
活动地址:CSDN21天学习挑战赛
Numpy数据存取与函数
1.数据存取与函数
1.1.数据的CSV文件存取
CSV(Comma-Separated Value,逗号分隔值)
CSV是一种常见的文件格式,用来存储批量数据
np.savetxt(frame, array, fmt=‘%.18e’, delimiter=None)
- frame : 文件、字符串或产生器,可以是.gz或.bz2的压缩文件
- array : 存入文件的数组
- fmt : 写入文件的格式,例如:%d %.2f %.18e
- delimiter : 分割字符串,默认是任何空格

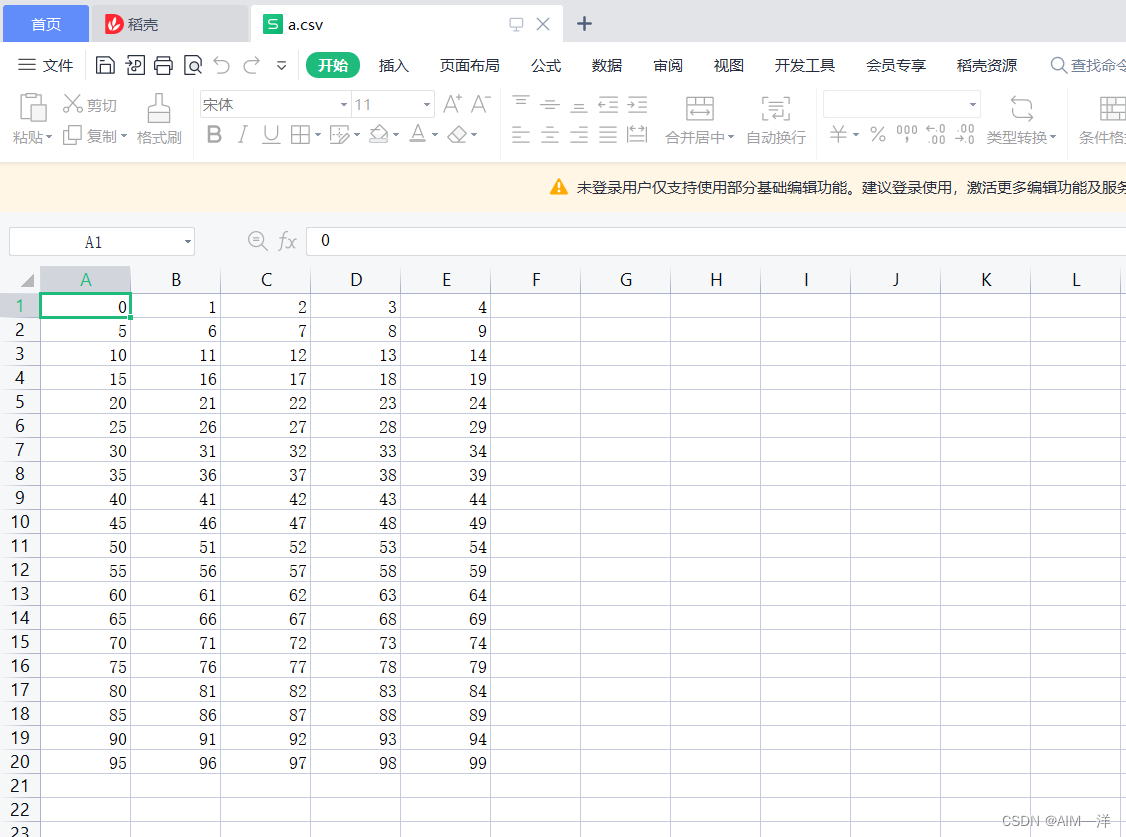
a=np.arange(100).reshape(20,5)
np.savetxt('C:/Users/12079/Desktop/python/CSV/a.csv',a,fmt='%d',delimiter=',')
np.loadtxt(frame,dtype=np.float,delimiter=None,unpack=False)
- frame:文件、字符串或产生器,可以是.gz或.bz2的压缩文件
- dtype:数据类型,可选
- delimiter:分割字符串,默认是任何空格
- unpack:如果True,读入属性将分别写入不同变量
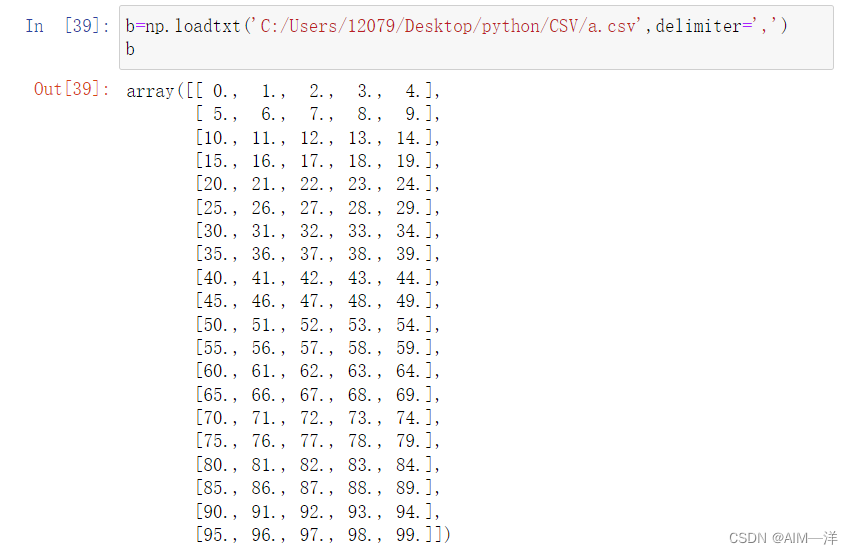
b=np.loadtxt('C:/Users/12079/Desktop/python/CSV/a.csv',delimiter=',')
b
CSV只能有效存储一维和二维数组np.savetxt() np.loadtxt()只能有效存取一维和二维数组
1.2.多维数据的存取
任意维度数据如何存取呢?
a.tofile(frame,sep=’ ‘,format=’%s’)
- frame :文件、字符串
- sep :数据分割字符串,如果是空串,写入文件为二进制
- format:写入数据的格式
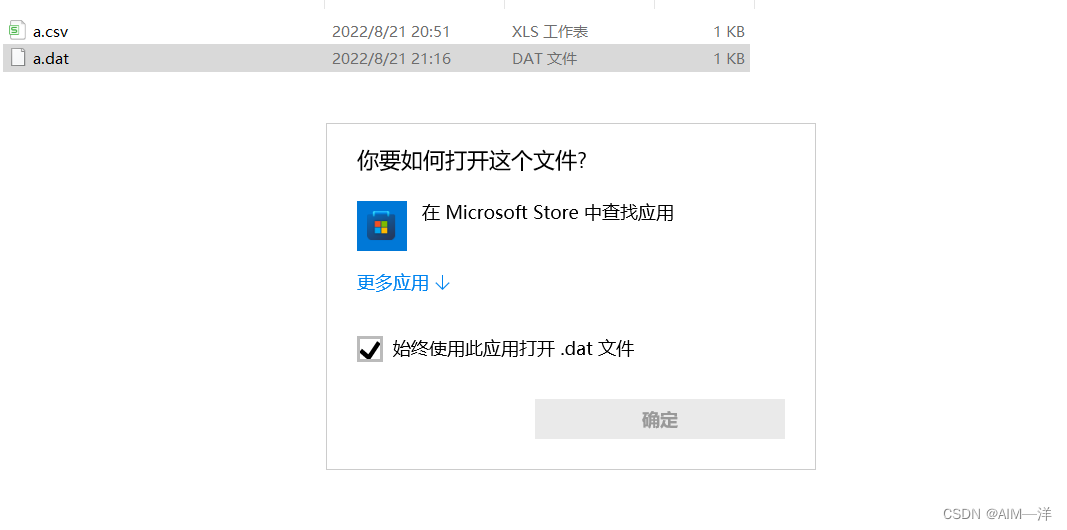
dat我打不开啊兄弟们,回头我看看怎么打开。
np.fromfile(frame,dtype=float,count=-1,sep=’ ')
- frame :文件、字符串
- dtype : 读取的数据类型
- count :读入元素个数,-1表示读入整个文件
- sep : 数据分割字符串,如果是空串,写入文件为二进制
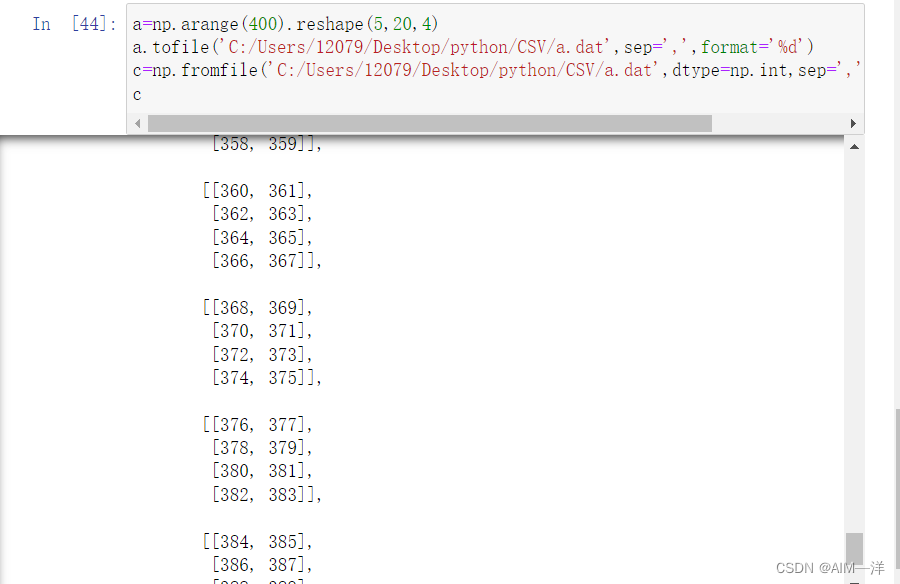
a=np.arange(400).reshape(5,20,4)
a.tofile('C:/Users/12079/Desktop/python/CSV/a.dat',sep=',',format='%d')
c=np.fromfile('C:/Users/12079/Desktop/python/CSV/a.dat',dtype=np.int,sep=',').reshape(50,4,2)
c
需要注意:该方法需要读取时知道存入文件时数组的维度和元素类型a.tofile()和np.fromfile()需要配合使用,可以通过元数据文件来存储额外信息
1.3.Numpy的便捷文件存取
np.save(fname,array) 或 np.savez(fname, array)
- fname:文件名,以.npy为扩展名,压缩扩展名为.npz
- array: 数组变量 np.load(fname)
- fname:文件名,以.npy为扩展名,压缩扩展名为.npz
1.4.Numpy的随机数函数子库
Numpy的random子库:
np.random.*
np.random.rand()
np.random.randn()
np.random.randint()
函数说明rand(d0,d1,d2…,dn)根据d0dn创建随机数数组,浮点数,[0,1],均匀分布randn(d0,d1,d2…,dn)根据d0dn创建随机数数组,标准正态分布randint(low[,high,shape)根据shape创建随机整数数组或随机整数,范围是[low,high)seed(s)随机数种子,s是给定的种子值shuffle(a)根据数组a第一轴进行随排列,改变数组xpermutation(a)根据数组a的第1轴产生一个新的乱序数组,不改变数组xchoice(a[,size,replace,p])从一堆数组a中以概率p抽取元素,形成size形状新数组replace表示是否可以重用元素,默认为Falseuniform(low,high,size)产生具有均匀分布的数组,low起始值,high结束值,size形状normal(loc,scale,size)产生具有正态分布的数组,loc均值,scale标准差,size形状poisson(lam,size)产生具有泊松分布的数组,lam随机事件发生率,size形状
1.5.Numpy的统计函数
Numpy直接提供的统计类函数
np.*
np.std()
np.var()
np.average()
函数说明sum(a,axis=None)根据给定轴axis计算数组a相关元素之和,sxis整数或元组mean(a,axis=None)根据给定轴axis计算数组a相关元素之和,axis整数或元组average(a,axis=None,weight=None)根据给定轴axis计算数组a相关元素的加权平均值std(a,axis=None)根据给定轴axis计算数组a相关元素的标准差var(a,axis=None)根据给定轴axis计算数组a相关元素的方差
axis=None 是统计函数的标配参数
1.5.Numpy的梯度函数
函数说明np.gradient(f)计算数组f中元素的梯度,当f为多维时,返回每个维度梯度
梯度:连续值之间的变化率,即斜率
xy坐标轴连续三个x坐标对应的y轴值:a,b,c其中,b的梯度是:(c-a)/2
版权归原作者 AIM—洋 所有, 如有侵权,请联系我们删除。