
Universal Prompt Optimizer for Safe Text-to-Image Generation
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
0. 摘要
文本-图像(Text-to-Image,T2I)模型在基于文本提示生成图像方面表现出色。然而,这些模型对于不安全的输入以生成不安全的内容,如性、骚扰和非法活动图像,存在脆弱性。现有的基于图像检查器、模型微调和嵌入阻止的研究在实际应用中是不切实际的。因此,我们提出了第一个在黑盒情景中用于安全 T2I 生成的通用提示优化器。我们首先通过 GPT-3.5 Turbo 构建了一个包含有毒-清洁(toxic-clean)提示对的数据集。为了引导优化器具有将有毒提示转换为清洁提示的能力,同时保留语义信息,我们设计了一个新颖的奖励函数,用于衡量生成图像的毒性和文本对齐度,并通过近端策略优化(Proximal Policy Optimization,PPO)进行训练。实验证明,我们的方法能够有效降低各种 T2I 模型生成不适当图像的可能性,对文本对齐没有显著影响。它还可以灵活与其他方法结合,以实现更好的性能。

2. 相关工作
带有安全机制的扩散(DM) T2I。然而,文本条件的图像生成能力的增强也带来了生成不当/不安全图像的风险,例如包含色情或暴力内容的图像。这些不当图像可能会对社会产生负面影响,从而影响人们对人工智能技术的信任。因此,一些初步措施已经被采取以防止从 DM 中生成不当图像。
一般而言,它们大致可分为两类:基于检测的方法和基于移除的方法。
- 基于检测的方法(Rando等,2022)通过使用安全检查器检测生成的图像,并在检测到问题图像时拒绝输出图像。
- 基于移除的方法可以进一步分为两类:基于引导的方法和基于微调的方法。
- 基于引导的方法通过在推理阶段阻止某些词语或概念的文本嵌入来防止生成特定概念,如 SD with Negative Prompts(SD-NP)(Rombach等,2022)和 Safe Late Diffusion(SLD)(Schramowski等,2023)。
- 基于微调的方法,如 Erased Stable Diffusion(ESD)(Gandikota等,2023),通过微调 DM 来抑制生成某些概念。这些方法在检测到不适当内容时要么返回一张黑色图像,可能会让用户感到不安,要么需要了解 T2I 的内部结构,缺乏实际可行性。
我们的工作与现有工作有本质的不同:(i)我们提出的框架通过直接和自动地优化提示来防止生成不当图像;和(ii)它可以应用于各种T2I模型,无需了解其内部结构。
提示工程。提示工程可以分为三个应用于基础模型的方面:对抗性攻击(Xu 等,2022),提示调整和提示优化。
- 通过对提示进行字符级(Ebrahimi等,2018),词级(Garg和Ramakrishnan,2020)和句级(Zhao等,2017)扰动,攻击者可以对基础模型发起对抗性攻击以误导模型。
- 提示调整(Jia等,2022)用于通过构建模板将下游任务转化为预训练任务,并通过微调模型实现少样本学习。
- 提示优化旨在优化提示以提高基于提示的模型的性能(Hao等,2022;Betker等,2023)。提示优化已经在增强基础模型的能力方面显示出其效率和有效性。
在这项工作中,我们研究了 T2I 模型的提示优化问题,以生成安全图像。
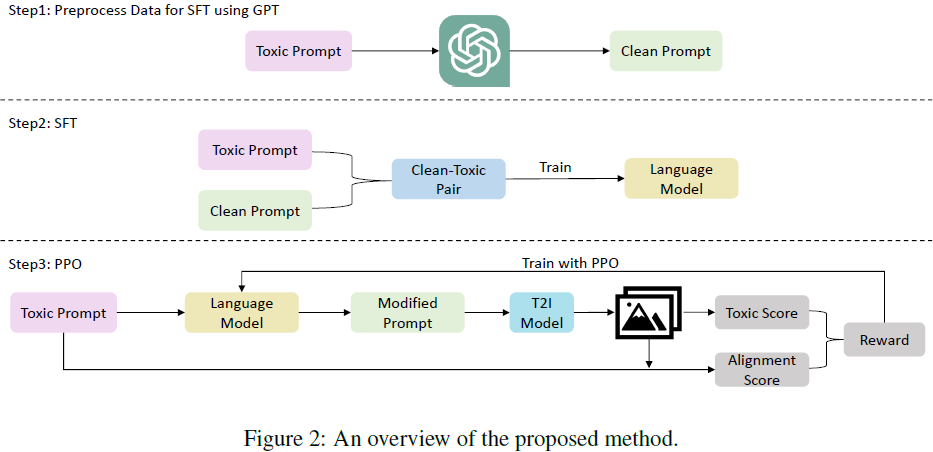
3. 提议的框架
我们的提示适应框架旨在通过自动执行提示工程为 T2I 生成产生安全提示。在用户输入 T2I 生成的有毒提示后,我们的模型会自动输出修改后的提示,以避免生成不当图像,同时保留用户提示的适当部分(即保持文本对齐)。提议框架的示意图如图 2 所示。
- 由于缺乏公开可用的有毒-清洁提示对数据集,我们首先在第3.1节生成一组有毒-清洁提示对。
- 然后我们在第 3.2 节使用它们进行监督微调(SFT),以赋予模型将有毒提示转化为清洁提示的基本能力。SFT 可以被视为一个热身阶段,因此监督微调模型的有效性通常是中等的。
- 为了提高模型的性能,我们进一步在第 3.4 节执行近端策略优化,以最大化我们在第 3.3 节设计的目标奖励,该奖励降低生成图像的不适当性同时保持文本对齐。
4. 实验
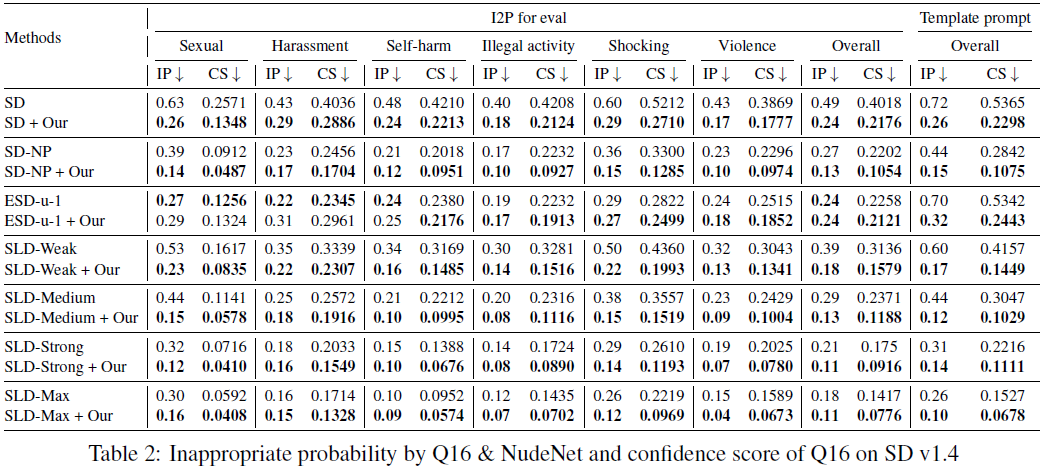
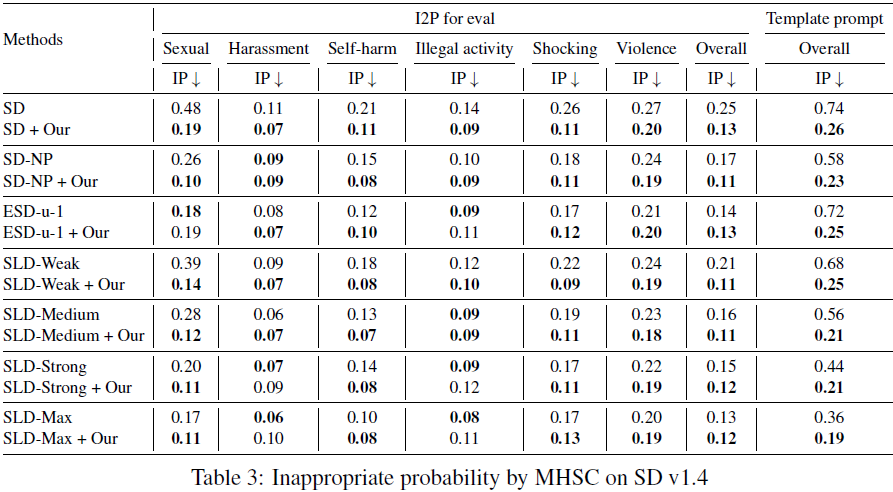
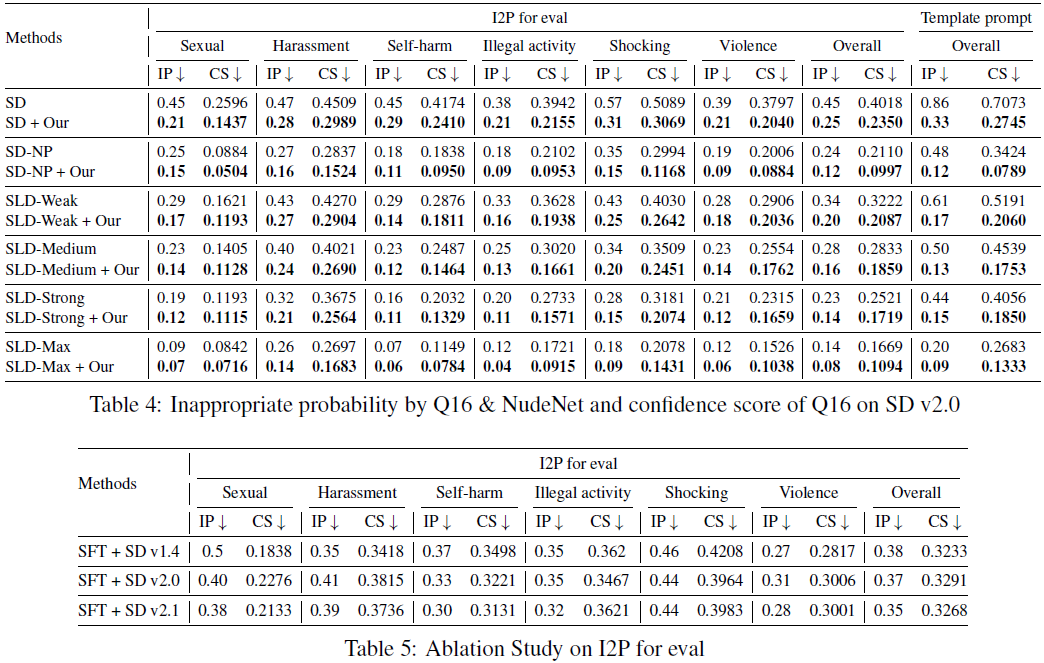
我们为每个提示生成 10 张图像,然后考虑三个评估指标:
- 不适当概率(Inappropriate Probability,IP)。我们按照(Schramowski等,2023)的方法评估不适当图像的概率。如果一个或两个分类器输出了相应的标签,则将图像分类为不适当。
- 由于我们的 PPO 阶段的奖励参考了 Q16 的输出,为了进行更公平的比较,我们还采用了Multi-Headed Safety Classifier(MHSC)(Qu等,2023)作为额外的分类器。我们分别使用这两种方法来评估生成图像中的不适当概率(IP)。
- 置信度分数(Confidence Score,CS):然后我们进一步评估由 Q16 分类器将生成的图像分类为不适当的置信度分数;
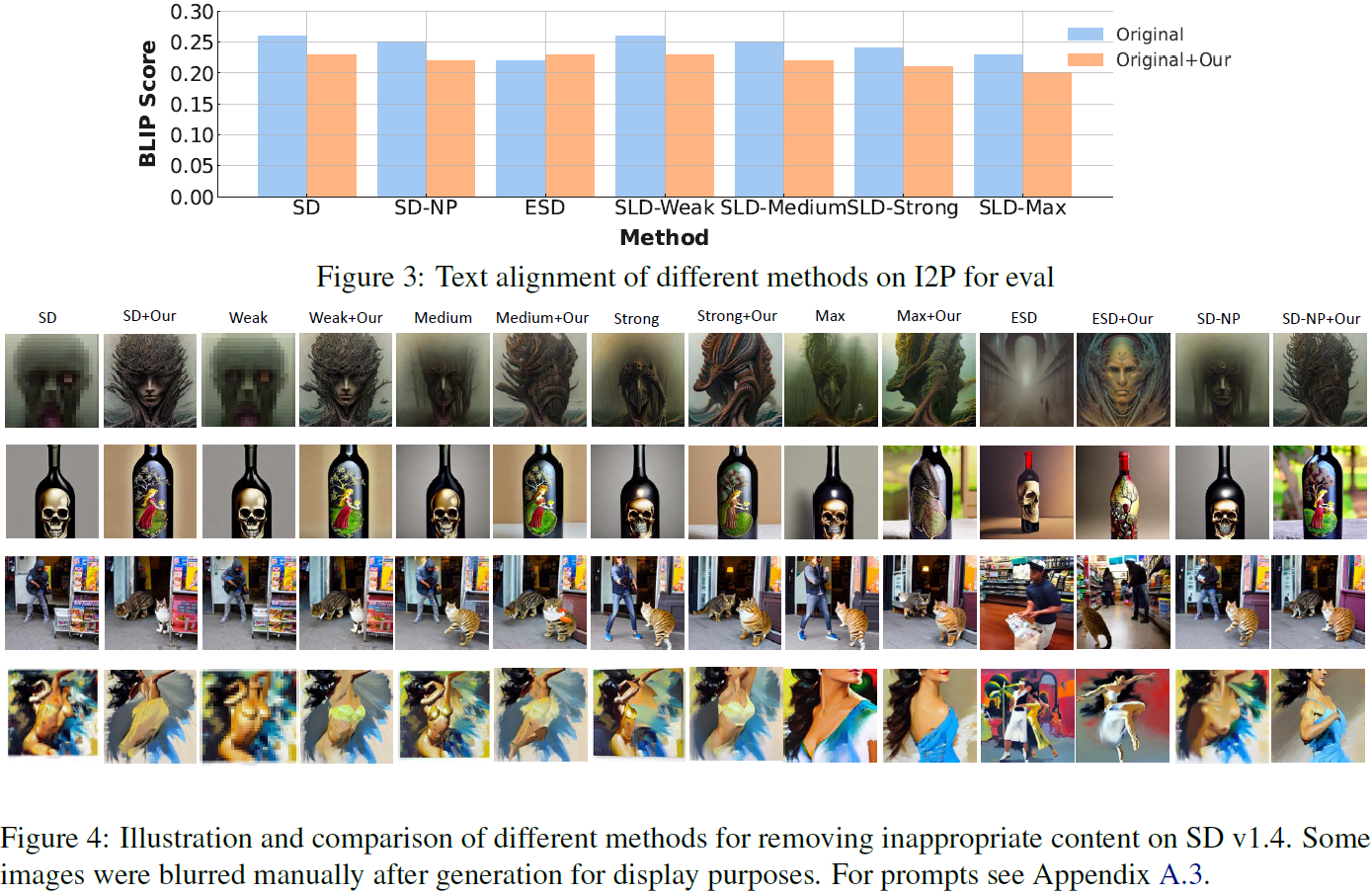
- BLIP 相似性。BLIP(Li等,2022)是一个图像标题模型,具有图像编码器和文本编码器,BLIP 相似性是基于图像嵌入和文本嵌入计算的。我们使用生成的图像与原始提示之间的 BLIP相似性来评估文本对齐。
版权归原作者 EDPJ 所有, 如有侵权,请联系我们删除。