
WGCNA简介
Weighted Gene Co-Expression Network Analysis,加权基因共表达网络,将复杂生物过程的基因共表达网络划分为高度相关的几个特征模块,其代表着机组高度协同变化的基因集,并可将模块与待定的临床特征建立关联,在研究表型性状与基因关联分析等方面的研究中被广泛应用。
两个假设
- 相似表达模式的基因可能存在共调控、功能相关或处于同一通路
- 基因网络符合无标度分布。无标度网络具有严重的异质性,其各节点之间的连接状况(度数)具有严重的不均匀分布性:网络中少数称之为Hub点的节点拥有极其多的连接,而大多数节点只有很少量的连接。少数Hub点对无标度网络的运行起着主导的作用。从广义上说,无标度网络的无标度性是描述大量复杂系统整体上严重不均匀分布的一种内在性质。
一般步骤
- 构建基因共表达网络:使用加权的表达相关性
- 识别基因集:基因加权相关性进行层次聚类分析,并根据设定标准切分聚类结果,获得不同基因模块,用聚类树的分枝和不同颜色表示
- 如果有表型信息,计算基因模块与表型的相关性,鉴定性状相关的模块
- 研究模块之间的关系,从系统层面查看不同模块的互作网络
- 从关键模块中选择感兴趣的驱动基因
数据准备
从GEO数据库中下载乳腺癌相关数据集,以基因表达量数据GSE1456和临床数据GPL96-57554为例进行数据分析。
setwd("F:/exp_clinical") #设置工作路径
#读入数据
ids <- read.csv("GSE1456_label.csv") #这个文件存放基因ID和基因名称
data <- read.csv("GSE1456_expr.csv") #基因表达量数据
rownames(data) <- data[,1] #用基因ID更改数据行名
data <- data[,-1]
#去掉空的GENE_SYMBOL
ids <- ids[ids$Gene.symbol != '',]
table(ids$ID %in% rownames(data))
data <- data[rownames(data) %in% ids$ID,]
data <- data[match(rownames(data),ids$ID),]
identical(rownames(data),ids$ID)
#去重复基因,保留最大表达量的结果
table(!duplicated(ids$Gene.symbol))
ids$median <- apply(data,1,median) #取每一行的中位数
ids <- ids[order(ids$Gene.symbol,ids$median,decreasing = T),] #对中位数从大到小排序
ids <- ids[!duplicated(ids$Gene.symbol),] #去除重复的gene ,保留每个基因最大表达量结果
#最终表达矩阵,改换为基因名为行名
data <- data[ids$ID,]
identical(rownames(data),ids$ID)
rownames(data) <- ids$Gene.symbol
boxplot(data) #绘制箱线图
预处理后,数据由22282个基因变为13299个基因,有147个样本。下面为147个样本的箱线图。

接下来需要读入临床数据,将上述基因表达数据分组,进行差异分析。对于临床特征,我选择的是乳腺癌ELSTON分级,把它分为low和high两组,以便后续差异分析。其中ELSTON=1指低级别的组织学分级(预后较好),ELSTON=2/3分别指中/高级别的组织学分级,预后较差。三个等级是按照肿瘤的形态学特征(小叶的形成、核的多样性、有丝分裂数)得分总数值按照35、67、8~9分类。
#临床分组
data_clin <- read.csv("GSE1456_clinical.csv",header = T) #读取ELSTON分级数据
rownames(data_clin) <- data_clin$X
group_list=ifelse(grepl('ELSTON: 1',data_clin$characteristics_ch1.7),'low','high')
table(group_list)
save(data,group_list,file = 'Prexp.Rdata') #保存数据
差异分析
差异分析就是分析两组数据是否有差异。比如,使用简体中文的人是否显著多于使用繁体字的人?这就涉及到“显著”的定义了。何为显著?多100人为显著,还多1,000人才为显著?所以要用统计学来分析。通常的做法是对两组数据的差异倍数进行统计学检验,得到的P value达到某个阈值,则为显著差异。在转录组的基因差异表达分析中,一般的筛选标准是基因表达差异倍数大于2、并且FDR≤0.05为显著差异的基因。这个标准也可以根据实际数据调整。
参数解释
- FC即差异倍数(fold change),也叫作radio,简单来说就是基因在一组样品中的表达值的均值除以其在另一组样品中的表达值的均值。如果规定|FC|>2为上调,那么|FC|<2为下调。
- P-value:统计检验获得的是否统计差异显著的一个衡量值,约定成俗的P-value<0.05为统计检验显著的常规标准。
- FDR(Fasle Discovery Rate):即校正后的P值,中文一般译作错误发现率。
Limma包差异分析
logFC即log2转化后的Fold Change值,表示两样品间表达量的比值。这里取|Log2FC|>0.3分析,筛出257个上调基因,332个下调基因。
library(limma) #加载limma包做差异分析
library(ggplot2) #加载画图包
#差异分析
load('Prexp.Rdata') #导入已准备好的数据
design <- model.matrix(~factor( group_list ))
fit <- lmFit(data,design)
fit <- eBayes(fit)
options(digits = 4) #设置全局的数字有效位数为4
deg <- topTable(fit,coef=2,adjust='BH', n=Inf)
#设定上下调基因阈值,这里根据自己的需要更改logFC的值;
deg$g <- ifelse(deg$P.Value>0.05,'stable',
ifelse(deg$logFC >0.3,'up',
ifelse( deg$logFC < -0.3,'down','stable')))
table(deg$g) #统计上下调基因数量
#画火山图
p <- ggplot(
# 数据、映射、颜色
deg, aes(x = logFC, y = -log10(P.Value), colour=g)) +
geom_point(alpha=0.4, size=3.5) +
scale_color_manual(values=c("#c8e09f","#bdbdbf", "#ec5141"))+
# 辅助线
geom_vline(xintercept=c(-0.3,0.3),lty=4,col="black",lwd=0.8) +
geom_hline(yintercept = -log10(0.05),lty=4,col="black",lwd=0.8) +
# 坐标轴
labs(x="log2(fold change)",
y="-log10 (p-value)")+
ggtitle("GSE1456")+
theme_bw()+
# 图例
theme(plot.title = element_text(hjust = 0.5),
legend.position="right",
legend.title = element_blank())
p

WGCNA分析
构建基因共表达网络
#数据过滤
rm(list = ls())
options(stringsAsFactors = F)
load('Prexp.Rdata')
#提取25% of the maximum variationin基因
data <- as.data.frame(t(data))
m.vars <- apply(data,2,var)
expro.upper <- data[,which(m.vars>quantile(m.vars,probs = seq(0,1,0.25))[4])]
data <- as.data.frame(t(expro.upper))
dim(data)
#3325 147
#构建基因共表达网络
library(WGCNA)
#1.判断数据质量
gsg <- goodSamplesGenes(data, verbose = 3)
gsg$allOK #这个数据结果是TRUE
#2.设置间隔
powers <- c(c(1:10), seq(from = 12, to=30, by=2))
dat <- as.data.frame(t(data)) #注意倒置;
sft <- pickSoftThreshold(dat, powerVector = powers, verbose = 5)
#3.画βvalue图,确定阈值
#png("beta-value.png",width = 800,height = 600)
par(mfrow = c(1,2))
cex1 <- 0.95
plot(sft$fitIndices[,1], -sign(sft$fitIndices[,3])*sft$fitIndices[,2],
xlab="Soft Threshold (power)",ylab="Scale Free Topology Model Fit,signed R^2",type="n",main = paste("Scale independence"))
text(sft$fitIndices[,1], -sign(sft$fitIndices[,3])*sft$fitIndices[,2],
labels=powers,cex=cex1,col="red")
abline(h=0.95,col="red")
plot(sft$fitIndices[,1], sft$fitIndices[,5],xlab="Soft Threshold (power)",ylab="Mean Connectivity", type="n",main = paste("Mean connectivity"))
text(sft$fitIndices[,1], sft$fitIndices[,5], labels=powers, cex=cex1,col="red")
dev.off()

对于WGCNA,加权是指对相关性值进行幂次计算(幂次的值就是软阈值),使用软阈值强化了强相关,弱化了弱相关或负相关,使得相关性数值更具有生物学意义。上图中,左图为无标度拓扑拟合指数,这里红线表示R^2=0.95,可以选择软阈值为6;右图为平均连接度。
#4.构建共表达网络
#设置一下power和maxBlockSize两个数值,power就是上面得到的R^2达到0.9的数值6;
net <- blockwiseModules(dat, power = 6, maxBlockSize = 3325,
TOMType ='unsigned', minModuleSize = 100, #minModuleSize这个参数需要自己设置模块最小基因数
reassignThreshold = 0, mergeCutHeight = 0.25,
numericLabels = TRUE, pamRespectsDendro = FALSE,
saveTOMs=TRUE, saveTOMFileBase = "drought",
verbose = 3)
table(net$colors)
# 0 1 2 3 4
#2582 190 188 184 181
#5.绘制基因聚类和模块颜色组合
moduleLabels <- net$colors
moduleColors <- labels2colors(moduleLabels)
#png("genes-modules.png",width = 800,height = 600)
plotDendroAndColors(net$dendrograms[[1]], moduleColors[net$blockGenes[[1]]],
"Module colors",
dendroLabels = FALSE, hang = 0.03,
addGuide = TRUE, guideHang = 0.05)
dev.off()
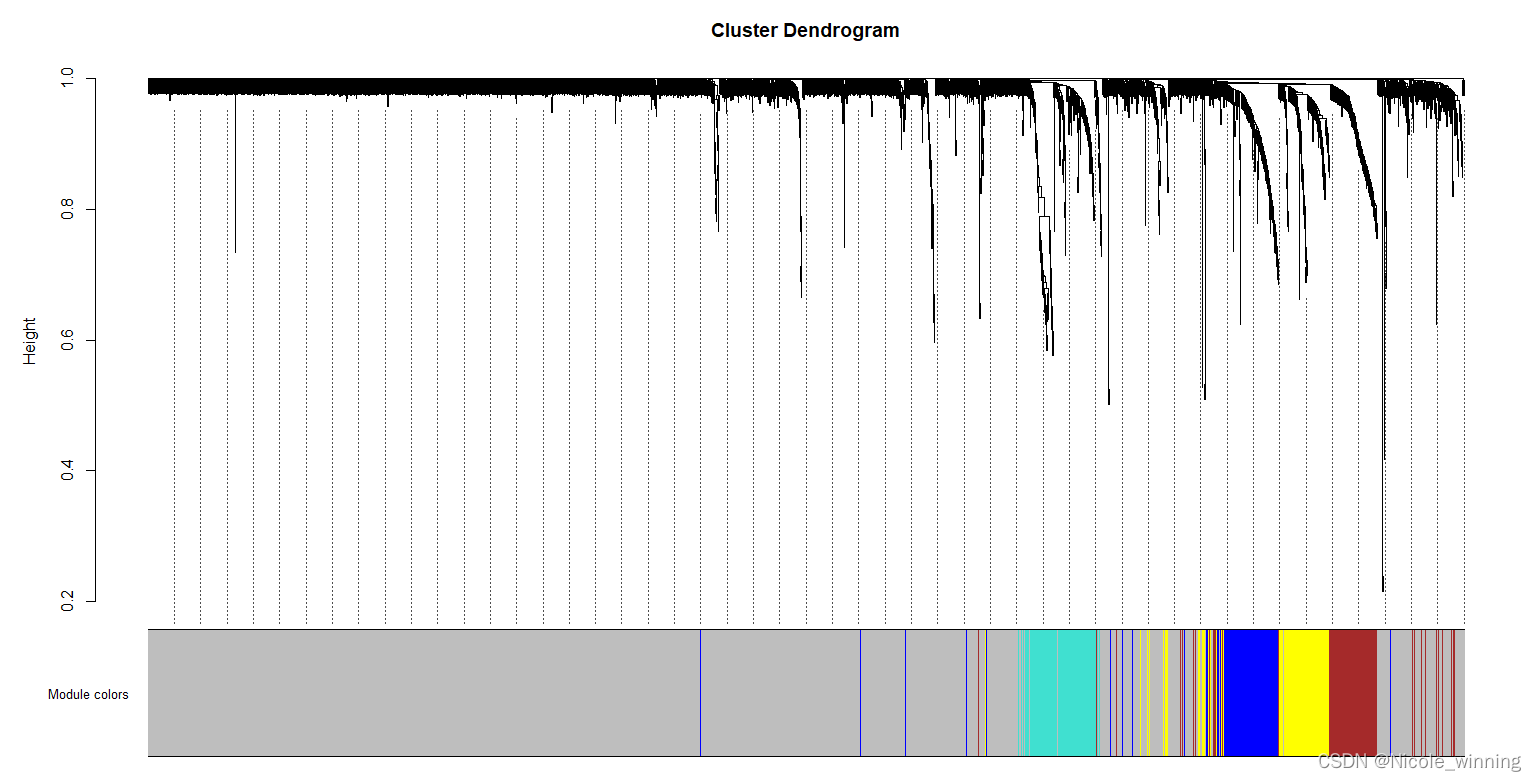
基因模块的构建源头还是根据表达模式的聚类,会根据TOM(Topological overlapmatrix)值进一步构建层次聚类树。同时进行模块划分,如上图中每个分支代表一个模块,从而根据不同的表达模式将大量的基因归纳为较少量的模块中,从而对信息进行简化归纳。
模块与临床特征的相关性分析
#1.导入临床信息
data_clin <- read.csv('GSE1456_clinical.csv',header = T)
rownames(data_clin) <- data_clin$X
data_clin$low <- ifelse(grepl('ELSTON: 1',data_clin$characteristics_ch1.7),1,0)
data_clin$high <- ifelse(grepl('0',data_clin$low),1,0)
data_clin <- data_clin[,-1:-2]
#2.模块与性状相关性
nGenes <- ncol(dat)
nSamples <- nrow(dat)
MEs0 <- moduleEigengenes(dat, moduleColors)$eigengenes #获取eigengenes,用颜色标签计算ME值
MEs <- orderMEs(MEs0) #不同颜色的模块的ME值矩 (样本vs模块)
moduleTraitCor <- cor(MEs, data_clin , use = "p") #计算每个模块和每个性状之间的相关性
moduleTraitPvalue <- corPvalueStudent(moduleTraitCor, nSamples)
# 可视化相关性和P值
textMatrix <- paste(signif(moduleTraitCor, 2), "\n(",
signif(moduleTraitPvalue, 1), ")", sep = "");
dim(textMatrix) <- dim(moduleTraitCor)
#png("Module-trait-relationships.jpg",width = 800,height = 1200,res = 120)
par(mar = c(6, 8.5, 3, 3))
labeledHeatmap(Matrix = moduleTraitCor,
xLabels = colnames(data_clin),
yLabels = names(MEs),
ySymbols = names(MEs),
colorLabels = FALSE,
colors = greenWhiteRed(50),
textMatrix = textMatrix,
setStdMargins = FALSE,
cex.text = 0.5,
zlim = c(-1,1),
main = paste("Module-trait relationships"))
dev.off()

可以看到ELSTON表型与MEbrown的相关系数最大且P值很显著,接着提取MEbrown模块中的所有基因或Hub基因进行后续分析。
#3.对模块里的具体基因分析
#跟ELSTON最相关的是Brown模块
nSamples <- nrow(dat)
#计算MM值和GS值
modNames <- substring(names(MEs), 3) ##切割,从第三个字符开始保存
geneModuleMembership <- as.data.frame(cor(dat, MEs, use = "p")) #算出每个模块跟基因的Pearson相关系数矩阵
MMPvalue <- as.data.frame(corPvalueStudent(as.matrix(geneModuleMembership), nSamples)) #计算MM值对应的P值
names(geneModuleMembership) <- paste("MM", modNames, sep="")
names(MMPvalue) <- paste("p.MM", modNames, sep="")
geneTraitSignificance <- as.data.frame(cor(dat, data_clin, use = "p")) #计算基因与每个性状的显著性(相关性)及pvalue值
GSPvalue <- as.data.frame(corPvalueStudent(as.matrix(geneTraitSignificance), nSamples))
names(geneTraitSignificance) <- paste("GS.", colnames(data_clin), sep="")
names(GSPvalue) <- paste("p.GS.", colnames(data_clin), sep="")
#3.1 分析Brown模块
module <- "brown"
column <- match(module, modNames) ##在所有模块中匹配选择的模块,返回所在的位置
brown_moduleGenes <- names(net$colors)[which(moduleColors == module)]
MM <- abs(geneModuleMembership[brown_moduleGenes, column])
GS <- abs(geneTraitSignificance[brown_moduleGenes, 1])
#画图
png("Module_brown_membership_gene_significance.png",width = 800,height = 600)
par(mfrow = c(1,1))
verboseScatterplot(MM, GS,
xlab = paste("Module Membership in", module, "module"),
ylab = "Gene significance for Basal",
main = paste("Module membership vs. gene significance\n"),
cex.main = 1.2, cex.lab = 1.2, cex.axis = 1.2, col = module)
dev.off()
#提取HUB基因:MM > 0.8,GS > 0.2
brown_hub <- brown_moduleGenes[(GS > 0.2 & MM > 0.8)]
length(brown_hub)
#[1] 31
write.csv(brown_hub,'brown_hub_gene.csv') #保存至表格,后面做富集分析需要

通过散点图可以发现MM和GS呈正相关,说明与ELSTON分级高度相关的基因,在Brown模块中也很重要。GS(Gene Significance):基因和表型性状的相关性的绝对值,MM(Module Membership):模块的eigengene与基因表达谱之间的相关性,提取Hub基因,通过设置GS和MM值来提取,一般使用较多的方式是根据 |ME| > 0.8 且 |GS| > 0.2的阈值进行筛选hub基因,也可以根据数据表现自行更改阈值。
GO富集分析
library(clusterProfiler)
library(org.Hs.eg.db)
rm(list = ls())
options(stringsAsFactors = F)
brown_hub_gene <- read.csv('brown_hub_gene.csv',header = F)
brown_hub_gene <- brown_hub_gene[-1,]
brown_hub_gene <- brown_hub_gene[,-1]
gene=unique(brown_hub_gene)
##基因转ID
sig_DP_entrezId <- mapIds(x = org.Hs.eg.db,
keys = gene,
keytype = "SYMBOL",
column = "ENTREZID")
table(is.na(sig_DP_entrezId))
sig_DP_entrezId <- na.omit(sig_DP_entrezId)
go_bp <- enrichGO(gene = sig_DP_entrezId,
OrgDb = org.Hs.eg.db,
keyType = "ENTREZID",
ont = "BP",
pvalueCutoff = 0.5,
qvalueCutoff = 0.5,
readable = TRUE)
#画图
barplot(go_bp)
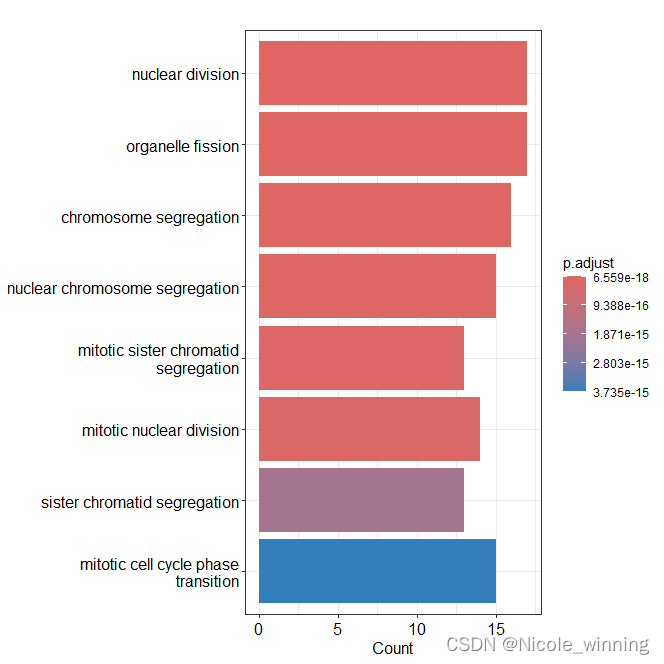
由富集结果可以看到,Brown模块富集到几个BP途径,包括:核分裂和染色体分离等。
KEGG富集分析
这里我使用的是DAVID数据库进行分析,网址在DAVID Functional Annotation Bioinformatics Microarray Analysis
具体操作可以参考下图公众号:

library(ggplot2)
rm(list = ls())
options(stringsAsFactors = F)
data <- read.csv("KG.csv")
data$GeneRatio <- data$Count / data$List.Total
data <- data[order(-data$PValue),]
data$pathway <- factor(data$Term,levels=data$Term)
#画图
p <- ggplot(data,aes(GeneRatio,pathway))
p <- p + geom_point()+theme(axis.text.x = element_text(colour="black",size=1))
p <- p + geom_point(aes(size=Count))
pbubble <- p+ geom_point(aes(color=PValue,size=Count))
pr <- pbubble+scale_color_gradient(low="red",high = "green")
pr <- pr+labs(color=expression(PValue),size="Count",
x="GeneRatio",y="")
pr + theme_bw()

上图为KEGG富集后的结果,可以看到这些Hub基因影响细胞周期、细胞衰老等通路。
PPI分析
使用上述DEGs与Hub genes的交集(这里DEGs包含31个Hub gens),先使用STRING网站做PPI分析,然后使用Cytoscape找关键基因。STRING网站网址:STRING: functional protein association networks
网站简单易上手,还没有使用过的可自行百度查教程。分析完毕后下载Cytoscape格式文件(如箭头所示),导入Cytoscape继续分析。


接着使用CytoHubba包中的MCC算法来得到排名前10名的Hub基因(MCC(Maximal Clique Centrality):该算法识别网络中的最大团,即具有最大相连节点数的子图。某节点在最大团中的数量越多,越重要。):

验证关键基因
使用GEPIA网站做上述Hub genes的表达和生存分析曲线,网站在:GEPIA
对上述31个MEbrown模块找到的前10名基因做生存分析,发现预后都没有显著性,P-value最小0.061,为CDK1基因,但是其在ELSTON较低和较高的组织中是显著差异表达的。


考虑到筛选出的Hubs比较少,我直接利用上面得到的589个DEGs进行PPI分析和Cytoscape寻找关键基因,在筛出的前15名基因中,UBE2C基因对乳腺癌预后有显著影响,也许可以进一步验证,比如RT-qPCR和WB实验等,看这个基因是否在基因表达水平和蛋白表达水平上存在差异。


写在最后
本文通过差异分析、WGCNA分析、功能富集分析、PPI网络分析以及生存分析,期望找到乳腺癌(BRCA)的靶基因,进而研究靶基因影响的生物学通路或代谢网络等。类似生信发文也比较多,工作量较小,也比较容易,不过也可以设计一些创新点或者生物学实验来验证,对其做更多的生物学解释。大家感兴趣的可以跑一遍流程试试,需要数据的可以关注“壹点究通”公众号,私信我获取噢~ 在处理过程中有问题,欢迎私信交流~
版权归原作者 Nicole_winning 所有, 如有侵权,请联系我们删除。