
一篇弄懂交叉熵损失函数
一、定义
机器学习中所有的算法都需要最大化或最小化一个函数,这个函数被称为“目标函数”。其中,我们一般把最小化的一类函数,称为“损失函数”。它能根据预测结果,衡量出模型预测能力的好坏。
损失函数大致可分为两类:分类问题的损失函数和回归问题的损失函数
二、交叉熵损失函数:
知识准备:
熵:表示一个系统的不确定程度,或者说一个系统的混乱程度
1、信息熵:将熵引入到信息论中,命名为“信息熵”

公式运用:
此处的信息熵克表示混乱程度亦或是不确定性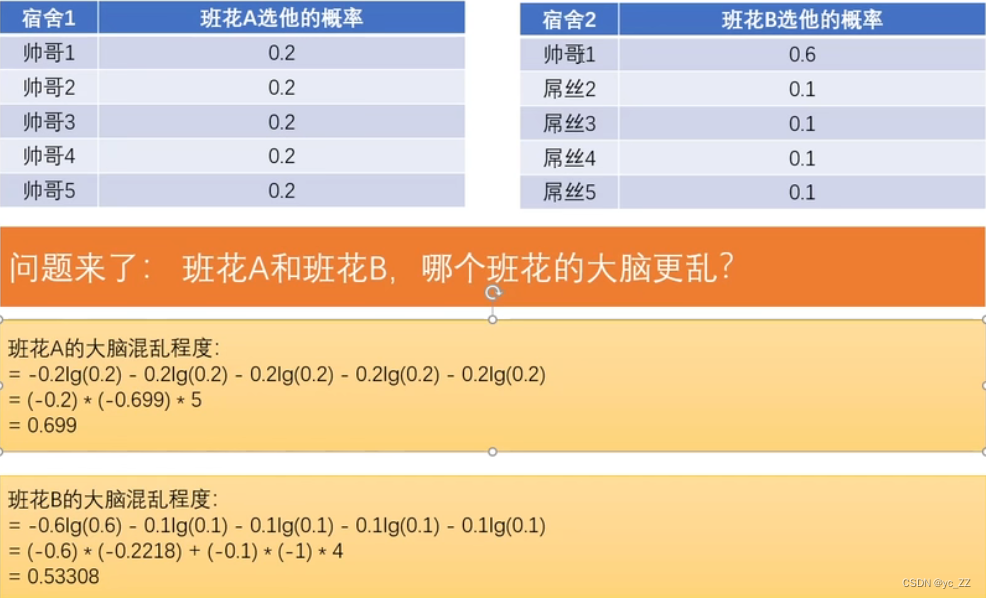

2、 KL散度(相对熵):
KL散度:是两个概率分布间差异的非对称性度量。
通俗说法是用来衡量同一个随机变量的两个不同分布之间的距离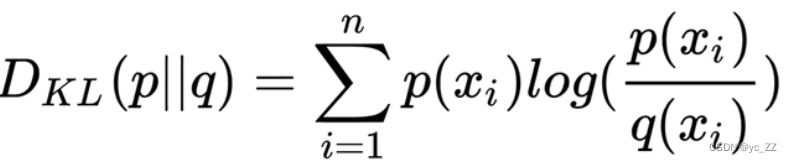

公式运用: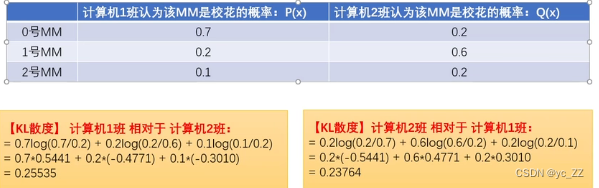
公式变形:

交叉熵:
交叉熵主要用于度量同一个随便变量X的预测分布Q与真实分布P之间的差距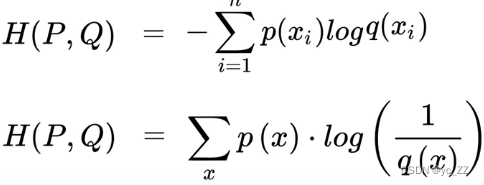
这里求得的交叉熵意味与真实标签的差距大小,越小越好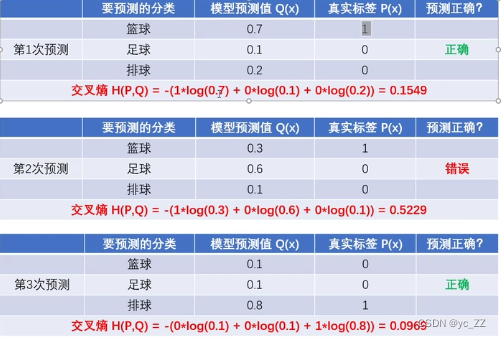
结论:

由图可知,如果不是真实标签,它的标签P(X)=0所以算的结果与之无关
1、预测越准确,交叉熵越小
2、交叉熵只跟真实标签的预测概率值有关
所以可以把交叉熵公式化简: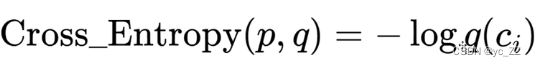
二分类交叉熵公式:
为什么要用交叉熵而不是用KL散度?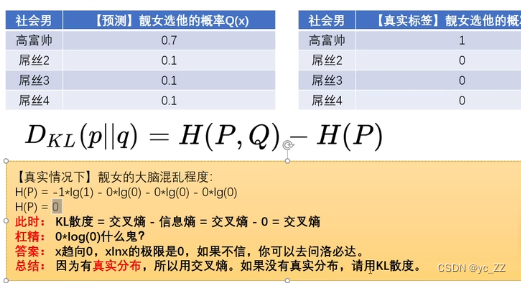
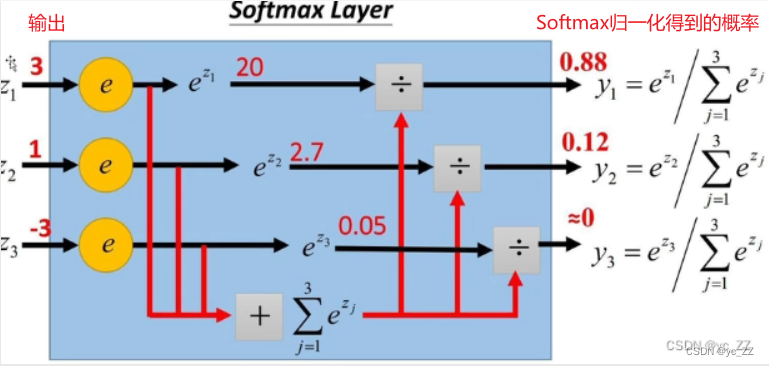
Softmax公式
1、将数字转化成概率
2、进行数据归一化的利器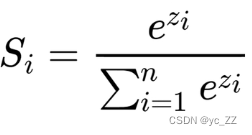
Sigmoid
1、Sigmoid函数也叫Logistic函数
2、取值范围是(0,1)
3、神经网路常用函数
4、常被用作二分类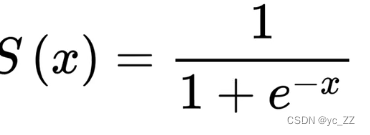
常见的交叉熵损失函数类型
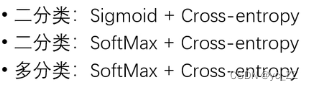
交叉熵损失函数:

具体过程:
本文转载自: https://blog.csdn.net/YCCNUST/article/details/125556283
版权归原作者 yc_ZZ 所有, 如有侵权,请联系我们删除。
版权归原作者 yc_ZZ 所有, 如有侵权,请联系我们删除。