
f
(
x
)
]
>
>
V
a
r
x
~
p
[
f
(
x
)
]
Var_{x~q}[\frac{p(x)}{q(x)}f(x)]>>Var_{x~p}[f(x)]
Varx~q[q(x)p(x)f(x)]>>Varx~p[f(x)]
即,若通过采样的办法,两个分布的差异不能太大,若进行的话,采样是不准确的,甚至是失真的。
为了可以用到RL中进行off-policy的更新,我们需要定义两个策略网络,一个是
π
θ
′
\pi_{\theta^{'}}
πθ′专门负责进行采样操作,一个是
π
θ
\pi_{\theta}
πθ,为待学习的网络参数,相应的,还存在两个**价值网络**,一个参数为
δ
′
\delta^{'}
δ′负责给予探索的动作打分,一个参数为
δ
\delta
δ为待学习的参数,则此时
∇
l
∗
=
E
a
l
~
π
θ
(
a
l
∣
s
l
)
[
(
Q
δ
(
s
l
m
,
a
l
m
)
∇
l
o
g
(
π
θ
(
a
l
m
∣
s
l
m
)
)
]
\nabla_{l}^*=E_{a_l~\pi_\theta(a_l|s_l)}[(Q_{\delta}(s_l^{m},a_l^{m})\nabla log(\pi_\theta(a_l^{m}|s_l^{m}))]
∇l∗=Eal~πθ(al∣sl)[(Qδ(slm,alm)∇log(πθ(alm∣slm))]根据Important-Sampling原理可进行如下替换,并且可以更新多步而不局限于更新一次:
∇
l
∗
=
E
a
l
~
π
θ
′
(
a
l
∣
s
l
)
[
π
θ
(
a
l
∣
s
l
)
π
θ
′
(
a
l
∣
s
l
)
(
Q
δ
′
(
s
l
m
,
a
l
m
)
∇
l
o
g
(
π
θ
(
a
l
m
∣
s
l
m
)
)
]
\nabla_{l}^*=E_{a_l~\pi_\theta^{'}(a_l|s_l)}[\frac{\pi_\theta(a_l|s_l)}{\pi_\theta^{'}(a_l|s_l)}(Q_{\delta^{'}}(s_l^{m},a_l^{m})\nabla log(\pi_\theta(a_l^{m}|s_l^{m}))]
∇l∗=Eal~πθ′(al∣sl)[πθ′(al∣sl)πθ(al∣sl)(Qδ′(slm,alm)∇log(πθ(alm∣slm))]
进行整理后得到:
∇
l
∗
=
∫
π
θ
(
s
l
∣
a
l
)
[
(
Q
δ
(
s
l
m
,
a
l
m
)
∇
l
o
g
(
π
θ
(
a
l
m
∣
s
l
m
)
)
]
=
∫
Q
δ
(
s
l
m
,
a
l
m
)
∇
π
θ
(
s
l
∣
a
l
)
\nabla_{l}^*=\int \pi_\theta(s_l|a_l)[(Q_{\delta}(s_l^{m},a_l^{m})\nabla log(\pi_\theta(a_l^{m}|s_l^{m}))]=\int Q_{\delta}(s_l^{m},a_l^{m})\nabla \pi_\theta(s_l|a_l)
∇l∗=∫πθ(sl∣al)[(Qδ(slm,alm)∇log(πθ(alm∣slm))]=∫Qδ(slm,alm)∇πθ(sl∣al)
若目标函数称为为
J
l
(
θ
)
J_l(\theta)
Jl(θ),令
∇
J
l
=
∇
l
∗
\nabla J_l=\nabla_{l}^*
∇Jl=∇l∗则
J
l
(
θ
)
=
E
a
l
~
π
θ
(
a
l
∣
s
l
)
[
Q
δ
(
s
l
m
,
a
l
m
)
]
=
E
a
l
~
π
θ
′
(
a
l
∣
s
l
)
[
π
θ
(
a
l
∣
s
l
)
π
θ
′
(
a
l
∣
s
l
)
Q
δ
′
(
s
l
m
,
a
l
m
)
]
J_l(\theta)=E_{a_l~\pi_\theta(a_l|s_l)}[Q_{\delta}(s_l^{m},a_l^{m})]=E_{a_l~\pi_\theta^{'}(a_l|s_l)}[\frac{\pi_\theta(a_l|s_l)}{\pi_\theta^{'}(a_l|s_l)}Q_{\delta^{'}}(s_l^{m},a_l^{m})]
Jl(θ)=Eal~πθ(al∣sl)[Qδ(slm,alm)]=Eal~πθ′(al∣sl)[πθ′(al∣sl)πθ(al∣sl)Qδ′(slm,alm)]
那么,每一次主需要计算
J
l
(
θ
)
J_l(\theta)
Jl(θ),在第
l
l
l步进行更新即可:
θ
=
θ
+
l
r
∇
θ
J
l
(
θ
)
\theta=\theta+lr\nabla_\theta J_l(\theta)
θ=θ+lr∇θJl(θ)
2、置信策略优化(TRPO)与近端策略优化(PPO)
2.1、TRPO与PPO的区别
根据1节所讨论的部分,下面介绍这两种算法的本质区别,在1.2节已经提到了,要想使用Important-Samlping办法,那么两个策略网络的差异不能够太大,否则将会出现估计失真的情况。根据此,TRPO的策略优化函数需要满足以下两个条件为:
J
l
T
R
P
O
(
θ
)
=
E
a
l
~
π
θ
′
(
a
l
∣
s
l
)
[
π
θ
(
a
l
∣
s
l
)
π
θ
′
(
a
l
∣
s
l
)
Q
δ
′
(
s
l
m
,
a
l
m
)
]
J^{TRPO}_l(\theta)=E_{a_l~\pi_\theta^{'}(a_l|s_l)}[\frac{\pi_\theta(a_l|s_l)}{\pi_\theta^{'}(a_l|s_l)}Q_{\delta^{'}}(s_l^{m},a_l^{m})]
JlTRPO(θ)=Eal~πθ′(al∣sl)[πθ′(al∣sl)πθ(al∣sl)Qδ′(slm,alm)]
E
l
(
K
L
[
π
θ
′
(
⋅
∣
s
l
)
∣
∣
π
θ
(
⋅
∣
s
l
)
]
)
≤
β
E_{l}(KL[\pi_\theta^{'}(·|s_l)||\pi_\theta(·|s_l)])\leq\beta
El(KL[πθ′(⋅∣sl)∣∣πθ(⋅∣sl)])≤β
其中
β
\beta
β为超参数,这很麻烦,因为不仅需要进行策略梯度更新,还需要进行条件约束,相比之下,**PPO**采用了罚函数办法:
J
l
P
P
O
1
(
θ
)
=
E
a
l
~
π
θ
′
(
a
l
∣
s
l
)
[
π
θ
(
a
l
∣
s
l
)
π
θ
′
(
a
l
∣
s
l
)
Q
δ
′
(
s
l
m
,
a
l
m
)
−
β
K
L
[
π
θ
′
(
⋅
∣
s
l
)
∣
∣
π
θ
(
⋅
∣
s
l
)
]
]
J^{PPO1}_l(\theta)=E_{a_l~\pi_\theta^{'}(a_l|s_l)}[\frac{\pi_\theta(a_l|s_l)}{\pi_\theta^{'}(a_l|s_l)}Q_{\delta^{'}}(s_l^{m},a_l^{m})-\beta KL[\pi_\theta^{'}(·|s_l)||\pi_\theta(·|s_l)] ]
JlPPO1(θ)=Eal~πθ′(al∣sl)[πθ′(al∣sl)πθ(al∣sl)Qδ′(slm,alm)−βKL[πθ′(⋅∣sl)∣∣πθ(⋅∣sl)]]
当发现
K
L
[
π
θ
′
(
⋅
∣
s
l
)
∣
∣
π
θ
(
⋅
∣
s
l
)
]
>
a
∗
1.5
KL[\pi_\theta^{'}(·|s_l)||\pi_\theta(·|s_l)]>a*1.5
KL[πθ′(⋅∣sl)∣∣πθ(⋅∣sl)]>a∗1.5,此时说明两个分布差异过大,需要增大惩罚系数,此时
β
→
2
β
\beta \rightarrow 2\beta
β→2β
当发现
K
L
[
π
θ
′
(
⋅
∣
s
l
)
∣
∣
π
θ
(
⋅
∣
s
l
)
]
<
a
/
1.5
KL[\pi_\theta^{'}(·|s_l)||\pi_\theta(·|s_l)]<a/1.5
KL[πθ′(⋅∣sl)∣∣πθ(⋅∣sl)]<a/1.5,此时说明两个分布差异很小,需要调小惩罚系数,此时
β
→
β
/
2
\beta \rightarrow \beta/2
β→β/2
2.2、Clip-PPO
OpenAI给出了另外一种裁剪PPO,下面笔者来介绍它的具体思想。
上面已经介绍过了,PPO的目的是为了缓解Important-Sampling差异较大带来的影响,若不加以任何限制,原始的目标优化函数为:
J
l
(
θ
)
=
E
a
l
~
π
θ
′
(
a
l
∣
s
l
)
[
π
θ
(
a
l
∣
s
l
)
π
θ
′
(
a
l
∣
s
l
)
Q
δ
′
(
s
l
m
,
a
l
m
)
]
J_l(\theta)=E_{a_l~\pi_\theta^{'}(a_l|s_l)}[\frac{\pi_\theta(a_l|s_l)}{\pi_\theta^{'}(a_l|s_l)}Q_{\delta^{'}}(s_l^{m},a_l^{m})]
Jl(θ)=Eal~πθ′(al∣sl)[πθ′(al∣sl)πθ(al∣sl)Qδ′(slm,alm)]
现分成两种情况来介绍:
(1)
Q
δ
′
(
s
l
m
,
a
l
m
)
>
0
Q_{\delta^{'}}(s_l^{m},a_l^{m})>0
Qδ′(slm,alm)>0
此时说明,这个动作很好,应该加大该
π
θ
(
a
l
∣
s
l
)
\pi_\theta(a_l|s_l)
πθ(al∣sl)的概率,那么这个时候显然的,会增大对应的
π
θ
(
a
l
∣
s
l
)
π
θ
′
(
a
l
∣
s
l
)
\frac{\pi_\theta(a_l|s_l)}{\pi_\theta^{'}(a_l|s_l)}
πθ′(al∣sl)πθ(al∣sl)的概率,为了避免出现该值过分的增大,OpenAI提出了Clip方法,即设定一个上限
(
1
+
ϵ
)
(
1
+
0.2
)
(1+\epsilon)(1+0.2)
(1+ϵ)(1+0.2)不允许超过。
即:
J
l
P
P
O
2
(
θ
)
=
E
a
l
~
π
θ
′
(
a
l
∣
s
l
)
[
m
i
n
(
π
θ
(
a
l
∣
s
l
)
π
θ
′
(
a
l
∣
s
l
)
Q
δ
′
(
s
l
m
,
a
l
m
)
,
(
1
+
ϵ
)
Q
δ
′
(
s
l
m
,
a
l
m
)
)
]
J^{PPO2}_l(\theta)=E_{a_l~\pi_\theta^{'}(a_l|s_l)}[min(\frac{\pi_\theta(a_l|s_l)}{\pi_\theta^{'}(a_l|s_l)}Q_{\delta^{'}}(s_l^{m},a_l^{m}),(1+\epsilon)Q_{\delta^{'}}(s_l^{m},a_l^{m}))]
JlPPO2(θ)=Eal~πθ′(al∣sl)[min(πθ′(al∣sl)πθ(al∣sl)Qδ′(slm,alm),(1+ϵ)Qδ′(slm,alm))]对应的图示情况为:(A即为这里的Q)
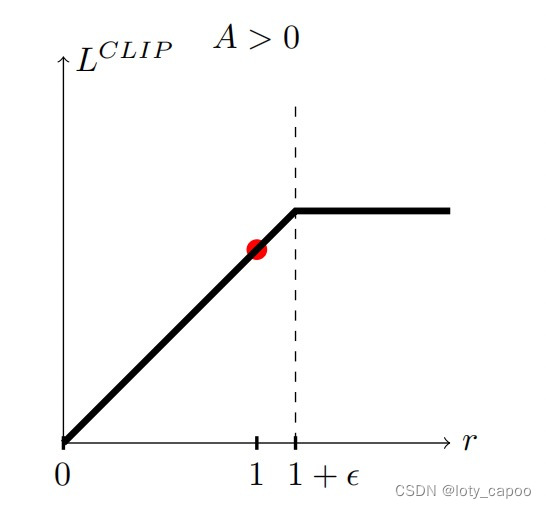
(2)
Q
δ
′
(
s
l
m
,
a
l
m
)
<
0
Q_{\delta^{'}}(s_l^{m},a_l^{m})<0
Qδ′(slm,alm)<0
此时说明,这个动作不是很好,应该减小该
π
θ
(
a
l
∣
s
l
)
\pi_\theta(a_l|s_l)
πθ(al∣sl)的概率,那么这个时候显然的,会减小对应的
π
θ
(
a
l
∣
s
l
)
π
θ
′
(
a
l
∣
s
l
)
\frac{\pi_\theta(a_l|s_l)}{\pi_\theta^{'}(a_l|s_l)}
πθ′(al∣sl)πθ(al∣sl)的概率,为了避免出现该值过分的减小,OpenAI提出了反向的Clip方法,即设定一个下限
(
1
−
ϵ
)
(
1
−
0.2
)
(1-\epsilon)(1-0.2)
(1−ϵ)(1−0.2)不允许低于。
即:
J
l
P
P
O
2
(
θ
)
=
E
a
l
~
π
θ
′
(
a
l
∣
s
l
)
[
m
a
x
(
π
θ
(
a
l
∣
s
l
)
π
θ
′
(
a
l
∣
s
l
)
Q
δ
′
(
s
l
m
,
a
l
m
)
,
(
1
−
ϵ
)
Q
δ
′
(
s
l
m
,
a
l
m
)
)
]
J^{PPO2}_l(\theta)=E_{a_l~\pi_\theta^{'}(a_l|s_l)}[max(\frac{\pi_\theta(a_l|s_l)}{\pi_\theta^{'}(a_l|s_l)}Q_{\delta^{'}}(s_l^{m},a_l^{m}),(1-\epsilon)Q_{\delta^{'}}(s_l^{m},a_l^{m}))]
JlPPO2(θ)=Eal~πθ′(al∣sl)[max(πθ′(al∣sl)πθ(al∣sl)Qδ′(slm,alm),(1−ϵ)Qδ′(slm,alm))]对应的图示情况为

汇总起来以上两种情况,那么就相当于目标函数为
J
l
P
P
O
2
(
θ
)
=
E
a
l
~
π
θ
′
(
a
l
∣
s
l
)
[
m
i
n
(
π
θ
(
a
l
∣
s
l
)
π
θ
′
(
a
l
∣
s
l
)
Q
δ
′
(
s
l
m
,
a
l
m
)
,
C
L
I
P
[
π
θ
(
a
l
∣
s
l
)
π
θ
′
(
a
l
∣
s
l
)
,
(
1
+
ϵ
)
,
(
1
−
ϵ
)
]
Q
δ
′
(
s
l
m
,
a
l
m
)
)
]
J^{PPO2}_l(\theta)=E_{a_l~\pi_\theta^{'}(a_l|s_l)}[min(\frac{\pi_\theta(a_l|s_l)}{\pi_\theta^{'}(a_l|s_l)}Q_{\delta^{'}}(s_l^{m},a_l^{m}),CLIP[\frac{\pi_\theta(a_l|s_l)}{\pi_\theta^{'}(a_l|s_l)},(1+\epsilon),(1-\epsilon)]Q_{\delta^{'}}(s_l^{m},a_l^{m}))]
JlPPO2(θ)=Eal~πθ′(al∣sl)[min(πθ′(al∣sl)πθ(al∣sl)Qδ′(slm,alm),CLIP[πθ′(al∣sl)πθ(al∣sl),(1+ϵ),(1−ϵ)]Qδ′(slm,alm))]
其中CLIP被定义为如下函数
C
L
I
P
[
π
θ
(
a
l
∣
s
l
)
π
θ
′
(
a
l
∣
s
l
)
,
(
1
+
ϵ
)
,
(
1
−
ϵ
)
]
CLIP[\frac{\pi_\theta(a_l|s_l)}{\pi_\theta^{'}(a_l|s_l)},(1+\epsilon),(1-\epsilon)]
CLIP[πθ′(al∣sl)πθ(al∣sl),(1+ϵ),(1−ϵ)]
它代表着
π
θ
(
a
l
∣
s
l
)
π
θ
′
(
a
l
∣
s
l
)
\frac{\pi_\theta(a_l|s_l)}{\pi_\theta^{'}(a_l|s_l)}
πθ′(al∣sl)πθ(al∣sl)超过
(
1
+
ϵ
)
(1+\epsilon)
(1+ϵ)的部分被截断为
(
1
+
ϵ
)
(1+\epsilon)
(1+ϵ),低于
(
1
−
ϵ
)
(1-\epsilon)
(1−ϵ)的部分被截断为
(
1
−
ϵ
)
(1-\epsilon)
(1−ϵ)。
3、总结
PPO思想还是很简单的,主要是针对Important-Sampling产生的不稳定性进行了CLIP操作和罚函数法,相比TRPO方法更简单容易实现,有了策略梯度的定义,可以结合其他Actor-Critic进行联合使用更新,并且PPO将策略梯度缺陷的on-policy变为了off-policy,更大可能的利用了采样样本,效率和速度都有了一定的提升。
版权归原作者 lotylotylotyloty 所有, 如有侵权,请联系我们删除。