
介绍
机器学习的神奇之处在于,我们对原理的概念和思路理解得越多,它就变得越容易。在本文中,我们将研究在图像分类和图像推荐中使用定向梯度直方图的方法。
数据集

来源:Kaggle Fashion图像分类数据集(Small)
https://www.kaggle.com/paramaggarwal/fashion-product-images-small
数据集有主类别、子类别、性别、季节和每个图像的标签。目的是将数据集用于图像分类和推荐。让我们先看看数据分布!

每个列的惟一值。对于每个性别,masterCategory、subCategory、gender、usage和season列使用KNN分类器进行图像分类,然后使用K个最近邻数据进行图像推荐
这个设计的目标是提出一个解决方案,将所有的类别分为不同的类(类是在下面的图表中提到的分布)。然后构建推荐引擎,根据用户选择的测试图像,给出最匹配的n幅图像。
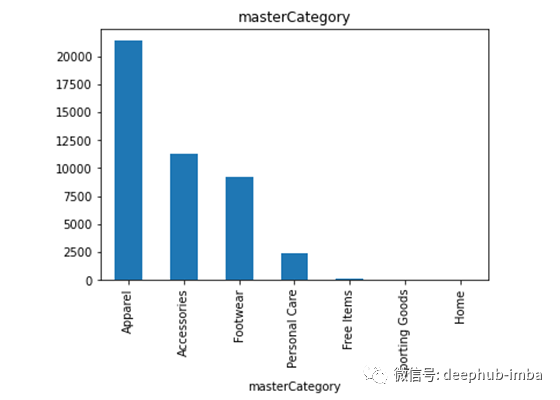
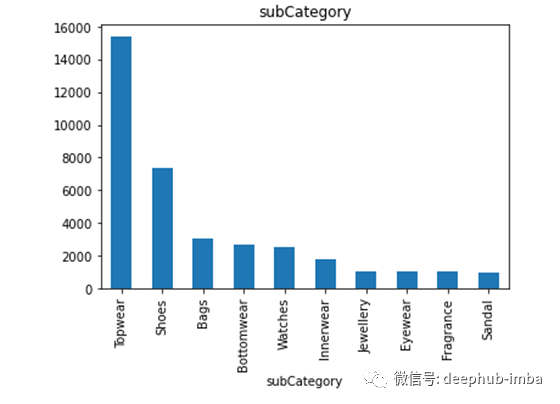
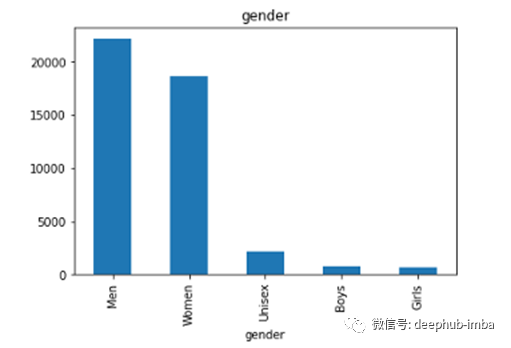
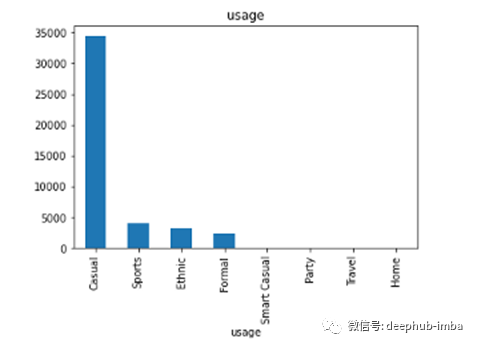
每列下不同类的数据(只显示前10个)
分类和推荐是建立在一种局部特征提取和描述方法上的,即定向梯度直方图(Histogram of Oriented Gradients, HOG)。使用不同的特征检测器(例如:SIFT, Shi-Thomas, ORB, FAST等),我们可以定位特征,并在多幅图像之间匹配提取的特征。但是为了使用这些信息来训练一个模型,我们需要提取一维向量形式的特征(如[x1,x2,..,xn])。HOG(“Histogram of Oriented Gradients for Human Detection\”——Dalal & Triggs, 2005)的想法就是基于同样的原理。下面让我们看看HOG是如何工作的,以及如何在Python中配置它。
注意:HOG最初是由Dalal & Triggs(2005)发明的,他们使用特定的参数来获得最佳的人体检测性能。但是,这些参数不是通用的,并且根据图像类型的不同而变化。
计算HOG的步骤:
HOG是一种将图像转换为梯度直方图,然后使用直方图制作用于训练模型的一维矩阵的技术。
在我们计算之前,让我们先导入相关库!
importos
importnumpyasnp
importpandasaspd
importcv2ascv
frompathlibimportPath
importwarnings
fromskimage.featureimporthog
importtqdm
fromsklearn.neighborsimportKNeighborsClassifier
fromsklearnimportmetrics
fromsklearn.model_selectionimporttrain_test_split
fromsklearn.preprocessingimportMinMaxScaler
fromsklearn.neighborsimportNearestNeighborswarnings.filterwarnings("ignore")
pd.options.display.max_columns = None
然后读取图片
all_images = []
#labels = []def load_image(ids,path=image_folder):
img = cv.imread(image_folder+ids+'.jpg',cv.IMREAD_GRAYSCALE) #load at gray scale
#img = cv.cvtColor(img, cv.COLOR_BGR2GRAY) #convert to gray scale
returnimg,ids#20k samples were taken for modeling
foridsintqdm(list(styles.id)[:20000]):
img,ids = load_image(str(ids))
ifimgisnotNone:
all_images.append([img,int(ids)])
#labels.append(ids)
len(all_images)
现在让我们考虑下面的图像,

让我们假设红色的方框用8x8矩阵表示,每个单元格中都有数字。在进行图像特征工程之前,建议做以下几件事:
- Resize:将所有图像调整为统一形状,以避免任何与计算相关的隐患。在本例中,所有图像的形状统一(60x80)。如果您想执行调整大小操作,请参阅以下内容:
defresize_image(img,ids):
returncv.resize(img, (60, 80),interpolation =cv.INTER_LINEAR)
all_images_resized = [[resize_image(x,y),y] forx,yinall_images]
len(all_images_resized)
- Normalize :以避免亮度、对比度或其他照明效果造成的影响。
- Filtering:考虑几个相邻像素,而不是单一像素值作为像素的真实值。高斯滤波对中心像素权重最大,对相邻像素权重按w、r、t递减,即根据窗口大小确定与中心像素的距离。
最后对滤波后的图像进行如下计算:

将整个图像分成若干块(b)。一个典型的块是上面提到的红框。此外,其他块可以看作是黑盒中提到的单元格(c)的集合。上图中,b的尺寸是8x8, c的尺寸是4x4
接下来,对于每个单元格,计算单元格中每个点的梯度大小和方向(为了简单起见,梯度大小可以简单地假设为Sobel导数或任意两个连续的x和y像素值之间的差)。然后形成大小为n的直方图,将梯度量级值从w.r.t梯度方向进行处理。最后根据规则对直方图进行归一化,形成一个n维向量。
对于一个单元格,我们得到一个n维向量。接下来的操作是通过向右移动50%重叠的图像块和向下移50%重叠的图像块来覆盖整个图像。
最后,将所有这些直方图串联起来,形成一个一维向量,称为HOG特征描述符。
HOG可以通过下面的代码段进行实现。
##HOG Descriptor#Returns a 1D vector for an image
ppcr = 8
ppcc = 8
hog_images = []
hog_features = []
forimageintqdm(train_images):
blur = cv.GaussianBlur(image,(5,5),0) #Gaussian Filtering
fd,hog_image = hog(blur, orientations=8, pixels_per_cell=(ppcr,ppcc),cells_per_block=(2,2),block_norm= ‘L2’,visualize=True)
hog_images.append(hog_image)
hog_features.append(fd)
hog_features = np.array(hog_features)
hog_features.shape
参数
对这个问题:-块大小为16x16
-单元格大小为8x8
这使得pixel_per_cell = (8x8)并且cells_per_block = (2x2)
-orientations(=8)是每个单元格的直方图容器的数量。在这8个容器中将放置16个梯度值,并将它们添加到每个容器中以表示该方向容器的梯度大小。当两个连续箱子之间的梯度分配发生冲突时,通常通过梯度插值来对梯度值进行投票。
-block_norm =“L1”。其他参数有L1归一化或L2-Hys(Hysteresis)。L2-Hys在某些情况下可以减少噪音。它使用l2 -范数来完成,然后将最大值限制为0.2,并使用l2 -范数来重新归一化。
#normalization by 'L2-Hys'
out = block/np.sqrt(np.sum(block**2) +eps**2)
out = np.minimum(out, 0.2)
out = out/np.sqrt(np.sum(out**2) +eps**2)
当实际图像形状为60x80,块大小为16x16时,总共将创建6x9 = 54个块(考虑到x,y中任意一步50%的重叠),而在每个块中我们将有4个单元格,每个单元格有8个直方图。因此,特征向量的长度为54x4x8 = 1728
下面是一些HOG图像的可视化表示:
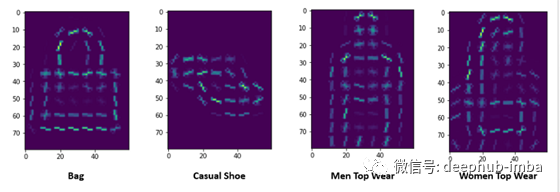
在建模中使用梯度方向的想法是因为这种方法人类神经系统的工作方式相似。当人类看到某一物体时,大脑皮层会引起人们的注意,或者人类为了看得更清楚而改变观察的角度
由于是多分类问题,而且类内分布也不均匀,建议采用分层抽样。
X_train, X_test, y_train, y_test = train_test_split(hog_features,df_labels['class'],test_size=0.2,stratify=df_labels['class'])print('Training data and target sizes: \n{}, {}'.format(X_train.shape,y_train.shape))print('Test data and target sizes: \n{}, {}'.format(X_test.shape,y_test.shape))
============================================= Trainingdataandtargetsizes:
(15998, 1728), (15998,)
Testdataandtargetsizes:
(4000, 1728), (4000,)
最后,将数据使用分类器处理。针对该问题,分别采用了支持向量机、随机森林和KNN算法。在所有最近邻查找算法(ball_tree、kd_tree和brute force)中,KNN的表现都优于其他分类器。最后,使用“贪婪”搜索,因为它的计算速度比ball_tree和kd_tree快得多。
KNN分类器的代码片段
test_accuracy = []
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_train)classifier = KNeighborsClassifier(n_neighbors=3,algorithm='brute')
classifier.fit(X_scaled, y_train)
test_accuracy = classifier.score(scaler.transform(X_test), y_test)
print(test_accuracy)
在masterCategory中,主要包括以下五个类别:[“服饰”、“配饰”、“鞋履”、“个人护理”、“免费物品”]。所有属于其他类别的记录被命名为“其他”。
通过更改Jupyter笔记本中的列名,可以对任何列类型进行分类。
下面是一些有助于评估模型性能的数字。
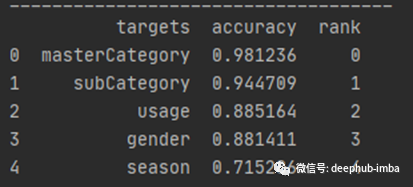
list_of_categories = categories+['Others']print("Classification Report: \n Target: %s \n Labels: %s \n Classifier: %s:\n%s\n"
% (target,list_of_categories,classifier, metrics.classification_report(y_test, y_pred)))df_report = pd.DataFrame(metrics.confusion_matrix(y_test, y_pred),columns = list_of_categories )
df_report.index = [list_of_categories]
df_report

最后,让我们对测试图像进行推断
#test image with id
test_data_location = root+'/test/'img = cv.imread(test_data_location+'1570.jpg',cv.IMREAD_GRAYSCALE) #load at gray scale
image = cv.resize(img, (60, 80),interpolation =cv.INTER_LINEAR)ppcr = 8
ppcc = 8
hog_images_test = []
hog_features_test = []blur = cv.GaussianBlur(image,(5,5),0)
fd_test,hog_img = hog(blur, orientations=8, pixels_per_cell=(ppcr,ppcc),cells_per_block=(2,2),block_norm= 'L2',visualize=True)
hog_images_test.append(hog_img)
hog_features_test.append(fd)hog_features_test = np.array(hog_features_test)
y_pred_user = classifier.predict(scaler.transform(hog_features_test))
#print(plt.imshow(hog_images_test))
print(y_pred_user)
print("Predicted MaterCategory: ", mapper[mapper['class']==int(y_pred_user)]['masterCategory'])
一些建议!
scaler_global = MinMaxScaler()
final_features_scaled = scaler_global.fit_transform(hog_features)
neighbors = NearestNeighbors(n_neighbors=20, algorithm='brute')
neighbors.fit(final_features_scaled)distance,potential = neighbors.kneighbors(scaler_global.transform(hog_features_test))
print("Potential Neighbors Found!")
neighbors = []
foriinpotential[0]:
neighbors.append(i)recommendation_list = list(df_labels.iloc[neighbors]['id'])
recommendation_list
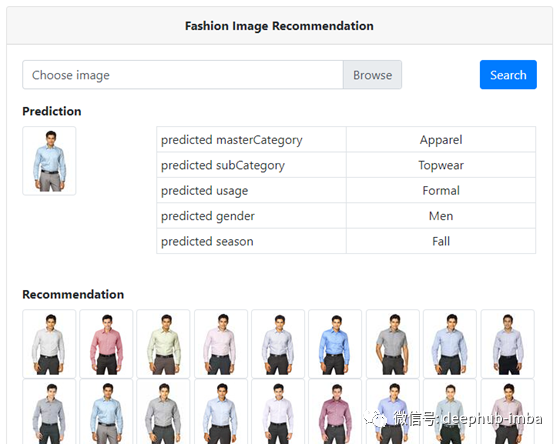
使用Flask分类值和推荐图像构建了一个简单的webservice (UI的开发不在本文讨论范围之内)。webservice看起来如下所示:
结论
本文首先说明了HOG背后的原理是什么,以及我们如何使用它来描述图像的特征。接下来,计算HOG特征并将其用于KNN分类器中,然后寻找K个最近邻点。这两个案例都在不使用任何深度学习方法的情况下达到了较高的准确率。在一些情况下,图像被错误地标记,或者图像有多个对象但被标记在一个类中,这会影响我们的模型。下一步是确定错误分类的根本原因,并制作一个更好的分类和推荐引擎。
作者:Anirban Malick
本文代码:https://github.com/anirbanmalick/ComputerVision/tree/kaggle_classification
deephub翻译组:孟翔杰